Tomcat
Professional
- Messages
- 2,689
- Reaction score
- 981
- Points
- 113
What is Browser Fingerprint? Or browser identification. A very simple formulation is to assign an identifier to the browser. The wording is simple, but the idea is very complex and interesting. What is it used for? Why do we want to assign an ID to the browser?
Why not just use http cookies for this purpose? It’s very simple, and everyone knows how to do it. It works, you all know how.
A user comes to your site, we read his cookie, if there is some kind of identifier there, then we already had it and we know who he is. We do all our analytics, tracking, etc. associated with this user.
If there is no identifier there, it means that the user came to us for the first time. We generate a unique identifier, GUI, some kind of binary string, write it in a cookie, and then, when the user comes next time, we will read this cookie and understand that this user came to us for the second, third and subsequent times.
Cookies have one big drawback - they can be cleared. Anyone, even a non-technical user, knows how to clear cookies. He clicks Settings, goes in and clears it. That’s it, the user becomes anonymous to you again, you don’t know who he is.
All modern browsers, even Internet Explorer, seem to offer an incognito mode. This is a mode where nothing is saved, and when a user visited your site in this mode, it does not leave any trace. The next time he logs in in incognito mode, you again won’t know who he is or whether you had him before. Those. http cookies will not work in incognito mode.
Currently, due to the popularity of characters such as Snowden, etc. many people prefer different privacy modes, online anonymity, modes, plugins, whatever. All this prevents tracking and identification on the Internet. Many users use this without even understanding why. They just install it simply because it’s fashionable. And they again become anonymous to you. Http cookies will not work in this case.
How have programmers tried and are trying to solve this problem?
The most successful project in the field of storing information in cookies so that it cannot be deleted, in my opinion, is the evercookie project, or persistent cookie - an undeletable cookie, a difficult-to-delete cookie. Its essence lies in the fact that evercookie does not just store information in one storage, such as an http cookie, it uses all available storage in modern browsers. And stores your information, for example, ID. It starts using http cookies, writes the identifier there, then, if Flash is available in the browser, it uses local shared objects to write information to the so-called. Flash cookies.

Flash cookies until recently were not cleared when you cleared your cookies. Only the latest versions of Google Chrome can clear Flash cookies when you clear regular cookies. Those. Until recently, Flash cookies were virtually undeletable. There was a special page on the macromedia website where you had to go, click the button: “Yes, I want to clear Flash cookies,” and then they are cleared, i.e. Without this page it was impossible to clean up.

Next, evercookie uses Silverlight Cookies. They are otherwise called Isolated Storage. This is a special allocated space on the user’s computer’s hard drive where cookie information is written. It is impossible to find this place unless you know the exact path. It is hidden somewhere in documents, Settings, if on Windows, deep in the bowels of the computer. And this data cannot be deleted by clearing cookies.

Further. Evercookie uses such innovative technology as PNG Cookies. The bottom line is that the browser returns an image in which the bytes of this image encode the information that you have saved, for example, an identifier. This image is served with a caching directive forever, say, for the next 50 years. The browser caches this image, and then the next time the user visits, the Canvas API reads the bytes from this image and restores the information that you wanted to save in the cookie. That. Even if the user has cleared the cookie, that PNG cookie-encoded image will still be in the browser's cache and the Canvas API can read it on a subsequent visit.

Evercookie uses all available browser storage - modern HTML 5 standard, Session Storage, Local Storage, Indexed DB and others.

The ETag header is also used - this is an http header, very short, but you can encode some information in it, and if Java is installed, then the java presistence API is used.

