Jollier
Professional
- Messages
- 1,210
- Reaction score
- 1,277
- Points
- 113

As you know, Google stores a huge amount of data about its users, which it is constantly reproached. Under the pressure of criticism, Google has created a mechanism that allows you to take and pump out all your data. This service is called Takeout, and it can have various interesting uses, which we'll talk about. And at the same time, we will study in detail what he gives out to the user.
The reasons for picking up and picking up everything can be different. For example, you want to migrate to another service and transfer your data there: it is unlikely to do without conversion, but sometimes it is a justified hassle. Or maybe you want to make some kind of analytical system in the spirit of lifelogging and quantified self, and the data accumulated in Google will help you with this. Or the country in which you live suddenly decided to fence off its Internet with some great firewall, after which Google would be left behind. Alas, it also happens.
I have used Google products a lot over the past twelve years, testing many of them as part of reviews, and have never turned off the tracking mechanisms. Perhaps you will say that this is crazy, but, firstly, Google treats my data with care and has not yet given reasons for panic, and secondly, I in no way advocate such an approach. So consider that I endure this nightmare so that you don't have to!
So, to get your archives, you need to go to the window at takeout.google.com, put a checkmark in front of the services you are interested in and wait for some (tangible) time. When I requested the full archive, the link came in a day, that is, more than 24 hours later. In the letter, the Google robot cheerfully announced that the data was collected for 36 products, occupies 63.6 GB and is divided into three archives. Moreover, the main volume fell on the first two, and the third turned out to be a zipped page with a catalog of everything issued.
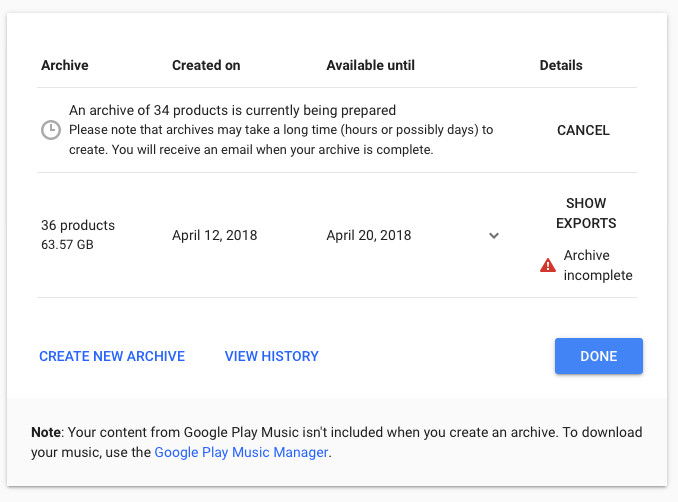
If you do not want to download such volumes, then order partial archives, which will not include all services. For example, if you turn off Photos, YouTube and Gmail, as well as Drive, if you store something besides test documents there, then you may end up with only a few hundred megabytes. By the way, the smaller the archive, the faster the download link comes.
Search
Let's start with one of the funniest things - search history. It lies in the Searches folder and is divided into files for three months, for example 2006-01-01 January 2006 to March 2006.json. If you open one of them, you will see that the information about each request consists of only two things: the time in Unix format and the desired string.To convert the time, you can use some online converter , and if you need to convert in bulk, then this is done in one line in Python (replace the word "time" with your own value):
Code:
datetime.datetime.fromtimestamp (int ("time")). strftime ('% d-% m% -% Y% H:% M:% S')But I suggest you do the detailed analysis yourself. For fun, we will try to search for occurrences of certain lines using grep. Since the data is stored in JSON, it will first need to be converted to strings - for this I used the gron utility, which I recently wrote about in the WWW heading.
If you have gron installed, you can write something like this:
Code:
$ for F in *; do cat "$ {F}" | gron | grep "carder"; doneAnd you will see all your requests with the word xakep for all the time. What other keywords can you try? Well, for example, the word "download".
Or here's an interesting idea: if you search for the @ symbol, you will find all the email addresses and Twitter accounts that you pushed through Google.
