Man
Professional
- Messages
- 3,222
- Reaction score
- 1,231
- Points
- 113
Contents
### Abstract
In this paper, we use natural language processing techniques and machine learning algorithms to profile threat actors based on their behavioral signatures to establish soft attribution. Our unique dataset includes various actors and the commands they executed, with a significant share of usage of the Cobalt Strike platform between August 2020 and October 2022. We implemented a hybrid deep learning architecture combining Transformers and Convolutional Neural Networks to extract global and local contextual information in the command sequences, providing a fine-grained view of the threat actors’ behavioral patterns. We evaluated our hybrid architecture against pre-trained Transformer-based models such as BERT, RoBERTa, SecureBERT, and DarkBERT using our high-, medium-, and low-frequency datasets. The hybrid architecture achieved 95.11% F1-score and 95.13% accuracy on the high-frequency dataset, 93.60% F1-score and 93.77% accuracy on the medium-frequency dataset, and 88.95% F1-score and 89.25% accuracy on the low-frequency dataset. Our approach has the potential to significantly reduce the workload of incident response specialists who process collected cybersecurity data to identify patterns.
Irshad and Siddiqui also focused on attribution of cyber threat actors using NLP and machine learning techniques to analyze unstructured CTI reports. Given that cyberattackers often use camouflage and deception to hide their identities, the researchers aimed to develop an automated system to extract features from these reports for attack profiling and attribution. These features include tactics, techniques, tools, malware, and target information. They used an embedding model called “Attack2vec” trained on domain-specific embeddings. Various machine learning algorithms such as decision tree, random forest, and support vector machine were used for classification. The model achieved 96% accuracy.
Perry, Shapira, and Puzis proposed an attack attribution method involving text analysis of CTI reports using NLP and machine learning techniques. The researchers developed a unique text representation algorithm capable of capturing contextual information. Their approach uses a vector space text representation derived from a combination of labeled reports and a large corpus of security literature. Based on their previous study, Puzis and Angappan conducted a new study focusing on threat actor attribution based on similar CTI reports. Unlike traditional machine learning methods that focus on analyzing malware samples, this study proposes a deep learning architecture for the attribution task.
The main contributions of our study include:
In this study, Transformers can help identify cyber threat actors based on the commands used by attackers. Command sequences executed by actors often contain long dependencies, where the meaning of a command can be conditioned on a command executed long ago. Therefore, the Transformer architecture is used in our hybrid deep learning architecture. The Transformer architecture has also been used to train larger language models such as BERT [4], RoBERTa [14], SecureBERT [1], and DarkBERT [11]. These models were used as baselines for specific tasks since they were trained on a large text corpus. Using these pre-trained Transformer-based models in a specific task requires retraining the model with a new dataset for the specific domain. In our case, this dataset is the command sequences of cyber threat actors.
To analyze threat actor command sequences, we use one-dimensional convolutional neural networks (Conv1D). This approach captures local and contextual features from command sequences by sliding filters over the text. By using filters of different sizes corresponding to different n-gram analyses, the network becomes more capable of extracting a variety of semantic and syntactic features that indicate the behavior of a threat actor. In our case, threat actor commands can be considered as text. Therefore, these sequences may have patterns that can provide insight into the behavioral characteristics of a cyber threat actor, and Conv1D can extract these patterns.
Dropout is a regularization technique that randomly sets a portion of the input features to 0, which helps prevent overfitting, resulting in a general and robust model. Additionally, spatial dropout [27] is a specific type of dropout used in CNNs that preserves the spatial coherence of the input data, allowing the model to learn spatially local features. In our case, spatial dropout can be useful as it is more capable of helping the architecture capture meaningful localized features. For example, pixels in an image can form meaningful patterns in the local context, such as edges, textures, and shapes. Similarly, local patterns can be significant in command sequences, such as command flags, arguments, and their sequential order. In addition, weight decay is another technique to mitigate the overfitting problem. This method prevents the model weights from reaching large values, which can lead to overfitting, by adding a penalty term to the loss function.
F1-score is a useful metric when working with imbalanced classes. It is the harmonic mean of precision and recall, which are calculated based on true positives, false positives, and false negatives.
For multi-class problems like ours with more than 2 cyber threat actors, we calculate a weighted average of F1-scores.

The dataset includes several attack frameworks such as Cobalt Strike. The raw form of the data consists of lists of commands executed by the CTA along with the exact time of their execution. The data is already grouped by unique CTA IDs, thus the data is labeled with CTA aliases. For example, Table 1 shows an example of the command structure and its content. The JSON data of the command execution consists of two fields, namely data and timestamp. The data field contains the information and commands executed by the CTA. On the other hand, the timestamp field is designed to store UNIX time data.

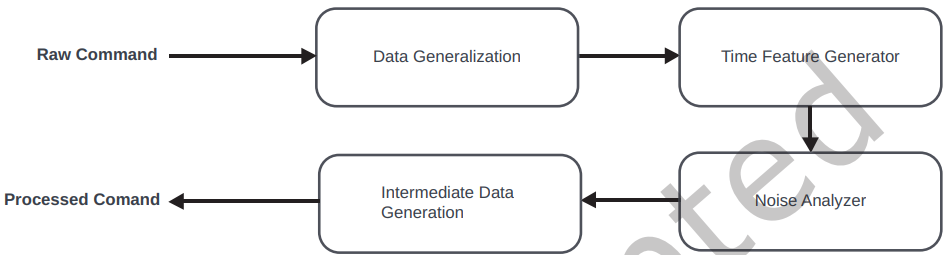
The Standardized Command Language Converter (SCLC) scheme involves converting unstructured and diverse command data into a universal format that conforms to the specific syntax and semantics defined by the SCL, such as converting different file path syntaxes into a universal one. Creating such a language provides a more accurate, scalable, and uniform environment for language processing, improving the overall efficiency and accuracy of our NLP architecture. As shown in Figure 2, a raw command must go through four stages before becoming a processed command.
