Carder
Professional
- Messages
- 2,616
- Reaction score
- 1,940
- Points
- 113
Every step on the Internet leaves a mark. Over the years, a long trail of personal data is collected. They are available to outsiders, who will probably try to get the most out of your information.
As the recent leak of data on all Citymobil machines showed, people are effectively tracked even on anonymized data sets. If you combine several anonymous databases with each other, you can reliably establish the identity of a particular person.

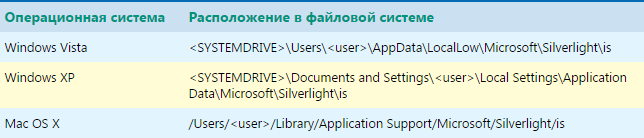
Google's advanced data collection and Analytics system
Google's data collection and Analytics system is considered one of the most advanced in the world. Google's video, mail, and map services have more than 1 billion users (each of them). The company uses the ubiquity of its products to track user behavior online and in real life, and then target them with paid ads. Google's revenue directly depends on the accuracy of targeting and the breadth of data collected.
Experts from the organization Digital Content Next and Vanderbilt University published the results of the Google Data Collection study with some facts that speak about the total surveillance of people by Google:

Google and other services expect that you will not delete old messages that will remain in their possession almost forever. If you really need this multi-year archive, then you can keep it. Otherwise, it is better to delete the old messages. This will free up storage space and speed up the search in the archive, plus compliance with the rules of digital hygiene.
The specific procedure for clearing the archive depends on the client and the service. In the case of Gmail, there is no automatic way to erase old emails, so you need to regularly perform such cleaning manually. This is done by using a search query older_than: that specifies the desired time period. For example, the query older_than:1y outputs all emails older than a year, and older_than:6m all emails older than 6 months.
When you get the search results on the screen, you can select all messages (check the box in the upper-left corner - and delete them.
To avoid deleting everything, you can combine the query with other search terms. For example, the request
Dsplays all emails older than one year that Gmail has marked as "low priority". For the full list of Gmail search operators, see here.
Other email clients may not have advanced search operators like Gmail, so it's harder to select and delete messages. But in any case, the function of sorting emails by date must be present to see the oldest messages in the archive.
For maximum security on the Internet, it is better to store the archive of messages not on the server, but on a personal computer locally. This allows any local mail client like the Bat!, which downloads and immediately deletes all emails from the mail server, so that they are not stored there at all.:

Automatically delete all received emails from the Gmail mail server in the Bat mail client!
In some social networks, you can even download and save an archive of your messages just in case — and store it in an encrypted personal storage. And then remove it from public access.
To download an archive of your Twitter messages, go toSettings → Your account → Download the archive of your data.
The two best tools for automatic deletion are TweetDelete and Tweet Deleter, which not only have similar names, but also the principle of operation. They automatically delete tweets as soon as the specified time limit passes after they are posted. Tweet Deleter gives you a little more control over which tweets to delete, but TweetDelete has more features available for free.
You can delete tweets once, or run them permanently as a daemon in Linux (for example, cleaning the archive of outdated tweets once a week).

You can mention the Jumbo program (Android and iOS versions), which deletes old messages on Twitter and Facebook as soon as they reach a certain age, saving them inside the app in local storage. This is definitely an easy-to-use option for hiding your social media footprints. Certain functionality for Facebook and Twitter is included in the free Jumbo account, so you don't have to buy the paid version.
Facebook, Instagram, and Vkontakte don't have specific functions for quickly deleting all old messages directly in the social networks, so you'll have to use third-party tools like Jumbo or delete messages manually one at a time. Or Facebook Instagram stories can be published initially and automatically disappear after 24 hours.
But for the sake of digital hygiene, it is better to reduce the use of social networks to the most necessary minimum, and transfer communication to instant messengers with end-to-end encryption. They store your private messages only in a securely encrypted form, or they don't store them at all (depending on the messenger).
In Dropbox, you can click next to the column header and select the "modified date" sorting option to see the oldest files that you haven't edited in a long time. This applies to files only in a specific folder. If there are folders with temporary and less important files, you can quickly view and delete the oldest files by sorting them by date of modification.
On Google Drive, enable list view and click on the "Last modified" column header. The up and down arrows switch between viewing the latest or oldest changes.
Google Drive also uses search queries like before: 2011-01-01 in the main search box of Google Drive to find files that were last modified before a certain date. Use Ctrl+Click to select several files on your Google Drive - and the trash icon to delete them.
OneDrive and iCloud also have similar options with sorting by last modified date. These manual operations are not as convenient as automatic tools, but even if you just run them once every couple of months, you can delete a lot of files that are no longer needed.
