
Mutt
Professional
- Messages
- 1,458
- Reaction score
- 1,280
- Points
- 113
Содержание статьи
Что такое анонимизация данных
Анонимизация данных - это процесс защиты частной или конфиденциальной информации путем стирания или шифрования идентификаторов, которые связывают человека с сохраненными данными. Например, вы можете использовать личную информацию (PII), такую как имена, номера социального страхования и адреса, с помощью процесса анонимизации данных, который сохраняет данные, но сохраняет анонимность источника.
Однако даже когда вы очищаете данные идентификаторов, злоумышленники могут использовать методы деанонимизации, чтобы отследить процесс анонимизации данных. Поскольку данные обычно проходят через несколько источников, некоторые из которых доступны общественности, методы деанонимизации могут ссылаться на источники и раскрывать личную информацию.
Общие Положение о защите данных (GDPR) описывает определенный набор правил , которые защищают пользовательские данные и создать прозрачность. Хотя GDPR является строгим, он позволяет компаниям собирать анонимные данные без согласия, использовать их для любых целей и хранить в течение неопределенного времени - до тех пор, пока компании удаляют все идентификаторы из данных.
Методы анонимизации данных
Недостатки анонимизации данных
GDPR предусматривает, что веб-сайты должны получать согласие пользователей на сбор личной информации, такой как IP-адреса, идентификатор устройства и файлы cookie. Сбор анонимных данных и удаление идентификаторов из базы данных ограничивают вашу способность извлекать пользу из ваших данных и анализировать их. Например, анонимные данные нельзя использовать в маркетинговых целях или для персонализации взаимодействия с пользователем.
Как система помогает защитить ваши данные
Data Security помогает анонимизировать данные, маскируя данные и классифицируя конфиденциальную информацию. Он предоставляет несколько методов преобразования, обеспечивая при этом масштабируемость и производительность корпоративного класса.
Анонимизация и маскирование данных - часть нашего комплексного решения безопасности, которое защищает ваши данные, где бы они ни находились - локально, в облаке или в гибридных средах. Анонимизация данных обеспечивает безопасность и позволяет ИТ-специалистам полностью контролировать доступ к данным, их использование и перемещение по организации.
Перед анонимизацией:
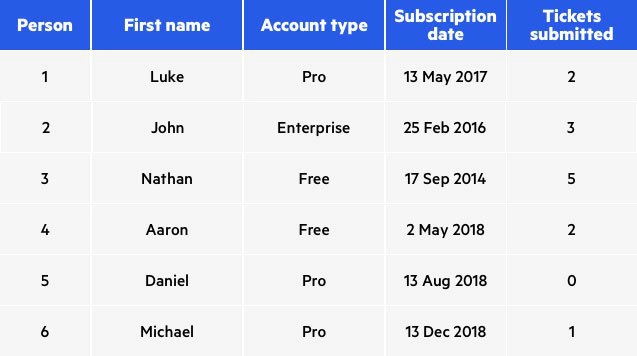
До анонимизации.
В этом примере значения всех атрибутов поменялись местами:
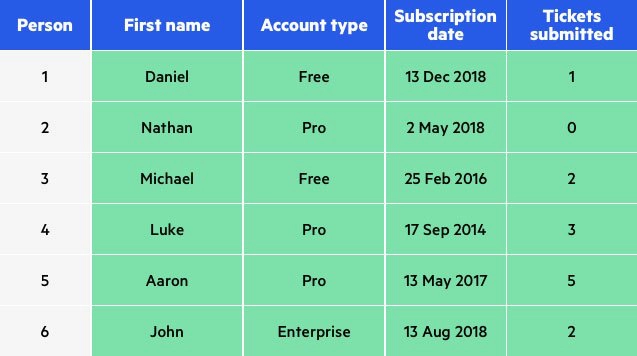
Постанонимизация.
Наш комплексный подход основан на нескольких уровнях защиты, включая:
- Что такое анонимизация данных
- Методы анонимизации данных
- Недостатки анонимизации данных
- Как система помогает защитить ваши данные
Что такое анонимизация данных
Анонимизация данных - это процесс защиты частной или конфиденциальной информации путем стирания или шифрования идентификаторов, которые связывают человека с сохраненными данными. Например, вы можете использовать личную информацию (PII), такую как имена, номера социального страхования и адреса, с помощью процесса анонимизации данных, который сохраняет данные, но сохраняет анонимность источника.
Однако даже когда вы очищаете данные идентификаторов, злоумышленники могут использовать методы деанонимизации, чтобы отследить процесс анонимизации данных. Поскольку данные обычно проходят через несколько источников, некоторые из которых доступны общественности, методы деанонимизации могут ссылаться на источники и раскрывать личную информацию.
Общие Положение о защите данных (GDPR) описывает определенный набор правил , которые защищают пользовательские данные и создать прозрачность. Хотя GDPR является строгим, он позволяет компаниям собирать анонимные данные без согласия, использовать их для любых целей и хранить в течение неопределенного времени - до тех пор, пока компании удаляют все идентификаторы из данных.