The Standardized Command Language Converter (SCLC) aims to simplify raw commands into a Standardized Command Language (SCL), which is specifically designed to standardize command data. SCLC involves converting unstructured and diverse command data into a universal format that conforms to a specific syntax and semantics defined by the SCL, for example, converting various file path syntaxes into a universal one. Creating such a language provides a more accurate, scalable, and uniform environment for language processing, improving the overall efficiency and accuracy of our NLP architecture. As shown in Figure 2, a raw command must go through four stages before becoming a processed command.


Our dataset consists of command sequences of 34 threat actors. However, the size of the CTA data is not uniform. To handle the imbalance in the sizes of the datasets, we divided the CTAs into three categories: large volume, medium volume, and small volume. The experiments are conducted on these different-sized datasets using all the mentioned deep learning models to provide a comprehensive evaluation. Then, as explained earlier, the dataset is divided into a training set, which constitutes 70% of the data, a validation set, which constitutes 15%, and a test set, which constitutes the remaining 15%.
We conducted an extensive hyperparameter tuning process to optimize the performance of our models, and the best combination of hyperparameters was selected based on the validation F1 score. The best set of hyperparameters and its metrics for the pre-trained Transformer-based models can be seen in Table 5.
Figure 9 shows the relationship between the dataset sizes and the performance metrics. These results highlight the importance of the dataset size for an effective model that detects CTAs. However, it is noteworthy that the hybrid architecture shows relatively good results in all dataset conditions. This shows the ability of the architecture to learn important features of CTAs from their instruction sequences and to generalize better under data-poor conditions. This resilience to data deficiencies makes the hybrid architecture much more important since data labels are often difficult to obtain in real-world applications.
These results suggest that our hybrid deep learning architecture is the best-performing model among the other pre-trained models that were tested, both in terms of accuracy and F1 score.
As can be seen in Figure 5 for the high volume dataset, the hybrid architecture demonstrates good performance on almost all CTAs. The high values on the diagonal indicate that the model effectively classifies instances for each class. In Figure 6, a relatively balanced performance is observed for the medium volume dataset. Although the diagonal elements are strong, indicating good classification, there is room for improvement, for example, for CTA #6. The low volume dataset shown in Figure 7 demonstrates a more challenging scenario. Although the model performs well for most CTAs, it is observed that the model struggles with CTAs with fewer command sequences.
These results highlight the importance of dataset size for an effective model that detects CTAs. However, it is worth noting that the hybrid architecture shows relatively good results across all dataset conditions. This demonstrates the ability of the architecture to learn important features of CTAs from their instruction sequences and to generalize better under data-poor conditions. This robustness to data-poor conditions makes the hybrid architecture much more important, as data labels are often difficult to obtain in real-world applications.
It is also important to understand that the process of attributing a threat actor does not solely rely on the sequence of commands that the actor executes. There are many traits and methods that should be considered when making attribution, meaning that our model should not be the sole source for the process, but should be considered as a guide.
Due to the nature of our experiments and the fact that we did not have access to real victims but mainly used honeypots, our dataset consists only of commands executed by the attacker. This method of selectively collecting data inherently introduces a sampling bias, as it does not capture commands from legitimate users that are typically present in real datasets. As a result, our model has a bias towards attacker commands, which raises doubts about its effectiveness in real-world scenarios. More research is needed to mitigate this bias and improve the applicability of the model to real-world scenarios. This could include simulating more authentic datasets by including legitimate user commands or using real user and attacker command datasets if they become publicly available.
Our hybrid deep learning architecture has proven its power to capture local and global contextual information in command sequences, outperforming well-known pre-trained Transformer-based models such as BERT, RoBERTa, SecureBERT, and DarkBERT. The hybrid architecture achieved an F1-score of 95.11% and an accuracy of 95.13% on the high-volume dataset, an F1-score of 93.60% and an accuracy of 93.77% on the medium-volume dataset, and an F1-score of 88.95% and an accuracy of 89.25% on the low-volume dataset. These results highlight the potential of integrating CNNs and Transformers mechanisms in challenging NLP tasks, especially in the cybersecurity domain.
Our study yielded several key findings that provide significant insights into cybersecurity. First, we found that our approach can significantly reduce the workload of cybersecurity analysts by providing a systematic and automated means of CTA attribution. By applying our method, analysts are freed from the burden of manually tracking down threat origins, allowing them to focus their expertise and efforts on more pressing or strategic tasks. In addition, this automation not only increases productivity, but also reduces the risk of human error by providing a starting point for the threat actor attribution process.
With this knowledge, it becomes much more feasible to create more effective countermeasures and defense strategies. Unique defense strategies can be developed based on the commands of a specific CTA. For example, understanding a CTA’s preference for certain command sequences or attack vectors can guide the design of specific intrusion detection rules or firewall configurations. Likewise, knowledge of CTA behavior patterns can also inform incident response plans, allowing for quick and effective action in the event of a security breach.
Furthermore, our study contributes to a deeper understanding of the modus operandi of specific CTAs. This fine-grained understanding equips cybersecurity professionals with valuable knowledge to predict potential targets and anticipate attack patterns, enabling proactive rather than reactive defense strategies. Moreover, our work opens up many exciting avenues for future research in the fields of cyber threat intelligence and digital forensics. This includes exploring a deeper understanding of CTA behavior and the relationship between command sequences and CTA strategic intent. These studies may lead to a more nuanced and thorough understanding of CTAs and their motivations.
Our study highlights the power and potential of NLP methods and deep learning architectures in solving complex digital forensics problems. Our work represents an important step towards an era where automated intelligence systems play a central role in strengthening our cybersecurity infrastructure and simplifying digital forensics and incident response tasks by introducing a new method of CTA attribution. The path forward is filled with promising opportunities for innovative and cutting-edge research in cyber defense and cyber threat intelligence.
