
Brother
Professional
- Messages
- 2,590
- Reaction score
- 541
- Points
- 113
Alibaba's new technology can be used to create deceptive videos.
Researchers from the Alibaba Group Institute for Intelligent Computing have developed a new video generation technology called "Animate Anyone". This breakthrough significantly exceeds previous image-to-video conversion systems, such as DisCo and DreamPose, which were relevant back in the summer, but are now outdated.
Animate Anyone allows you to create compelling videos from static images, moving from "imperfect academic experiments" to a quality that is sufficient to deceive the eye. This quality has already been achieved in the field of static images and text dialogs, causing disruptions in our perception of reality.
The model starts by extracting details such as facial features, patterns, and poses from the original image, such as a photo of a model in a dress. Then a series of images are created where these details are superimposed on slightly altered poses that can be captured in motion or extracted from another video.
Early models showed the possibility of this approach, but there were problems such as" hallucinations " - the need for the model to invent plausible details, such as how the sleeve or hair moves when a person turns. This led to the creation of strange images, making the video incomplete. However, "Animate Anyone" significantly improved this process, although it did not reach perfection.
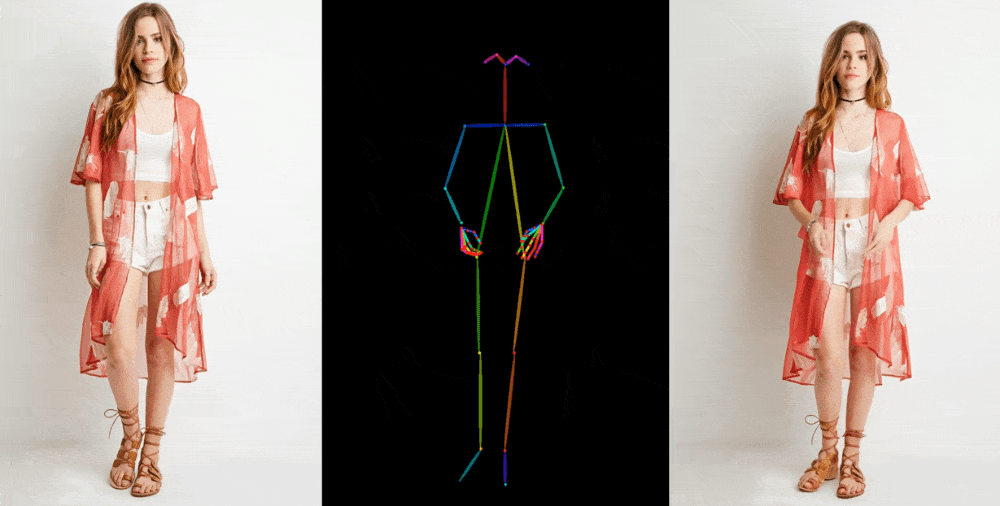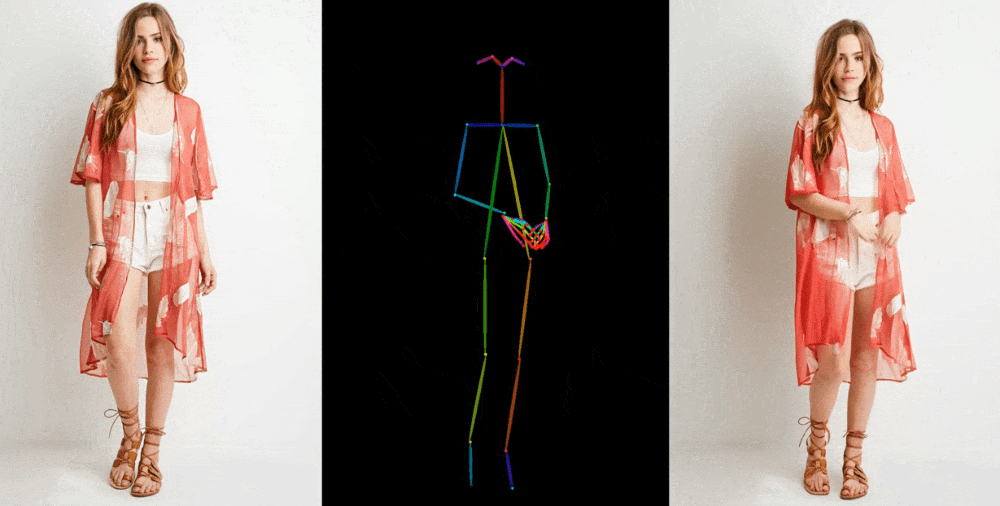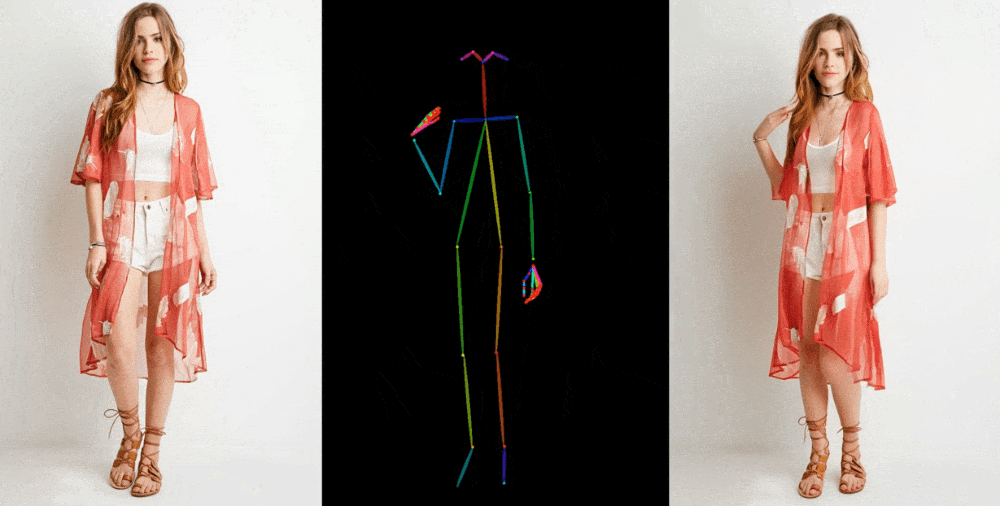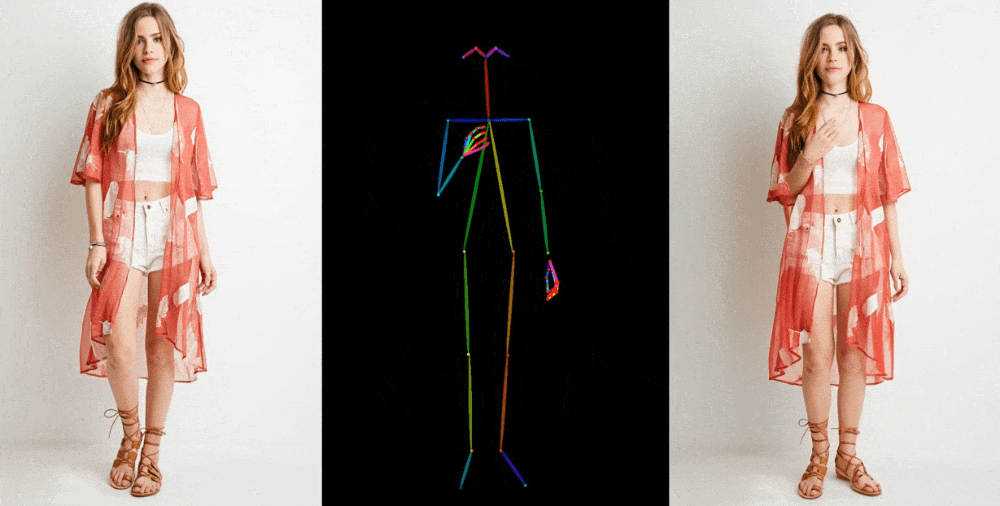
The technical details of the new model are difficult to understand, but it is important to note the new intermediate stage, which "allows the model to comprehensively study the relationship with the original image in a single space of characteristics, which significantly improves the preservation of appearance details." Improved retention of basic and fine details allows you to create better images.
The results are shown in a variety of contexts: models in fashionable clothing assume arbitrary poses without deformity; 2D anime characters come to life and dance convincingly; Lionel Messi performs several general movements. However, the model still has difficulties, especially with the eyes and hands, as well as with poses that are very different from the original.
This technology is worrisome, as it can be used by attackers to force a person to do anything on a video using just one high-quality image. At the moment, the technology is too complex and unstable for widespread use, but things are changing rapidly in the AI world.
The development team does not plan to publish the code in the public domain yet. Their GitHub page indicates that they are actively working on preparing the demo and code for public access, but a specific release date has not yet been set.