Evercookie is a very smart plugin that can save your data almost anywhere. For an ordinary user who does not know all this, it is simply impossible to delete these cookies. You need to visit 6-8 places on your hard drive and perform a series of manipulations just to clean them. Therefore, the average user, when visiting a site that uses evercookie, will most likely not be anonymous.
Despite all this, evercookie does not work in incognito mode. Once you enter incognito mode, no data is saved to disk, because that is the fundamental essence of incognito mode - you must be anonymous. And evercookie uses hard drive storage, which does not work in this mode.
FingerprintJS is a little library I wrote that tries to solve these problems. I'll tell you how she does it and what came of it.
I wrote it in 2012. I then worked at KupiKupon as a Ruby developer. And I had the task of creating an analytics system that would take into account not just logged-in users, i.e. those users who are in our system, as well as anonymous users. Specifically, on the “KupiKupon” site there were many anonymous users, because people often came from outside to look at some coupons, discounts, offers, they did not have an account, and therefore the tracking system, the system for tracking visited pages, clicks on buttons - none of this worked because the users were anonymous.
FingerprintJS doesn't use cookies at all. No information is saved on the hard drive of the computer where the browser is installed. It works in incognito mode because it basically does not use hard drive storage. It has no dependencies, works even without jQuery, and is 1.2 KB gzipped.

Currently used in companies such as Baidu, Google in China, MasterCard, the website of the US President, AddThis - a site for hosting widgets, etc.
This library quickly became very popular. It is used by approximately 6-7% of all the most visited sites on the Internet at the moment.

I’ll tell you in detail how it works. Its essence is that the code of this library queries the user’s browser for all the specific and unique settings and data for this browser and for this system, for the computer. This data is concatenated into a huge string, then it is fed into the hashing function. The hashing function takes this data and turns it into compact, beautiful identifiers. I'll tell you in detail how this works.
First the userAgent navigator is read. Let's say it's cut off here, it's appended to the final line of the print.

The browser language is read - what is your language - English, Russian, Portuguese, etc. Also attached to the fingerprint line.
The time zone is read, this is the number of minutes from UTC:

–180.
This is -3, which turns out to be Moscow.

Next we get the screen size, array, screen color depth.

Then all supported HTML5 technologies are retrieved, i.e. Each browser has different support. FingerprintJS tries to determine which are supported and which are not, and for each technology, the result of a poll for the presence of that technology and the degree of its support is added to the resulting fingerprint function.

SessionStorage, LocalStorage, IndexedDB, OpenDatabase and all kinds of others.
User-specific and platform-specific data is queried, such as the doNotTrack setting (it’s very ironic that the doNotTrack setting is used specifically for tracking), cpuClass of the processor, platform and other data.

Here you may have a natural question - after all, many users have the same data? Let's say the user lives in Moscow, he will have the same language, the latest Chrome, he will have everything almost the same, and all these strings that were received at this stage will be the same. How will this help identify the user?
There are 2 more ways that add uniqueness.


The question that arises here is: how does this also help in identification? What was unexpected for me was the research I found. It suggests that font rendering, in particular in the Canvas API, is very platform dependent. Externally identical identical images drawn in different browsers will be converted to a different byte array. Why? This depends on the processor, video card, video card drivers, system libraries such as direct X, font rendering systems, shadows - all of this can be different on each computer, so the resulting byte array will be different on almost every computer, which will have different hardware and software filling. And this long string obtained during Canvas serialization will be attached to the final print, and we will get a huge string.
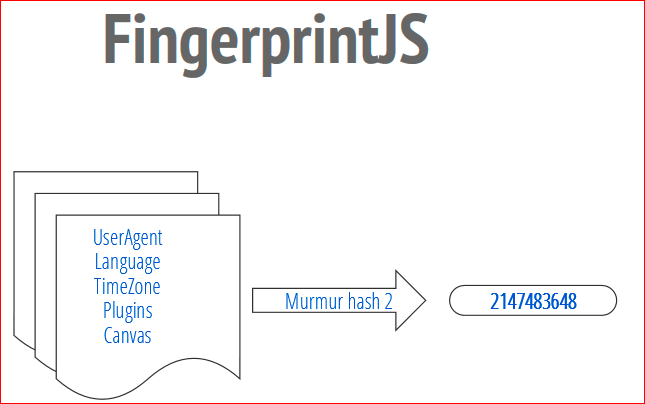
Here's how it works. We receive all this data. Then we pass them to the hashing function, FingerprintJS uses nomo hash2, and the output is a 32-bit number. This is your ID. Thus, when a user visits our website, he is assigned a number. You read this number and use it as you wish - you base your analytics on it, etc.
The question here is: how unique and accurate is the definition? The study it was based on was done by the Electronic Frontier Foundation, they had a project called Panopticlick. It says that the uniqueness is about 94%, but in the real data that I had, the uniqueness was about 90%-91%.
The library began to be used by many people and companies, and over time a number of shortcomings emerged. Those. she is not perfect, she has flaws. The main disadvantage is that the identification accuracy is only 90%, but there are other disadvantages.