Please note that there is no search for pictures and videos, but we will still find them in the My Activity folder.
Chat rooms
Perhaps you already have a folder with old ICQ logs hidden somewhere and you would like to add to it everything that has ever been written through Google Talk and Hangouts. This is quite realistic, but, unfortunately, it is almost impossible to read the correspondence in the form in which it comes from Takeout (unlike, by the way, from the ICQ logs).All text is exported as a single JSON file, plus a pile of attached images - all of which lies in the Hangouts folder. There are no problems with pictures, but in JSON, for each written message there are about two dozen lines of metadata. But perhaps the main headache is that instead of the sender's name, this is the user ID.
Probably the simplest thing we can do is throw out all the tinsel and leave only the text. At least one can see some, albeit impersonal, conversations.
Code:
$ gron Hangouts.json | grep '.text'So at least there is a chance to catch something.
Google+
What really makes sense to back up is posts from the social network Google+, which is rapidly becoming an artifact of the past. If, of course, you've ever used it at all.The data is divided into three folders: Google+ Stream, Circles, and Pages. Let's take a look at them in order.
Circles are people 's contacts organized in circles from Google Plus. The format is vCard (VCF) with the information that people have filled in about themselves. You can, if desired, import into any address book in one fell swoop.
The Pages folder will be present if you had public pages. But there is nothing interesting there, except that the userpic and the page cover.
Also, the Profile folder should be attributed to the Google+ data. It contains JSON with a copy of all the data that you filled out about yourself on this social network. The main interesting things lie in the structures urls (links to other social media profiles) and organizations (places of work with dates). A funny detail: although my profile does not have an age specified, there is a field here "ageRange": {"min": 21}that Google seems to have determined on its own.
The most important thing you will find in the Google+ Stream folder. All your posts with comments and even individual comments are dumped here as separate HTML. You can flip through and feel nostalgic, or you can rip out, for example, only the texts of posts with a couple of lines in Python with BeautifulSoup. You will need to select elements with classes entry-title and entry-content.
Unfortunately, images from posts are not backed up automatically - they remain links to the Google server, which will not give them back without authorization. A flaw!
Cards
Another large and important category of personal data. Let's start simple - the MyMaps folder. These are the routes you created in Google Maps, one KMZ file per route.KMZ is a Google Earth format that is supported by other mapping applications as well. Well, in fact, this is a ZIP, which contains a KML file that is valid XML. If for some reason this is not suitable for your purposes, you can use the GeoConverter service and convert it, for example, to GeoJSON, which is a little easier to work with.
The Maps (your places) folder contains one file - Saved Places.json. It contains all your bookmarks from Google Maps in the form of another intricate structure. Each of the bookmarks is an array element featuresthat has a title, date added, date modified, and a link to Google Maps. But the geographic coordinates can be written in different ways: as a field geometry with an array coordinates or Location with fields Latitude and Longitude, but it is the same (to life honey did not seem) can be called, for example Geo Coordinates. In general, if you wish, it is not too difficult to take into account all these features, but it could be simpler.
Finally, the most interesting folder is Location History - a file with the entire history of your movements with a mobile phone in your pocket for all the time. This data occupies 7.5 MB for me.
The structure of the file is very simple, especially when compared to other archives. It is a huge array of structures including: Unix time, latitude, longitude, and precision. Sometimes they are added to them (probably when it was possible to determine them) the direction of movement in degrees, the height in meters and the accuracy of determining the height.
What to do with this file, except how to save it to memory? Example For, you can work out in his analysis of Python or on the R. There is also software for picking such data - Location History Visualizer Pro (costs $ 70), as well as amateur services like They Know Where You've Been (if you are not at all afraid of sharing this data with random people).

However, the Google service itself is so far out of competition here. The Timeline utility is attached to Google Maps, where the accumulated data can be viewed by day, and here, in addition to the bare data that is issued through Takeout, there is all kinds of analytics. Google, for example, identifies the names of places and establishments that you have visited, and perfectly distinguishes between vehicles (and can easily understand, for example, you traveled on a motorcycle, by car or by bicycle).