- Abstract
- 1. Introduction
- 2. Related Works
- 3. Background
- 3.1 Transformer Architecture
- 3.2 Convolutional Neural Networks
- 3.3 Residual Connections
- 3.4 Regularization Techniques
- 3.5 Hyperparameter Tuning
- 3.6 Cross Validation
- 3.7 Metrics for Evaluation
- 4. Dataset
- 5. Methodology
- 5.1 Standardized Command Language (SCL)
- 5.2 Architecture
- 5.3 Data Preparation
- 6. Experiments
- 6.1 Experimental Environment
- 6.2 Hyperparameter Tuning
- 6.3 Cross Validation
- 7. Results
- References
Brief description of each section
- Abstract: Abstract and key findings of the study.
- 1. Introduction: Introduction to the research topic, purpose and objectives.
- 2. Related Works: Review of related works and existing methods.
- 3. Background: Theoretical foundations and technical aspects, including the architecture of transformers and convolutional neural networks.
- 4. Dataset: Description of the dataset used.
- 5. Methodology: Methods and approaches used in the study.
- 6. Experiments: Description of the experimental environment and hyperparameter tuning results.
- 7. Results: Final results of the experiments and their interpretation.
- References: List of references and sources.
### Abstract
In this paper, we use natural language processing techniques and machine learning algorithms to profile threat actors based on their behavioral signatures to establish soft attribution. Our unique dataset includes various actors and the commands they executed, with a significant share of usage of the Cobalt Strike platform between August 2020 and October 2022. We implemented a hybrid deep learning architecture combining Transformers and Convolutional Neural Networks to extract global and local contextual information in the command sequences, providing a fine-grained view of the threat actors’ behavioral patterns. We evaluated our hybrid architecture against pre-trained Transformer-based models such as BERT, RoBERTa, SecureBERT, and DarkBERT using our high-, medium-, and low-frequency datasets. The hybrid architecture achieved 95.11% F1-score and 95.13% accuracy on the high-frequency dataset, 93.60% F1-score and 93.77% accuracy on the medium-frequency dataset, and 88.95% F1-score and 89.25% accuracy on the low-frequency dataset. Our approach has the potential to significantly reduce the workload of incident response specialists who process collected cybersecurity data to identify patterns.
Introduction
The Importance of Cyber Threat Attribution
Cyber threat actor attribution (CTA) is a critical aspect of cyber threat intelligence (CTI) and digital forensics, as well as incident response research. It is the process of identifying the responsible party or actor for a given cyberattack. The importance of attribution lies in identifying the source of past attacks and the ability to conduct predictive analysis for potential future attacks. One aspect of CTA attribution that enhances its accuracy and relevance is the inclusion of behavioral signatures and threat actor profiling.Behavioural signatures and threat actor profiling
Behavioral signatures refer to unique activity patterns that can be associated with a specific threat actor. On the other hand, threat actor profiling involves creating comprehensive profiles of cybercriminals based on a number of attributes, including but not limited to their behavioral signatures, tools, tactics, techniques, and procedures (TTPs) used. Profiling not only identifies the actors but also establishes definitive guidelines for attribution.Main problems and challenges
One of the main challenges with cybercriminal attribution and digital forensics is the quality of cyber threat intelligence data. Many analysts believe that cyber threat intelligence data streams can be of variable quality. Sometimes, they may lack data richness, meaning that they may not contain enough granular information to establish reliable behavioral signatures or build comprehensive profiles. As a result, analysts must expend significant effort to process and analyze the collected information, often sifting through sparse and noisy data to identify key attribution indicators. Therefore, integrating behavioral signatures and threat actor profiling can enrich the attribution process and make it more effective and efficient.The Importance of an Automated Approach
A critical challenge in CTI research is the need for a professional and automated approach to assigning a threat to a specific actor or group using the commands executed by that threat actor as a basis. Digital forensics experts can greatly benefit from attributing threats to specific actors based on command analysis. By studying the unique commands and sequences used by a threat actor, experts can identify unique behavioral patterns that act as digital fingerprints. This facilitates and speeds up investigations by providing information to identify attackers.Purpose and structure of the work
The goal of this paper is to fill this gap by providing attribution of CTAs based on the sequences of commands they executed. Our methodology highlights the importance of soft attribution, as it allows threat actors to be profiled and classified based on observed behavioral patterns without the need for specific evidence required for hard attribution. This approach is particularly effective in environments where direct evidence may be unavailable and attackers often use sophisticated methods to obscure their identity.Conclusion
Our work highlights the power and potential of natural language processing (NLP) methods and deep learning architectures in solving complex digital forensics problems. Our research represents an important step forward towards an era where automated intelligent systems play a central role in strengthening our cybersecurity infrastructure and simplifying digital forensics tasks, as well as in solving incident response problems by introducing a new method of CTA attribution. The path forward is filled with promising opportunities for innovative and cutting-edge research in the field of cyber defense and cyber threat intelligence.Related Works
Traditional Cyber Threat Attribution Methods
In traditional approaches to cyber threat attribution, manual analysis is the most common method. Our study is the first to propose CTA attribution based on the sequence of commands executed by actors using various natural language processing (NLP) and machine learning methods. However, there have been several attempts to attributing threat actors using machine and deep learning methods based on the behavior of actors.Approaches to Malware Analysis
Recent studies have proposed the idea of finding similarities between malware, which allows deanonymizing CTAs based on the source code and behavior of the malware. Rosenblum et al. developed the idea of attributing authorship of binary programs based on stylistic author similarities between programs using machine learning methods.CTI Report Analysis
Noor et al. conducted a study using NLP and machine learning techniques to analyze CTI reports. Their primary objective was to identify and profile CTAs targeting FinTechs based on their specific attack patterns. To do this, they applied an NLP technique known as distributional semantics. They trained and evaluated various machine learning and deep learning models using these publicly available CTI reports. Notably, the deep learning model they developed achieved 94% accuracy.Irshad and Siddiqui also focused on attribution of cyber threat actors using NLP and machine learning techniques to analyze unstructured CTI reports. Given that cyberattackers often use camouflage and deception to hide their identities, the researchers aimed to develop an automated system to extract features from these reports for attack profiling and attribution. These features include tactics, techniques, tools, malware, and target information. They used an embedding model called “Attack2vec” trained on domain-specific embeddings. Various machine learning algorithms such as decision tree, random forest, and support vector machine were used for classification. The model achieved 96% accuracy.