Therefore, after analyzing all this, and now I also use FingerprintJS, I came to the conclusion that it is time to develop a new library that will be practically devoid of all existing shortcomings.
I started making it quite recently, development is underway on github.

How does it solve existing problems? The most important thing is that phase hashing or localsensitivehash, or fuzzy hashing is used. The kind of hashing that doesn't change, even though in normal hashing, if you change even one byte of the input information, the output string will also change, and in a dramatic way. This does not happen in phase hashing; there is a sensitivity threshold where a certain percentage of the incoming data can change without affecting the outgoing fingerprint. Let's say that if only the browser version has changed in UserAgent, this happens very often, for example, in Chrome, then the resulting fingerprint will be the same, because the version is 3 or 5% of the total length from UserAgent.
Second, FingerprintJS 2 uses the definition of installed fonts, all fonts that are installed on the system. How is this useful? If you installed a program, say Adobe pdf, then you add fonts to the system.
If you installed Microsoft Office, you add fonts to the system; if you installed some Quick office that has its own fonts, you again add fonts to the system. And so you can have two absolutely identical computers, but one has Office installed and the other does not. This means that on the first one, where there is no Office, there will be 320 available fonts, and on the one where there is Office - 1700 fonts. And that means that you can get all the fonts that are on this computer, again, for the final print. These will be two different prints because the fonts are different.
The default is Flash, a small swf file of 916 bytes. It receives a list of all installed fonts, and in platform-dependent order, because they are available in the system, so they will be returned. If Flash is not installed, this technique is used, it is called site chanel technic. It was first published on lalit.org. This is detecting the presence of a font using javascript only. How it's done? For each reference font that is set by default in the browser or system, its width and height are measured and this array of width and height is stored. Then a different font is applied to the hidden text (the text, by the way, is huge, say 72 pixels). If this font is in the system, the text will change its dimensions correctly, and the code that changes the height and width will receive a new array with height and width. If it differs from the reference one, from the one that was received when requesting the default font, then this font is installed. If it is not different, then this font does not exist.
A very simple idea, but it works. Currently, this code can reliably identify about 500 fonts without using Flash. And, accordingly, the computer that has Microsoft Office and the one that doesn’t will be identified differently in FingerprintJS 2 due to this technique.