Chrome
This is an extremely interesting folder that contains all of the cloud part of Google Chrome (or maybe not all - you can never be sure!). That's what lies in it.- Bookmarks.html - content of bookmarks as a list of HTML. It will not be difficult to parse it - just grab the data from a href and divide it into sections by content h3. For many bookmarks, the time of addition is indicated in Unix format.
- Dictionary.csv - Apparently there should be spellcheck exceptions here, which I don't have.
- Extensions.json - information about installed extensions.
- SearchEngines.json - data about additional search engines. If you ever need the rules for composing search queries to different search engines, this file will come in handy. In other cases, it is unlikely.
- SyncSettings.json - Chrome settings.
- Autofill.json - in theory there should be data here to automatically fill in forms, but I only have an empty array. It looks like it's easier to pull this data out of Chrome itself if needed.
- BrowserHistory.json - To be honest, I was expecting to see a huge storehouse of personal information in this folder: no joke - a complete list of all the sites I have ever opened in Chrome! However, I was disappointed: this file lists only fourteen links that I managed to open in mobile Chrome when I downloaded it to watch it. At the same time, the desktop has an impressive list of sites and the Sync Everything checkbox is enabled. Glitch Takeout?
My activity
This is perhaps one of the most interesting folders, perhaps even more interesting than the search history. Its content provides an answer to the question of how exactly Google is tracking users. Going through the folders, you can see with your own eyes that he writes down every:- going to a site affiliated with Google Adwords;
- a book opened in Books;
- the site you visited through Chrome;
- API used (Developers folder);
- a quote opened in Finance;
- query to Goggles (search for objects in the image);
- viewing a page in the Google Play Store;
- access to help (Help folder);
- request to Image Search and follow the link;
- viewing the object on the map (Maps);
- Searching Google News and reading the article on the source site;
- search query and following the link from the results (Search folder);
- search for a product or purchase in a store (Shopping folder);
- viewing trips in Google Trips;
- video search and transition from results (Video Search);
- voice search (Voice and Audio folder);
- search query and watching videos on YouTube.
WWW
All the same information you can view and filter on the site myactivity.google.com. There you can also delete individual records and disable tracking of individual activities.At the same time, the format in which all this is unloaded leaves much to be desired. This is HTML again with not the most digestible markup and a 150K chunk of Material Design in each file. I hastily put together a Python script like this that you can drop into any of the folders and run it.
Code:
import re
text = open('MyActivity.html', 'r').read()
result = re.findall(r'body-1">(.+?)</div>', text)
for r in result:
for s in r.split('>'):
print s.split('<')[0]At the output, you will get a cleaned-up text, which you can, for example, send to grep input or continue structuring further. In general, a huge field for activity.
Other products
We will not analyze the data of four dozen products in detail, but we will briefly go over the remaining services.+1 - HTML listing pages you've ever liked on Google+. In my case, there are four random pages.
Bookmarks - the same, but for bookmarks. For some unknown reason, I only found here bookmarks from Google Maps - that is, asterisks that can be used to mark a place on the map. Format - HTML with links to Google Maps. Opening it in the editor, you can additionally pull out the time of addition and, in some cases, geo coordinates. All this data, however, is completely duplicated in the Maps (your places) folder, and in a more convenient form.
Calendar - Custom calendars from Google Calendar in the iCalendar (.ics) format, which is supported by many calendar programs (including Outlook, Thunderbird, and Apple's Calendar). So they can be imported directly.
Photos. If you actively use Photos, then this folder will contain a huge list of subdirectories - one for each day that contains at least one photo. The good news is that all photos are stored and uploaded in their original format, even if they are huge RAWs. And (which is important) even if you use the free version of Photos, where there seems to be a limitation on the quality of images. JSON with metadata is attached to each image.