Companies like Apple and Microsoft aren't actually required to have such advanced tools as Google, because they simply don't collect such huge amounts of information about users for ad targeting.
Log in to your Google account, where the "Privacy and personalization" button displays a page with information about what data Google collects about your online activity, search history, and location - both to personalize your work with apps and for targeted advertising. In all categories, you can choose the option of automatic deletion after 3, 18, or 36 months.
Individual pieces of data can be viewed (and deleted) from the main activity dashboard. For example, here you can erase the record of everything you said to your smart speaker over the past week.
Apart from Google, only one company collects data on such a gigantic scale — this is Facebook. Go to "General account settings", there is a section "Your Facebook information". You can view and delete some of this data, though without sorting by date.
In Russia, Yandex and Vkontakte can be added to the list of dangerous services that organize total surveillance of users, but they introduce specific Russian risks associated with compliance with local legislation, so it is more risky to use them in this sense than foreign ones. For example, in Russia, there were cases when users were prosecuted for reposts on The Vkontakte social network (Mail.ru), which actively shares user information with law enforcement agencies, and earlier Mail.ru it transmitted data even in circumvention of the procedures established by law.
As the recent leak of data on all Citymobil machines showed, people are effectively tracked even on anonymized data sets. If you combine several anonymous databases with each other, you can reliably establish the identity of a particular person.
This is difficult to deal with, but it is possible. For example, we will try to delete data sets that have accumulated in various Internet services. Let's clean up your Internet history in full.
Total surveillance
Google's advanced data collection and Analytics system
Google's data collection and Analytics system is considered one of the most advanced in the world. Google's video, mail, and map services have more than 1 billion users (each of them). The company uses the ubiquity of its products to track user behavior online and in real life, and then target them with paid ads. Google's revenue directly depends on the accuracy of targeting and the breadth of data collected.
Experts from the organization Digital Content Next and Vanderbilt University published the results of the Google Data Collection study with some facts that speak about the total surveillance of people by Google:
- An Android smartphone with the active Chrome browser in the background transmits location information to Google 340 times over a 24-hour period, which means an average of 14 data transfers per hour. In fact, location information accounts for 35% of all sample data sent to Google.
- Google may associate anonymous data collected by passive means with the user's personal information. Google establishes this connection mainly through advertising systems, many of which it controls. Advertising IDS that correspond to "anonymous users" collect data about activity in applications and visits to third-party web pages. They can be linked to real Google users by transmitting identification information to Google servers at the Android device level.
- The Doubleclick cookie, which tracks user activity on third-party web pages - is another example of an "anonymous" identifier that Google can associate with a Google account. A link is established if the user accesses the Google app in the same browser that previously opened the third-party web page.
- Most of Google's data collection takes place at a time when the user is not interacting directly with any of Google's products. The scale of the collection is very significant. At the same time, the Android smartphone is probably the most popular personal gadget in the world. It is carried around the clock by 2 billion people.
Nowadays, many people are outraged by social networks, including Facebook, where people voluntarily upload huge amounts of private information, including personal photos and personal correspondence in unencrypted form. But in reality, Google has no less opportunities for total surveillance.
One day in the life of a typical Google user
Here's how Google tracks people's activity across the various services of its Internet Empire (from the Google Data Collection report):
Deleting a digital history
So how do we deal with the invisible enemy that is sucking our data from thousands of sources? If not websites, then pharmaceuticals. If not data about the location of the card in the shops. If you don't like, then Bank account and Bank statement calculations. Our data is everywhere. Welcome to the age of privacy nihilism. Researchers claim that it is almost impossible to hide from Google's surveillance. But we'll try.Mail
Nowadays, email services offer a large amount of cloud storage-completely free of charge. Of course, they do this for a reason, but to accumulate as much user data as possible for data mining, analysis, and profiling. In the end, this allows you to use the service's audience more effectively as an advertising audience, which generates the main profit of Internet companies.Google and other services expect that you will not delete old messages that will remain in their possession almost forever. If you really need this multi-year archive, then you can keep it. Otherwise, it is better to delete the old messages. This will free up storage space and speed up the search in the archive, plus compliance with the rules of digital hygiene.
The specific procedure for clearing the archive depends on the client and the service. In the case of Gmail, there is no automatic way to erase old emails, so you need to regularly perform such cleaning manually. This is done by using a search query older_than: that specifies the desired time period. For example, the query older_than:1y outputs all emails older than a year, and older_than:6m all emails older than 6 months.
When you get the search results on the screen, you can select all messages (check the box in the upper-left corner - and delete them.
To avoid deleting everything, you can combine the query with other search terms. For example, the request
Code:
older_than:1y is:importantDsplays all emails older than one year that Gmail has marked as "low priority". For the full list of Gmail search operators, see here.