The third difference is WebGL Fingerprint. This is a development of the Canvas Fingerprint idea. Its essence is that 3D triangles are drawn (it’s not very visible on the slide, but it’s 3D). Effects, gradients, various anisotropic filtering, etc. are applied to it. And then it is converted to a byte array. The resulting byte array, as with Canvas Fingerprint, will be different on many computers. Then information about platform-dependent constants that are defined in WebGL is added to this byte array. Those. WebGL has a set of constants that must be included in the implementation. This is the color depth, the maximum size of textures... There are a lot of these constants, dozens of them. The code interrogates all these constants and, of course, on Android devices these constants will be different; there the color depth may be different than on Windows or Linux. It polls all these constants, it all adds up again into a huge array, and it all gets added to a serialized 3D triangle image that is drawn using hardware effects.
There is also a question here: how does this help to identify? 3D graphics are very platform-dependent, the version of drivers, the version of the video card, the OpenGL standard in the system, the version of the shader language - all this will affect how this image will be drawn inside. And when it is converted to a byte array, it will be different on many computers.
Why is WebGl Fingerprint important? Because IOS 8.1 supports WebGL, and this helps to identify IOS devices, the identification problem of which I mentioned. Therefore, WebGL improves the accuracy of Fingerprint.
What else remains to be implemented?
As I said, the library is under development and not all the things I would like to do in it have been done. There is already a small community of developers around it. By the way, I invite everyone to participate in the development - it is very interesting, we are very informal, everyone offers ideas, it is quite interesting.
What remains to be implemented? WebRTC Fingerprinting.
WebRTC is a standard for peer-to-peer communications over audio streams, or it is a standard for audio communications in modern browsers. It allows you to make audio calls etc., it is supported in FireFox and will be supported in other browsers soon.
The implementation of the WebRTC standard is also platform-dependent; it will depend on the video card that is installed in the system, on sound drivers, etc. Therefore, by measuring different levels of latency, different levels of WebRTC support and constants that are hardcoded in this format, you can get different final fingerprints for different computers.
More IE plugins will be used. Those plugins that are popular in different countries will be used - China, India, etc., i.e. growing information markets. The first version did not pay enough attention to this problem, but this will be resolved in the second version.
More information will be collected about the OS. How will we do this? Integration with Flash and Silverlight will be used. Flash allows you to get information about the system, such as kernel version, kernel level patch. Silverlight, if on Windows, allows you to get the Windows version, bild, Windows number, all this is available through Silverlight.
A few words about Silverlight, why integration with sliverlight is also quite important? Maybe in Russia the Silverlight plugin is not very popular, but in the USA, for example, there is a video streaming service Netflix that broadcasts video, and I know for sure that they use Silverlight. Due to the fact that it supports DRM (this is a system for restricting digital rights to content), because... Netflix often shows various new Hollywood films, they use Silverlight to ensure that this video does not go viral on the Internet. Therefore, in the USA, many desktop Internet users have the Silverlight plugin installed, which, by the way, is available on Mac too, in addition to Windows.
Detection of multiple monitors will be implemented. If we request the dimensions via javascript, we will simply get two numbers - this is the width and height of the screen. If we do the same via Flash API, Actionscript API, we will get an array of arrays. This means that if several monitors are installed, where each subarray is the screen size of each monitor. If the developer is sitting at five monitors, he will receive an array of arrays of five elements, so we know that the person is sitting at five monitors, and not at the main monitor, which javascript would return.
All these data together allow us to currently obtain a determination accuracy of about 94-95%. But, as you understand, this is insufficient identification accuracy. This raises the question: how can this be improved, and can it be improved? I think it is possible. The goal of this project is to achieve 100% identification so that you can rely on Fingerprint in 100% of cases and be guaranteed to say: “Yes, this user came to us; yes, I know everything about him, despite the fact that he uses incognito mode, tor network...” It doesn't matter, it will all be determined.
- We want to take our users into account. We want to know whether the user came to us for the first time, whether he came for the second time or the third time. If the user came for the second time, we want to know what pages he visited and what he did before. This is not possible with anonymous users. If you have a record keeping system, a user logs in, we know everything about him - we know his account, his personal data, we can link any actions to this user. Everything is simple here. In the case of anonymous users, things become much more complicated.