YouTube. First of all, you will find here all the videos that you have ever uploaded to YouTube. Just like photographs - in their original formats. And of course, each comes with JSON with metadata attached. There are also playlists, OPML subscriptions, HTML browsing and search history (similar to what we saw in My Activity), and even comments - also in HTML.
Classic Sites are sites created using the not very popular Google Sites service (something in between narod.ru and Wikia). Once upon a time I made a couple of test sites, after which I did not touch the service for years. However, they still exist and are exported via Takeout. Cross-links work locally, but images remain on the Google server. And it's better not to look inside the pages - instead of source code, you will see mountains of optimized JS in the worst traditions of Google.
Drive - all documents from Google Drive. Text is exported as DOCX, tables - XLSX, comments - as HTML with the same names as the document. Conveniently, the file names correspond to the headers and the folder structure is also preserved.
Google Pay. Information from this service is divided into two folders. Google Pay Send - a list of transactions made through Google Pay (I have an empty CSV file) and Google Pay rewards, gift cards, offers (I have an empty PDF).
Mail is a complete archive of Gmail emails. The folder contains only one file - All mail Including Spam and Trash.mbox. Its headline speaks for itself: it's all-all mail, including spam and junk. The format is Mbox, that is, in fact, a huge text file, where all letters with headers go in a row. It is easy to import it into most mailers, but it will be much easier to connect them directly to Gmail and download only the folders you need via IMAP. Takeout will come in handy here only if you want to take everything in one fell swoop and so on in the form of an archive and save it for the future.
Google My Business - here, in my case, there is nothing interesting at all, only JSON consists of literally three lines: account number, first and last name and personal mark.
Contacts - address book from Gmail. Contacts are divided into folders by groups, plus there is an All Contacts folder, which combines (and duplicates) the contents of the rest. Inside each folder there is a vCard file and pictures from userpics. Funny effect - here the pictures are displayed in their entirety, in the form in which they were uploaded to Google. That is, if someone put their face in a circle and decided that no one will ever see the rest, then they are mistaken.
G Suite Marketplace - plugins for Google applications that you submitted to the brand store. I did not exhibit, so I have only one file - readme.
Tasks - For ten years in the depths of Google, there has been a service designed to maintain to-do lists. You can meet him, for example, in Gmail and Calendar. Here you can also find its "shipment" in the form of a rather tricky structure in JSON.
Google Play Books - when I saw that this folder contains subdirectories with the names of books, I was already delighted: have you really found a way to get copies of books purchased from Play Books? Haha. Of course not. Instead, each of the subdirectories contains HTML with the title of the book, the name of the author, the time the book was last opened, the internal Play Books ID, and a link. The use, of course, is dubious, but if there are a lot of books, then if you wish, you can pull out a list of them, taking the names and names of authors from elements with classes header and author.
There are still a few products for which there was nothing in my archive due to the fact that I have never used them. These are Blogger, Classroom, Fit, Play Music, Groups, Handsfree, Hangouts on Air, Keep, Search Contributions and Voice. Perhaps the biggest omission is Keep, but in this repository you can find a ready-made parser for its data.
Conclusions
It turns out that the most important archives, besides mail, photos and documents, are Searches, Location History, BrowserHistory.json from the Chrome folder and My Activity.In the end, is it possible to say that all personal data is issued through Takeout? Unlikely. There are at least no old services that are no longer supported: there is no Google Reader data, no waves from Wave. Knowing Google, I can hardly believe that all this data has been destroyed. Rather, they were removed to cold storage.
You can find other spaces in the Takeout unloading if desired. I have already mentioned the lack of data from desktop Chrome, but there are also less obvious things. For example, a page for online viewing of activities contains not only search queries, but also a link to the place from where you made them. There is nothing similar in the My Activity folder yet.
However, despite all these shortcomings, Google employees should say thank you: rarely do service developers spend so much effort on improving the portability of data and increasing the transparency of its collection. As a result, Takeout is useful not only for picking up your belongings and hiding with them, but also for a wide variety of analytics.