Other email clients may not have advanced search operators like Gmail, so it's harder to select and delete messages. But in any case, the function of sorting emails by date must be present to see the oldest messages in the archive.
For maximum security on the Internet, it is better to store the archive of messages not on the server, but on a personal computer locally. This allows any local mail client like the Bat!, which downloads and immediately deletes all emails from the mail server, so that they are not stored there at all.:
Automatically delete all received emails from the Gmail mail server in the Bat mail client!
Social media
Which social networks do you write the most messages on? This can be Facebook, Vkontakte, or Twitter. In any case, it makes no sense to archive old messages that are unlikely to be useful for you, but can (and will) be used against you for sure.In some social networks, you can even download and save an archive of your messages just in case — and store it in an encrypted personal storage. And then remove it from public access.
To download an archive of your Twitter messages, go toSettings → Your account → Download the archive of your data.
Then we start deleting old records.
The two best tools for automatic deletion are TweetDelete and Tweet Deleter, which not only have similar names, but also the principle of operation. They automatically delete tweets as soon as the specified time limit passes after they are posted. Tweet Deleter gives you a little more control over which tweets to delete, but TweetDelete has more features available for free.
You can delete tweets once, or run them permanently as a daemon in Linux (for example, cleaning the archive of outdated tweets once a week).
You can mention the Jumbo program (Android and iOS versions), which deletes old messages on Twitter and Facebook as soon as they reach a certain age, saving them inside the app in local storage. This is definitely an easy-to-use option for hiding your social media footprints. Certain functionality for Facebook and Twitter is included in the free Jumbo account, so you don't have to buy the paid version.
Facebook, Instagram, and Vkontakte don't have specific functions for quickly deleting all old messages directly in the social networks, so you'll have to use third-party tools like Jumbo or delete messages manually one at a time. Or Facebook Instagram stories can be published initially and automatically disappear after 24 hours.
But for the sake of digital hygiene, it is better to reduce the use of social networks to the most necessary minimum, and transfer communication to instant messengers with end-to-end encryption. They store your private messages only in a securely encrypted form, or they don't store them at all (depending on the messenger).
Files
Deleting old files in the cloud is not so much about protecting against information leaks or some kind of espionage, but rather maintaining order and saving money when using paid cloud storage. Such actions cause direct losses to the cloud service. Therefore, it is not surprising that some services do not have a standard function for automatically deleting old (or unnecessary) files. Although there are a few tricks you can try.In Dropbox, you can click next to the column header and select the "modified date" sorting option to see the oldest files that you haven't edited in a long time. This applies to files only in a specific folder. If there are folders with temporary and less important files, you can quickly view and delete the oldest files by sorting them by date of modification.
On Google Drive, enable list view and click on the "Last modified" column header. The up and down arrows switch between viewing the latest or oldest changes.
Google Drive also uses search queries like before: 2011-01-01 in the main search box of Google Drive to find files that were last modified before a certain date. Use Ctrl+Click to select several files on your Google Drive - and the trash icon to delete them.
OneDrive and iCloud also have similar options with sorting by last modified date. These manual operations are not as convenient as automatic tools, but even if you just run them once every couple of months, you can delete a lot of files that are no longer needed.
Online activity
When it comes to automatically collecting your personal data that the Internet company has collected about you while browsing the web, Google offers the most advanced options. Although it is fair to say that it also leads directly in collecting this data…Companies like Apple and Microsoft aren't actually required to have such advanced tools as Google, because they simply don't collect such huge amounts of information about users for ad targeting.
Log in to your Google account, where the "Privacy and personalization" button displays a page with information about what data Google collects about your online activity, search history, and location - both to personalize your work with apps and for targeted advertising. In all categories, you can choose the option of automatic deletion after 3, 18, or 36 months.
Individual pieces of data can be viewed (and deleted) from the main activity dashboard. For example, here you can erase the record of everything you said to your smart speaker over the past week.
Apart from Google, only one company collects data on such a gigantic scale — this is Facebook. Go to "General account settings", there is a section "Your Facebook information". You can view and delete some of this data, though without sorting by date.
In Russia, Yandex and Vkontakte can be added to the list of dangerous services that organize total surveillance of users, but they introduce specific Russian risks associated with compliance with local legislation, so it is more risky to use them in this sense than foreign ones. For example, in Russia, there were cases when users were prosecuted for reposts on The Vkontakte social network (Mail.ru), which actively shares user information with law enforcement agencies, and earlier Mail.ru it transmitted data even in circumvention of the procedures established by law.
The person did not delete their digital history — and it was available to investigators. As a result, a criminal case for extremism.