- The second scenario is personal advertising. It's everywhere now. We walk in and suddenly they show us an advertisement for some pies that we wanted to buy yesterday. How it's done? This is done through user identification.
- The third scenario is internal analytics. If you use, in addition to Google Analytics or Yandex, your own custom analytics system, Fingerprint JS and Browser Fingerprint, in general, can help you achieve almost complete identification of anonymous users. You will be able to see what the user did on your site, what pages they visited, what links they clicked, etc. And build a whole picture based on this, a map of user actions. All this is achieved using this technique - Browser Fingerprinting.
Why not just use http cookies for this purpose? It’s very simple, and everyone knows how to do it. It works, you all know how.
A user comes to your site, we read his cookie, if there is some kind of identifier there, then we already had it and we know who he is. We do all our analytics, tracking, etc. associated with this user.
If there is no identifier there, it means that the user came to us for the first time. We generate a unique identifier, GUI, some kind of binary string, write it in a cookie, and then, when the user comes next time, we will read this cookie and understand that this user came to us for the second, third and subsequent times.
Cookies have one big drawback - they can be cleared. Anyone, even a non-technical user, knows how to clear cookies. He clicks Settings, goes in and clears it. That’s it, the user becomes anonymous to you again, you don’t know who he is.
All modern browsers, even Internet Explorer, seem to offer an incognito mode. This is a mode where nothing is saved, and when a user visited your site in this mode, it does not leave any trace. The next time he logs in in incognito mode, you again won’t know who he is or whether you had him before. Those. http cookies will not work in incognito mode.
Currently, due to the popularity of characters such as Snowden, etc. many people prefer different privacy modes, online anonymity, modes, plugins, whatever. All this prevents tracking and identification on the Internet. Many users use this without even understanding why. They just install it simply because it’s fashionable. And they again become anonymous to you. Http cookies will not work in this case.
How have programmers tried and are trying to solve this problem?
The most successful project in the field of storing information in cookies so that it cannot be deleted, in my opinion, is the evercookie project, or persistent cookie - an undeletable cookie, a difficult-to-delete cookie. Its essence lies in the fact that evercookie does not just store information in one storage, such as an http cookie, it uses all available storage in modern browsers. And stores your information, for example, ID. It starts using http cookies, writes the identifier there, then, if Flash is available in the browser, it uses local shared objects to write information to the so-called. Flash cookies.
Flash cookies until recently were not cleared when you cleared your cookies. Only the latest versions of Google Chrome can clear Flash cookies when you clear regular cookies. Those. Until recently, Flash cookies were virtually undeletable. There was a special page on the macromedia website where you had to go, click the button: “Yes, I want to clear Flash cookies,” and then they are cleared, i.e. Without this page it was impossible to clean up.
Next, evercookie uses Silverlight Cookies. They are otherwise called Isolated Storage. This is a special allocated space on the user’s computer’s hard drive where cookie information is written. It is impossible to find this place unless you know the exact path. It is hidden somewhere in documents, Settings, if on Windows, deep in the bowels of the computer. And this data cannot be deleted by clearing cookies.
Further. Evercookie uses such innovative technology as PNG Cookies. The bottom line is that the browser returns an image in which the bytes of this image encode the information that you have saved, for example, an identifier. This image is served with a caching directive forever, say, for the next 50 years. The browser caches this image, and then the next time the user visits, the Canvas API reads the bytes from this image and restores the information that you wanted to save in the cookie. That. Even if the user has cleared the cookie, that PNG cookie-encoded image will still be in the browser's cache and the Canvas API can read it on a subsequent visit.
Evercookie uses all available browser storage - modern HTML 5 standard, Session Storage, Local Storage, Indexed DB and others.
The ETag header is also used - this is an http header, very short, but you can encode some information in it, and if Java is installed, then the java presistence API is used.
Evercookie is a very smart plugin that can save your data almost anywhere. For an ordinary user who does not know all this, it is simply impossible to delete these cookies. You need to visit 6-8 places on your hard drive and perform a series of manipulations just to clean them. Therefore, the average user, when visiting a site that uses evercookie, will most likely not be anonymous.
Despite all this, evercookie does not work in incognito mode. Once you enter incognito mode, no data is saved to disk, because that is the fundamental essence of incognito mode - you must be anonymous. And evercookie uses hard drive storage, which does not work in this mode.