Perry, Shapira, and Puzis proposed an attack attribution method involving text analysis of CTI reports using NLP and machine learning techniques. The researchers developed a unique text representation algorithm capable of capturing contextual information. Their approach uses a vector space text representation derived from a combination of labeled reports and a large corpus of security literature. Based on their previous study, Puzis and Angappan conducted a new study focusing on threat actor attribution based on similar CTI reports. Unlike traditional machine learning methods that focus on analyzing malware samples, this study proposes a deep learning architecture for the attribution task.
Hybrid Deep Learning Architecture
In our study, we used NLP architectures such as Transformer, which are trained on a sequence of tokens to build a machine learning model. These methods learn from the positions of tokens and can understand the hidden relationships between these tokens. Understanding the relationship between a sequence of commands and their connections helps in the attribution process as it reveals their hidden features. We also used various deep learning methods by combining the capabilities of the Transformer architecture with convolutional neural networks (CNN). This study presents a unique hybrid deep learning architecture that integrates various methods specifically designed for the challenging task of threat actor attribution. We compared our hybrid deep learning architecture with well-known pre-trained models such as BERT, RoBERTa, SecureBERT, and DarkBERT.The main contributions of our study include:
- This paper presents the first research focused on analyzing and attributing malicious commands executed by threat actors on compromised machines, which is typically an inefficient and time-consuming process for digital forensics or incident response professionals.
- Building a Standardized Command Language Converter (SCLC) that converts raw commands into a standardized language to improve the efficiency and accuracy of NLP architectures and reduce overfitting.
- Developing a hybrid deep learning architecture for threat actor attribution that outperforms existing pre-trained Transformer-based models such as BERT, RoBERTa, SecureBERT, and DarkBERT. The hybrid architecture achieved 95.11% F1-score and 95.13% accuracy on the high-frequency dataset, 93.60% F1-score and 93.77% accuracy on the medium-frequency dataset, and 88.95% F1-score and 89.25% accuracy on the low-frequency dataset.
Basics (Background)
This section aims to provide a foundation of key concepts and a more comprehensive understanding of the context of our research, highlighting specific challenges and considerations within cyber threat attribution research.3.1 Transformer Architecture
The Transformer architecture was first proposed by Vaswani et al. [29]. It differs from previous natural language processing (NLP) techniques in that it copes much better with long-range dependencies. The Transformer uses an attention mechanism that helps the model to create global dependencies between the inputs and outputs. This architecture consists of two main components: an encoder and a decoder, and both of these components have self-attention and position-sensitive feedforward mechanisms. The self-attention mechanism replaces the idea of recurrence that was used in previous NLP architectures such as LSTM [9]. This mechanism allows the model to solve the problem of long-range dependencies by weighing the importance of different inputs for generating each output in a sequence. Additionally, the Transformer architecture uses a position-sensitive encoding mechanism because, unlike previous NLP architectures, Transformers do not have a recurrence mechanism that allows taking into account the order of a sequence, which is a key aspect of NLP tasks. Positional encoding provides the Transformer architecture with sequence information by adding a unique signal to each input token representing its position in the sequence. This allows the architecture to learn and generalize positional relationships between tokens.In this study, Transformers can help identify cyber threat actors based on the commands used by attackers. Command sequences executed by actors often contain long dependencies, where the meaning of a command can be conditioned on a command executed long ago. Therefore, the Transformer architecture is used in our hybrid deep learning architecture. The Transformer architecture has also been used to train larger language models such as BERT [4], RoBERTa [14], SecureBERT [1], and DarkBERT [11]. These models were used as baselines for specific tasks since they were trained on a large text corpus. Using these pre-trained Transformer-based models in a specific task requires retraining the model with a new dataset for the specific domain. In our case, this dataset is the command sequences of cyber threat actors.
3.2 Convolutional Neural Networks
Convolutional neural networks (CNNs) [13] are a deep learning algorithm used primarily to process structured grid data. CNNs have proven to be most influential in image and video recognition applications. The core component of this architecture is the convolution operation, which allows the model to learn spatial hierarchies of features. For example, features in early layers can be edges and textures, while features in later layers can be parts of objects.To analyze threat actor command sequences, we use one-dimensional convolutional neural networks (Conv1D). This approach captures local and contextual features from command sequences by sliding filters over the text. By using filters of different sizes corresponding to different n-gram analyses, the network becomes more capable of extracting a variety of semantic and syntactic features that indicate the behavior of a threat actor. In our case, threat actor commands can be considered as text. Therefore, these sequences may have patterns that can provide insight into the behavioral characteristics of a cyber threat actor, and Conv1D can extract these patterns.