The question remains: what happens when the internet fills up with fake videos? We'll probably know the answer sooner than we'd like.
Researchers from the Alibaba Group Institute for Intelligent Computing have developed a new video generation technology called "Animate Anyone". This breakthrough significantly exceeds previous image-to-video conversion systems, such as DisCo and DreamPose, which were relevant back in the summer, but are now outdated.
Animate Anyone allows you to create compelling videos from static images, moving from "imperfect academic experiments" to a quality that is sufficient to deceive the eye. This quality has already been achieved in the field of static images and text dialogs, causing disruptions in our perception of reality.
The model starts by extracting details such as facial features, patterns, and poses from the original image, such as a photo of a model in a dress. Then a series of images are created where these details are superimposed on slightly altered poses that can be captured in motion or extracted from another video.
Early models showed the possibility of this approach, but there were problems such as" hallucinations " - the need for the model to invent plausible details, such as how the sleeve or hair moves when a person turns. This led to the creation of strange images, making the video incomplete. However, "Animate Anyone" significantly improved this process, although it did not reach perfection.
The technical details of the new model are difficult to understand, but it is important to note the new intermediate stage, which "allows the model to comprehensively study the relationship with the original image in a single space of characteristics, which significantly improves the preservation of appearance details." Improved retention of basic and fine details allows you to create better images.
The results are shown in a variety of contexts: models in fashionable clothing assume arbitrary poses without deformity; 2D anime characters come to life and dance convincingly; Lionel Messi performs several general movements. However, the model still has difficulties, especially with the eyes and hands, as well as with poses that are very different from the original.
This technology is worrisome, as it can be used by attackers to force a person to do anything on a video using just one high-quality image. At the moment, the technology is too complex and unstable for widespread use, but things are changing rapidly in the AI world.
The development team does not plan to publish the code in the public domain yet. Their GitHub page indicates that they are actively working on preparing the demo and code for public access, but a specific release date has not yet been set.
The question remains: what happens when the internet fills up with fake videos? We'll probably know the answer sooner than we'd like.