FingerprintJS is a little library I wrote that tries to solve these problems. I'll tell you how she does it and what came of it.
I wrote it in 2012. I then worked at KupiKupon as a Ruby developer. And I had the task of creating an analytics system that would take into account not just logged-in users, i.e. those users who are in our system, as well as anonymous users. Specifically, on the “KupiKupon” site there were many anonymous users, because people often came from outside to look at some coupons, discounts, offers, they did not have an account, and therefore the tracking system, the system for tracking visited pages, clicks on buttons - none of this worked because the users were anonymous.
FingerprintJS doesn't use cookies at all. No information is saved on the hard drive of the computer where the browser is installed. It works in incognito mode because it basically does not use hard drive storage. It has no dependencies, works even without jQuery, and is 1.2 KB gzipped.
Currently used in companies such as Baidu, Google in China, MasterCard, the website of the US President, AddThis - a site for hosting widgets, etc.
This library quickly became very popular. It is used by approximately 6-7% of all the most visited sites on the Internet at the moment.
I’ll tell you in detail how it works. Its essence is that the code of this library queries the user’s browser for all the specific and unique settings and data for this browser and for this system, for the computer. This data is concatenated into a huge string, then it is fed into the hashing function. The hashing function takes this data and turns it into compact, beautiful identifiers. I'll tell you in detail how this works.
First the userAgent navigator is read. Let's say it's cut off here, it's appended to the final line of the print.
The browser language is read - what is your language - English, Russian, Portuguese, etc. Also attached to the fingerprint line.
The time zone is read, this is the number of minutes from UTC:
–180.
This is -3, which turns out to be Moscow.
Next we get the screen size, array, screen color depth.
Then all supported HTML5 technologies are retrieved, i.e. Each browser has different support. FingerprintJS tries to determine which are supported and which are not, and for each technology, the result of a poll for the presence of that technology and the degree of its support is added to the resulting fingerprint function.
SessionStorage, LocalStorage, IndexedDB, OpenDatabase and all kinds of others.
User-specific and platform-specific data is queried, such as the doNotTrack setting (it’s very ironic that the doNotTrack setting is used specifically for tracking), cpuClass of the processor, platform and other data.
Here you may have a natural question - after all, many users have the same data? Let's say the user lives in Moscow, he will have the same language, the latest Chrome, he will have everything almost the same, and all these strings that were received at this stage will be the same. How will this help identify the user?
There are 2 more ways that add uniqueness.
- The first is information about plugins. The code queries the presence of all installed plugins on the system. For each plugin, you get its description and name. And also, which is very important, a list of all multimedia types or main types that support this plugin. All this information is combined into a huge array of strings, and this array is also concatenated and added to the fingerprint string. As you understand, each computer has its own list of plugins, quite unique, and the versions of the plugins can be different, and the list of types supported by main will also be different.
- The next thing is that the so-called is added to the fingerprint line. Canvas Fingerprint. This is another technique that can improve accuracy. Its essence lies in the fact that a certain text with certain effects superimposed on it is drawn on a hidden Canvas element. And then the resulting image is serialized into a byte array and converted to base64 using the canvas.toDataULR() call.
The question that arises here is: how does this also help in identification? What was unexpected for me was the research I found. It suggests that font rendering, in particular in the Canvas API, is very platform dependent. Externally identical identical images drawn in different browsers will be converted to a different byte array. Why? This depends on the processor, video card, video card drivers, system libraries such as direct X, font rendering systems, shadows - all of this can be different on each computer, so the resulting byte array will be different on almost every computer, which will have different hardware and software filling. And this long string obtained during Canvas serialization will be attached to the final print, and we will get a huge string.
Here's how it works. We receive all this data. Then we pass them to the hashing function, FingerprintJS uses nomo hash2, and the output is a 32-bit number. This is your ID. Thus, when a user visits our website, he is assigned a number. You read this number and use it as you wish - you base your analytics on it, etc.
The question here is: how unique and accurate is the definition? The study it was based on was done by the Electronic Frontier Foundation, they had a project called Panopticlick. It says that the uniqueness is about 94%, but in the real data that I had, the uniqueness was about 90%-91%.