3.3 Backup connections
Spacing connections, introduced by He et al. [7], are implemented by adding the output of an earlier layer to the output of a later layer, skipping several layers. This is valuable because it reduces the problem of "vanishing gradients" that commonly occurs when training complex models. The problem with vanishing gradients is that gradients become very small at deeper layers of the model being trained, which can slow down the learning process. Spacing connections solve this problem by allowing gradients to flow from earlier layers to later layers, improving learning efficiency even in very deep networks.3.4 Regularization Techniques
Overfitting is a common problem that needs to be addressed when a model learns too well on the training data and performs poorly on unseen data. This problem can be mitigated by regularization techniques such as dropout [26] and weight decay [15].Dropout is a regularization technique that randomly sets a portion of the input features to 0, which helps prevent overfitting, resulting in a general and robust model. Additionally, spatial dropout [27] is a specific type of dropout used in CNNs that preserves the spatial coherence of the input data, allowing the model to learn spatially local features. In our case, spatial dropout can be useful as it is more capable of helping the architecture capture meaningful localized features. For example, pixels in an image can form meaningful patterns in the local context, such as edges, textures, and shapes. Similarly, local patterns can be significant in command sequences, such as command flags, arguments, and their sequential order. In addition, weight decay is another technique to mitigate the overfitting problem. This method prevents the model weights from reaching large values, which can lead to overfitting, by adding a penalty term to the loss function.
3.5 Tuning hyperparameters
Hyperparameters are parameters set before training a model that change how it works. For example, they include the dropout rate, weight decay, learning rate, the number of epochs the model must go through, and many others. The process of choosing hyperparameters is important because it significantly affects the model.3.6 Cross-validation
Cross-validation technique is used to evaluate the performance and robustness of a model. First, we split the dataset into : subsets. One of these subsets is used for validation, and the remaining: − 1 subsets are used to train the model. This process is repeated : times, each time updating the subset used as the validation set and the training set as the rest. Finally, the : results are averaged to obtain a more robust metric. Additionally, the standard deviation of the performance across the : parts is calculated, where a low standard deviation indicates that the model is robust and performs consistently across different data subsets.3.7 Metrics for evaluation
We use two metrics to evaluate our model: accuracy and weighted F1-score. Accuracy simply measures the proportion of correctly classified instances.F1-score is a useful metric when working with imbalanced classes. It is the harmonic mean of precision and recall, which are calculated based on true positives, false positives, and false negatives.
For multi-class problems like ours with more than 2 cyber threat actors, we calculate a weighted average of F1-scores.
Dataset
Source and content of data
PRODAFT has provided private threat intelligence data collected from August 2020 to October 2022. The commands executed by the attackers were captured by PRODAFT using various private honeypot servers located in China, Europe, and the United States. The goal is to reduce the workload of cybersecurity analysts and promote progress in the field of cyber threat intelligence.The dataset includes several attack frameworks such as Cobalt Strike. The raw form of the data consists of lists of commands executed by the CTA along with the exact time of their execution. The data is already grouped by unique CTA IDs, thus the data is labeled with CTA aliases. For example, Table 1 shows an example of the command structure and its content. The JSON data of the command execution consists of two fields, namely data and timestamp. The data field contains the information and commands executed by the CTA. On the other hand, the timestamp field is designed to store UNIX time data.
Data Variety and Size
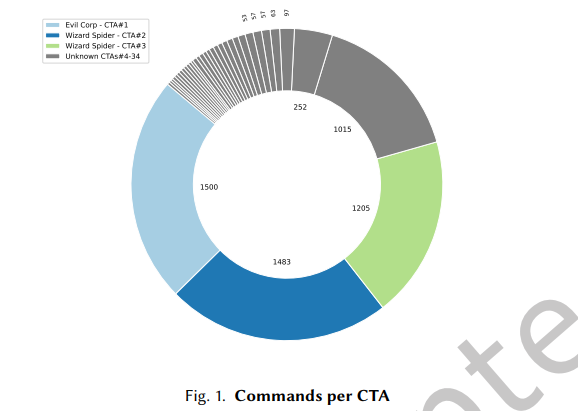
The dataset mainly contains 34 CTAs with more than 5000 commands. The number of command sequences in the dataset for each CTA is not uniform, that is, while CTA#1 has 1500 commands, CTA#25 has only 21 command sequences as shown in Figure 1. Only one uses a custom malware called SocGholish, while the rest of the attackers use Cobalt Strike to execute commands. The diversity of malware is due to the fact that we wanted to demonstrate that our architecture can predict attackers using different malware, and can also predict different attackers even if they use the same malware. The three most important CTAs in our dataset belong to different known attacker groups. Their details can be seen in Table 2; the affiliation of the remaining CTAs is unknown, but they are known to be different.Example of command data
The Standardized Command Language Converter (SCLC) scheme involves converting unstructured and diverse command data into a universal format that conforms to the specific syntax and semantics defined by the SCL, such as converting different file path syntaxes into a universal one. Creating such a language provides a more accurate, scalable, and uniform environment for language processing, improving the overall efficiency and accuracy of our NLP architecture. As shown in Figure 2, a raw command must go through four stages before becoming a processed command.
Methodology
5.1 Standardized Command Language (SCL) Converter
Overfitting is a phenomenon that describes when a developed machine learning model performs well on the dataset used to train the model, but performs poorly on a dataset that the model has not seen before. For example, cybercriminals may use highly specific filenames, IP addresses, URLs, and dates. This may cause our machine learning model to learn these specific characteristics instead of the characteristics that represent the behavioral and procedural features of the threat actor. Commands must be converted to a more general form to prevent this problem. Therefore, in this study, an intermediate component was created to convert each command to a more general form.The Standardized Command Language Converter (SCLC) aims to simplify raw commands into a Standardized Command Language (SCL), which is specifically designed to standardize command data. SCLC involves converting unstructured and diverse command data into a universal format that conforms to a specific syntax and semantics defined by the SCL, for example, converting various file path syntaxes into a universal one. Creating such a language provides a more accurate, scalable, and uniform environment for language processing, improving the overall efficiency and accuracy of our NLP architecture. As shown in Figure 2, a raw command must go through four stages before becoming a processed command.