Методы анонимизации данных
- Маскирование данных - скрытие данных с измененными значениями. Вы можете создать зеркальную версию базы данных и применить методы модификации, такие как перетасовка символов, шифрование и подстановка слов или символов. Например, вы можете заменить символ значения таким символом, как «*» или «x». Маскирование данных делает невозможным обратное проектирование или обнаружение.
- Псевдонимизация - метод управления данными и деидентификации, который заменяет частные идентификаторы поддельными идентификаторами или псевдонимами, например, заменяя идентификатор «Джон Смит» на «Марк Спенсер». Псевдонимизация сохраняет статистическую точность и целостность данных, позволяя использовать измененные данные для обучения, разработки, тестирования и аналитики, одновременно защищая конфиденциальность данных.
- Обобщение - намеренно удаляет некоторые данные, чтобы сделать их менее идентифицируемыми. Данные могут быть преобразованы в набор диапазонов или обширную область с соответствующими границами. Вы можете удалить номер дома в адресе, но убедитесь, что вы не удалили название дороги. Цель состоит в том, чтобы удалить некоторые идентификаторы, сохранив при этом определенную точность данных.
- Обмен данными - также известный как перетасовка и перестановка, метод, используемый для изменения порядка значений атрибутов набора данных, чтобы они не соответствовали исходным записям. Замена атрибутов (столбцов), которые содержат значения идентификаторов, такие как, например, дата рождения, может иметь большее влияние на анонимность, чем значения типа членства.
- Возмущение данных - немного изменяет исходный набор данных, применяя методы округления чисел и добавления случайного шума. Диапазон значений должен быть пропорционален возмущению. Маленькая база может привести к слабой анонимности, в то время как большая база может снизить полезность набора данных. Например, вы можете использовать основание 5 для округления таких значений, как возраст или номер дома, потому что оно пропорционально исходному значению. Вы можете умножить номер дома на 15, и значение может сохранить свою достоверность. Однако использование более высоких оснований, таких как 15, может сделать значения возраста фальшивыми.
- Синтетические данные - информация, созданная с помощью алгоритмов и не имеющая отношения к реальным событиям. Синтетические данные используются для создания искусственных наборов данных вместо того, чтобы изменять исходный набор данных или использовать его как есть, рискуя конфиденциальностью и безопасностью. Процесс включает создание статистических моделей на основе шаблонов, найденных в исходном наборе данных. Вы можете использовать стандартные отклонения, медианы, линейную регрессию или другие статистические методы для создания синтетических данных.
Недостатки анонимизации данных
GDPR предусматривает, что веб-сайты должны получать согласие пользователей на сбор личной информации, такой как IP-адреса, идентификатор устройства и файлы cookie. Сбор анонимных данных и удаление идентификаторов из базы данных ограничивают вашу способность извлекать пользу из ваших данных и анализировать их. Например, анонимные данные нельзя использовать в маркетинговых целях или для персонализации взаимодействия с пользователем.
Как система помогает защитить ваши данные
Data Security помогает анонимизировать данные, маскируя данные и классифицируя конфиденциальную информацию. Он предоставляет несколько методов преобразования, обеспечивая при этом масштабируемость и производительность корпоративного класса.
Анонимизация и маскирование данных - часть нашего комплексного решения безопасности, которое защищает ваши данные, где бы они ни находились - локально, в облаке или в гибридных средах. Анонимизация данных обеспечивает безопасность и позволяет ИТ-специалистам полностью контролировать доступ к данным, их использование и перемещение по организации.
Перед анонимизацией:
До анонимизации.
В этом примере значения всех атрибутов поменялись местами:
Постанонимизация.
Наш комплексный подход основан на нескольких уровнях защиты, включая:
- Брандмауэр базы данных - блокирует внедрение SQL-кода и другие угрозы при оценке известных уязвимостей.
- Управление правами пользователей - отслеживает доступ к данным и действия привилегированных пользователей для выявления чрезмерных, несоответствующих и неиспользуемых привилегий.
- Маскирование и шифрование данных - запутать конфиденциальные данные, чтобы они были бесполезны для злоумышленников, даже если они каким-то образом извлечены.
- Предотвращение потери данных (DLP) - проверяет данные в движении, в состоянии покоя на серверах, в облачном хранилище или на конечных устройствах.
- Аналитика поведения пользователей - устанавливает базовые параметры поведения при доступе к данным, использует машинное обучение для обнаружения аномальных и потенциально рискованных действий и оповещения о них.
- Обнаружение и классификация данных - выявляет расположение, объем и контекст данных в локальной среде и в облаке.
- Мониторинг активности баз данных - мониторинг реляционных баз данных, хранилищ данных, больших данных и мэйнфреймов для генерации предупреждений в реальном времени о нарушениях политики.
- Приоритизация предупреждений - используются технологии искусственного интеллекта и машинного обучения для анализа потока событий безопасности и определения приоритетов наиболее важных из них.