The library began to be used by many people and companies, and over time a number of shortcomings emerged. Those. she is not perfect, she has flaws. The main disadvantage is that the identification accuracy is only 90%, but there are other disadvantages.
- UserAgent. In modern browsers, UserAgent changes very often; a new version of Google Chrome is released every two months. UserAgent will change because the version of Google Chrome that is protected in UserAgent will be different. This means that UserAgent will influence the final fingerprint. If a new browser comes out, the resulting fingerprint will change because from FingerprintJS's perspective it will be a new user.
- IPhone, iPad and other Apple products. The fact is that they are very uniform, identical from the point of view of hardware implementation. They all have the same processors. If we take, of course, a single model, let’s say the IPhone 5S, all IPhone 5S will have the same processor, the same graphics accelerator and the same system libraries, and the plugins will be the same, but in fact they are not there. This means that the byte array obtained from the Canvas Fingerprint will be the same for all versions of the iPhone 5S, which means that the identification accuracy for Apple products will be lower.
- Internet Explorer and China. I didn’t suspect this problem existed, but then I found out that there are a lot of old versions of IE in use in China, and in order to get a list of plugins, you need to have the names of all the plugins in advance. Because in order to check whether a plugin exists or not, it is simply impossible to call, for example, navigator.plugins in IE. This won't work. You need to take and try to instantiate each plugin as an active ex object. If it is created, then everything is fine. If an error is thrown, it means that the plugins are not installed in IE. I had a list of plugins for IE, but it was short - about ten plugins. I did not have a definition of those plugins that are popular in China, such as QQ, baidu, etc. There are a lot of plugins that are used only there. I did not check these plugins, and the list of plugins for China specifically was smaller.
- Another drawback of the first version is the lack of integration with Flash and Silverlight, and integration with these plugins allows you to improve the quality of Fingerprint.
- And the last but rather serious thing that recently hit FingerprintJS is that, starting with version 42, Google Chrome simply stopped activating all those plugins that work through NPAPI. NPAPI is a very old API for instantiating plugins, it was developed by Nextkey. It’s called “Nextkey plugin API”. All the plugins that work and rely on this protocol, on this API, have stopped loading, and therefore neither Silverlight nor Java, and these two plugins are the most popular, that work through NPAPI, are not displayed in FingerprintJS - they are not defined in any way. and the list of their main types is also not displayed. This means that in Chrome 42 and older, the accuracy of FingerprintJS is reduced due to this issue.
Therefore, after analyzing all this, and now I also use FingerprintJS, I came to the conclusion that it is time to develop a new library that will be practically devoid of all existing shortcomings.
I started making it quite recently, development is underway on github.
How does it solve existing problems? The most important thing is that phase hashing or localsensitivehash, or fuzzy hashing is used. The kind of hashing that doesn't change, even though in normal hashing, if you change even one byte of the input information, the output string will also change, and in a dramatic way. This does not happen in phase hashing; there is a sensitivity threshold where a certain percentage of the incoming data can change without affecting the outgoing fingerprint. Let's say that if only the browser version has changed in UserAgent, this happens very often, for example, in Chrome, then the resulting fingerprint will be the same, because the version is 3 or 5% of the total length from UserAgent.
Second, FingerprintJS 2 uses the definition of installed fonts, all fonts that are installed on the system. How is this useful? If you installed a program, say Adobe pdf, then you add fonts to the system.
If you installed Microsoft Office, you add fonts to the system; if you installed some Quick office that has its own fonts, you again add fonts to the system. And so you can have two absolutely identical computers, but one has Office installed and the other does not. This means that on the first one, where there is no Office, there will be 320 available fonts, and on the one where there is Office - 1700 fonts. And that means that you can get all the fonts that are on this computer, again, for the final print. These will be two different prints because the fonts are different.
The default is Flash, a small swf file of 916 bytes. It receives a list of all installed fonts, and in platform-dependent order, because they are available in the system, so they will be returned. If Flash is not installed, this technique is used, it is called site chanel technic. It was first published on lalit.org. This is detecting the presence of a font using javascript only. How it's done? For each reference font that is set by default in the browser or system, its width and height are measured and this array of width and height is stored. Then a different font is applied to the hidden text (the text, by the way, is huge, say 72 pixels). If this font is in the system, the text will change its dimensions correctly, and the code that changes the height and width will receive a new array with height and width. If it differs from the reference one, from the one that was received when requesting the default font, then this font is installed. If it is not different, then this font does not exist.