5.1.1 SCLC Data Summarization Step
The first place where SCLC processes raw data. The motivation for this step is to create a common command map, as the different malware used by CTAs operate in different environments and in almost completely different ways. Therefore, we manually checked common and similar commands to create a map of similar commands into a single command. Furthermore, all file paths, domains, usernames, and indicators for CTAs are hidden by SCLC.5.1.2 SCLC Time Characteristics Generation Step
The data includes a timestamp of the command execution, so that the number of seconds between two consecutive commands can be easily determined. We then calculate the elapsed seconds for each consecutive command and insert it as a command between them. In this way, we simulate the waiting time between the words an author writes in his book, or in our case, the thought process of a threat actor before executing any command.5.1.3 SCLC Noise Analysis Step
In this step, any instruction execution sequences containing more than 32 instructions are divided into sequences with 32 instructions. The main reason for the division is to prepare a unified structure of instruction execution sequences, in other words, to handle the unbalanced distribution of instructions in instruction execution sequences. In addition, without any division, model training becomes infeasible, and the effects of the division are negligible.5.2 Architecture
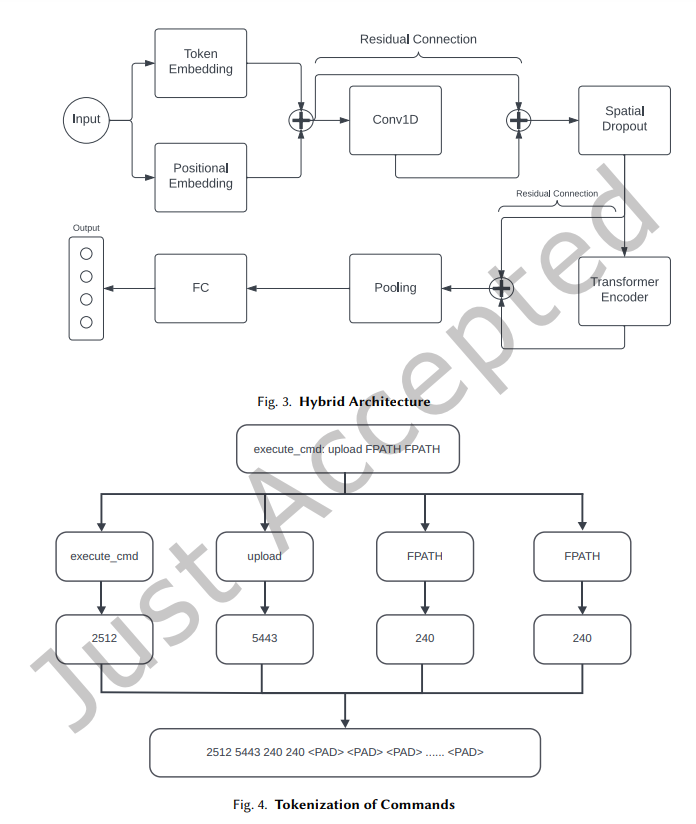
In this study, we use a hybrid deep learning framework that combines the capabilities of transformers and CNNs for CTA attribution. Our architecture is designed to capture both global and local contextual information in a command sequence. This is important because the significance of specific terms in commands can change significantly depending on the broader, global context. For example, a specific command used in one context may not help us attribute a CTA. However, when analyzing the relationship between other commands, that specific command may indicate the unique operational patterns of a specific CTA. Such insights require a hybrid architecture that can understand both the immediate environment of a term (local context) and the broader command sequence (global context).
5.3 Data preparation
We transform the given sequence of commands into numeric tokens so that our NLP architecture can understand and learn from these commands. As you can see in Figure 4, each unique word in the commands is extracted and mapped to a number, and then we replace each word in the processed data with the corresponding number. For example, the command in Figure 4 shows that the execute_cmd command is interpreted as the number 2512. Additionally, to make all our sequences the same length, we fix the maximum sequence length to the optimal number of tokens (in our case, 256) and pad shorter sequences to the maximum length by adding arbitrary tokens. Once tokenization is complete, our data is fully represented numerically.Experiments
6.1 Experimental environment
To build our experimental framework, we used the PyTorch deep learning library [18]. In addition, our study used several pre-trained transformer-based models, namely BERT, RoBERTa, SecureBERT, and DarkBERT. These models are implemented using the Transformers library from Hugging Face.Our dataset consists of command sequences of 34 threat actors. However, the size of the CTA data is not uniform. To handle the imbalance in the sizes of the datasets, we divided the CTAs into three categories: large volume, medium volume, and small volume. The experiments are conducted on these different-sized datasets using all the mentioned deep learning models to provide a comprehensive evaluation. Then, as explained earlier, the dataset is divided into a training set, which constitutes 70% of the data, a validation set, which constitutes 15%, and a test set, which constitutes the remaining 15%.
6.2 Tuning hyperparameters
For the pre-trained Transformer-based models, the hyperparameters to be tuned include the learning rate, the number of epochs to train the model, and weight decay. Moreover, for our hybrid architecture, the hyperparameters to be tuned include the dropout fraction, the number of epochs, the hidden size, the kernel size, the learning rate, filters, heads, and layers, which are tuned in the hyperparameter tuning phase.We conducted an extensive hyperparameter tuning process to optimize the performance of our models, and the best combination of hyperparameters was selected based on the validation F1 score. The best set of hyperparameters and its metrics for the pre-trained Transformer-based models can be seen in Table 5.
6.3 Cross-validation
Experiments conducted on datasets of varying sizes indicate a correlation between the number of command sequences in each CTA and the performance of deep learning models. In particular, we observe:- Large dataset: Models achieve significantly better results, with higher accuracy and F1 scores. Large dataset sizes allow models to learn complex patterns and generalize effectively.
- Medium Dataset: There is a moderate decline in performance metrics, with models facing some limitations in capturing CTA behavior with fewer command sequence examples.