A very simple idea, but it works. Currently, this code can reliably identify about 500 fonts without using Flash. And, accordingly, the computer that has Microsoft Office and the one that doesn’t will be identified differently in FingerprintJS 2 due to this technique.
The third difference is WebGL Fingerprint. This is a development of the Canvas Fingerprint idea. Its essence is that 3D triangles are drawn (it’s not very visible on the slide, but it’s 3D). Effects, gradients, various anisotropic filtering, etc. are applied to it. And then it is converted to a byte array. The resulting byte array, as with Canvas Fingerprint, will be different on many computers. Then information about platform-dependent constants that are defined in WebGL is added to this byte array. Those. WebGL has a set of constants that must be included in the implementation. This is the color depth, the maximum size of textures... There are a lot of these constants, dozens of them. The code interrogates all these constants and, of course, on Android devices these constants will be different; there the color depth may be different than on Windows or Linux. It polls all these constants, it all adds up again into a huge array, and it all gets added to a serialized 3D triangle image that is drawn using hardware effects.
There is also a question here: how does this help to identify? 3D graphics are very platform-dependent, the version of drivers, the version of the video card, the OpenGL standard in the system, the version of the shader language - all this will affect how this image will be drawn inside. And when it is converted to a byte array, it will be different on many computers.
Why is WebGl Fingerprint important? Because IOS 8.1 supports WebGL, and this helps to identify IOS devices, the identification problem of which I mentioned. Therefore, WebGL improves the accuracy of Fingerprint.
What else remains to be implemented?
As I said, the library is under development and not all the things I would like to do in it have been done. There is already a small community of developers around it. By the way, I invite everyone to participate in the development - it is very interesting, we are very informal, everyone offers ideas, it is quite interesting.
What remains to be implemented? WebRTC Fingerprinting.
WebRTC is a standard for peer-to-peer communications over audio streams, or it is a standard for audio communications in modern browsers. It allows you to make audio calls etc., it is supported in FireFox and will be supported in other browsers soon.
The implementation of the WebRTC standard is also platform-dependent; it will depend on the video card that is installed in the system, on sound drivers, etc. Therefore, by measuring different levels of latency, different levels of WebRTC support and constants that are hardcoded in this format, you can get different final fingerprints for different computers.
More IE plugins will be used. Those plugins that are popular in different countries will be used - China, India, etc., i.e. growing information markets. The first version did not pay enough attention to this problem, but this will be resolved in the second version.
More information will be collected about the OS. How will we do this? Integration with Flash and Silverlight will be used. Flash allows you to get information about the system, such as kernel version, kernel level patch. Silverlight, if on Windows, allows you to get the Windows version, bild, Windows number, all this is available through Silverlight.
A few words about Silverlight, why integration with sliverlight is also quite important? Maybe in Russia the Silverlight plugin is not very popular, but in the USA, for example, there is a video streaming service Netflix that broadcasts video, and I know for sure that they use Silverlight. Due to the fact that it supports DRM (this is a system for restricting digital rights to content), because... Netflix often shows various new Hollywood films, they use Silverlight to ensure that this video does not go viral on the Internet. Therefore, in the USA, many desktop Internet users have the Silverlight plugin installed, which, by the way, is available on Mac too, in addition to Windows.
Detection of multiple monitors will be implemented. If we request the dimensions via javascript, we will simply get two numbers - this is the width and height of the screen. If we do the same via Flash API, Actionscript API, we will get an array of arrays. This means that if several monitors are installed, where each subarray is the screen size of each monitor. If the developer is sitting at five monitors, he will receive an array of arrays of five elements, so we know that the person is sitting at five monitors, and not at the main monitor, which javascript would return.
All these data together allow us to currently obtain a determination accuracy of about 94-95%. But, as you understand, this is insufficient identification accuracy. This raises the question: how can this be improved, and can it be improved? I think it is possible. The goal of this project is to achieve 100% identification so that you can rely on Fingerprint in 100% of cases and be guaranteed to say: “Yes, this user came to us; yes, I know everything about him, despite the fact that he uses incognito mode, tor network...” It doesn't matter, it will all be determined.