- Small dataset: The models show lower performance, including lower accuracy and F1 scores. This is likely due to the insufficient data size, which prevents the model from learning patterns well in CTA with fewer command sequence examples.
Figure 9 shows the relationship between the dataset sizes and the performance metrics. These results highlight the importance of the dataset size for an effective model that detects CTAs. However, it is noteworthy that the hybrid architecture shows relatively good results in all dataset conditions. This shows the ability of the architecture to learn important features of CTAs from their instruction sequences and to generalize better under data-poor conditions. This resilience to data deficiencies makes the hybrid architecture much more important since data labels are often difficult to obtain in real-world applications.
Results
In this section, we detail the results obtained from a comprehensive evaluation of our hybrid deep learning architecture. The performance is compared with several established models based on pre-trained transformers.Experimental results
Table 8 displays the performance of the hybrid architecture on the test dataset across all dataset conditions after various experimental iterations. Including multiple hyperparameter tuning runs and 10-fold cross-validation to ensure the robustness of each model, optimal settings were achieved for each model. The models were then evaluated using test accuracy and F1 scores, providing a holistic view of their performance across all classes in our multi-class classification task.These results suggest that our hybrid deep learning architecture is the best-performing model among the other pre-trained models that were tested, both in terms of accuracy and F1 score.
Confusion Matrix Analysis
The confusion matrices for different dataset conditions provide valuable insights into the model performance by displaying the accuracy of architecture detection for each CTA. The confusion matrices for the hybrid architecture are shown in Figures 5, 6, and 7 for the high, medium, and low volume datasets, respectively. It is noteworthy that the number of command sequences for each CTA is sorted in descending order. For example, CTA#1 has the highest number of commands.As can be seen in Figure 5 for the high volume dataset, the hybrid architecture demonstrates good performance on almost all CTAs. The high values on the diagonal indicate that the model effectively classifies instances for each class. In Figure 6, a relatively balanced performance is observed for the medium volume dataset. Although the diagonal elements are strong, indicating good classification, there is room for improvement, for example, for CTA #6. The low volume dataset shown in Figure 7 demonstrates a more challenging scenario. Although the model performs well for most CTAs, it is observed that the model struggles with CTAs with fewer command sequences.
These results highlight the importance of dataset size for an effective model that detects CTAs. However, it is worth noting that the hybrid architecture shows relatively good results across all dataset conditions. This demonstrates the ability of the architecture to learn important features of CTAs from their instruction sequences and to generalize better under data-poor conditions. This robustness to data-poor conditions makes the hybrid architecture much more important, as data labels are often difficult to obtain in real-world applications.
Limitations and Future Work
Limitations
It is important to recognize that in cyberspace, attackers are constantly changing their style to hide their signatures and characteristics, or even using open frameworks to blend into the noise. It is still unclear whether this model will be able to predict with high accuracy if Evil Corp switches to another malware, but there is still much to be learned in this area of research.It is also important to understand that the process of attributing a threat actor does not solely rely on the sequence of commands that the actor executes. There are many traits and methods that should be considered when making attribution, meaning that our model should not be the sole source for the process, but should be considered as a guide.
Due to the nature of our experiments and the fact that we did not have access to real victims but mainly used honeypots, our dataset consists only of commands executed by the attacker. This method of selectively collecting data inherently introduces a sampling bias, as it does not capture commands from legitimate users that are typically present in real datasets. As a result, our model has a bias towards attacker commands, which raises doubts about its effectiveness in real-world scenarios. More research is needed to mitigate this bias and improve the applicability of the model to real-world scenarios. This could include simulating more authentic datasets by including legitimate user commands or using real user and attacker command datasets if they become publicly available.
Future Research
We suggest exploring other factors that influence threat actor behavior and tactics. For example, a promising avenue for future research could be to investigate the correlation between specific command sequences and broader strategic goals of CTAs. It would be interesting to explore whether a particular attack type is more prevalent in the presence of a particular CTA. Additionally, it is important to note that this research can help address evolving threats; by analyzing CTAs and their unique style, new threats and their relationships can also be further explored. Furthermore, it is important to gain more insight into how deep learning models determine threat actor attribution. In future research, we intend to examine the decision-making processes of these models, which may reveal distinct patterns and behaviors they associate with specific CTAs. By interpreting trained models, researchers and analysts can gain valuable insights that may not be immediately apparent from manual analysis.Conclusion
In our study, we presented a new approach to attributing cyber threat actors (CTAs) based on the command sequences they execute. This study is based on a unique intersection of natural language processing (NLP) and deep learning architectures, effectively distinguishing between different CTAs with high performance. We developed a standardized command language converter for CTA command sequence data, which effectively mitigates the overfitting problem by converting syntactic differences in commands into a unified format. This improvement significantly improves the performance of our deep learning architecture.Our hybrid deep learning architecture has proven its power to capture local and global contextual information in command sequences, outperforming well-known pre-trained Transformer-based models such as BERT, RoBERTa, SecureBERT, and DarkBERT. The hybrid architecture achieved an F1-score of 95.11% and an accuracy of 95.13% on the high-volume dataset, an F1-score of 93.60% and an accuracy of 93.77% on the medium-volume dataset, and an F1-score of 88.95% and an accuracy of 89.25% on the low-volume dataset. These results highlight the potential of integrating CNNs and Transformers mechanisms in challenging NLP tasks, especially in the cybersecurity domain.
Our study yielded several key findings that provide significant insights into cybersecurity. First, we found that our approach can significantly reduce the workload of cybersecurity analysts by providing a systematic and automated means of CTA attribution. By applying our method, analysts are freed from the burden of manually tracking down threat origins, allowing them to focus their expertise and efforts on more pressing or strategic tasks. In addition, this automation not only increases productivity, but also reduces the risk of human error by providing a starting point for the threat actor attribution process.
With this knowledge, it becomes much more feasible to create more effective countermeasures and defense strategies. Unique defense strategies can be developed based on the commands of a specific CTA. For example, understanding a CTA’s preference for certain command sequences or attack vectors can guide the design of specific intrusion detection rules or firewall configurations. Likewise, knowledge of CTA behavior patterns can also inform incident response plans, allowing for quick and effective action in the event of a security breach.
Furthermore, our study contributes to a deeper understanding of the modus operandi of specific CTAs. This fine-grained understanding equips cybersecurity professionals with valuable knowledge to predict potential targets and anticipate attack patterns, enabling proactive rather than reactive defense strategies. Moreover, our work opens up many exciting avenues for future research in the fields of cyber threat intelligence and digital forensics. This includes exploring a deeper understanding of CTA behavior and the relationship between command sequences and CTA strategic intent. These studies may lead to a more nuanced and thorough understanding of CTAs and their motivations.
Our study highlights the power and potential of NLP methods and deep learning architectures in solving complex digital forensics problems. Our work represents an important step towards an era where automated intelligence systems play a central role in strengthening our cybersecurity infrastructure and simplifying digital forensics and incident response tasks by introducing a new method of CTA attribution. The path forward is filled with promising opportunities for innovative and cutting-edge research in cyber defense and cyber threat intelligence.
References
- Ehsan Aghaei, Xi Niu, Waseem Shadid, and Ehab Al-Shaer. 2022. Securebert: a domain-specific language model for cybersecurity. In International Conference on Security and Privacy in Communication Systems. Springer, 39–56.
- Aylin Caliskan, Fabian Yamaguchi, Edwin Dauber, Richard Harang, Konrad Rieck, Rachel Greenstadt, and Arvind Narayanan. 2015. When coding style survives compilation: de-anonymizing programmers from executable binaries. arXiv preprint arXiv:1512.08546.
- Cybersecurity and Infrastructure Security Agency (CISA). 2023. #Stopransomware: royal ransomware. (2023). https://www.cisa.gov/news-events/cybersecurity-advisories/aa23-061a .
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: pre-training of deep bidirectional transformers for language understanding. (2018).
- Juan Andres Guerrero-Saade. 2018. Draw me like one of your French apts—expanding our descriptive palette for cyber threat actors. In Virus Bulletin Conference, Montreal, 1–20.
- Xueyuan Han, Thomas Pasquier, Adam Bates, James Mickens, and Margo Seltzer. NDSS 2020. Unicorn: runtime provenance-based detector for advanced persistent threats. (NDSS 2020). doi: 10.14722/ndss.2020.24046.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep residual learning for image recognition. (2015). arXiv: 1512.03385 [cs.CV].
- Health Sector Cybersecurity Coordination Center. 2022. Hc3 threat profile: evil corp. US Department of Health and Human Services. (2022). https://www.hhs.gov/sites/default/files/evil-corp-threat-profile.pdf .
- Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation, 9, 8, 1735–1780. doi: 10.1162/neco.1997.9.8.1735.
- Ehtsham Irshad and Abdul Basit Siddiqui. 2023. Cyber threat attribution using unstructured reports in cyber threat intelligence. Egyptian Informatics Journal, 24, 1, 43–59.
- Youngjin Jin, Eugene Jang, Jian Cui, Jin-Woo Chung, Yongjae Lee, and Seungwon Shin. 2023. Darkbert: a language model for the dark side of the internet. (2023). arXiv: 2305.08596 [cs.CL].
- Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. nature, 521, 7553, 436–444.
- Yann LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. 1989. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1, 4, 541–551. doi: 10.1162/neco.1989.1.4.541.
- Yinhan Liu et al. 2019. Roberta: a robustly optimized bert pretraining approach. (2019).
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Sadegh M. Milajerdi, Rigel Gjomemo, Birhanu Eshete, R. Sekar, and V. N. Venkatakrishnan. 2019. Holmes: real-time apt detection through correlation of suspicious information flows. (2019). arXiv: 1810.01594 [cs.CR].
- Umara Noor, Zahid Anwar, Tehmina Amjad, and Kim-Kwang Raymond Choo. 2019. A machine learning-based fintech cyber threat attribution framework using high-level indicators of compromise. Future Generation Computer Systems, 96, 227–242.
- Adam Paszke et al. 2019. Pytorch: an imperative style, high-performance deep learning library. (2019). arXiv: 1912.01703 [cs.LG].
- Lior Perry, Bracha Shapira, and Rami Puzis. 2019. No-doubt: attack attribution based on threat intelligence reports. In 2019 IEEE International Conference on Intelligence and Security Informatics (ISI) , 80–85. doi: 10.1109/ISI.2019.8823152.
- Avi Pfeffer et al. 2012. Malware analysis and attribution using genetic information. In 2012 7th International Conference on Malicious and Unwanted Software, 39–45. doi: 10.1109/MALWARE.2012.6461006.
- PRODAFT. 2022. [ws] wizard spider group in-depth analysis. (2022). https://www.prodaft.com/resource/detail/ws-wizard-spider-group-depth-analysis .
- PRODAFT. 2021. Silverfish: global cyber espionage campaign case report. (2021). https://www.prodaft.com/resource/detail/silverfish-global-cyber-espionage-campaign-case-report .
- Nathan Rosenblum, Xiaojin Zhu, and Barton P. Miller. 2011. Who wrote this code? identifying the authors of program binaries. In Computer Security - ESORICS 2011. Vijay Atluri and Claudia Diaz, (Eds.) Springer Berlin Heidelberg, Berlin, Heidelberg, 172–189. isbn: 978-3-642-23822-2.
- Naveen S, Rami Puzis, and Kumaresan Angappan. 2020. Deep learning for threat actor attribution from threat reports. In 2020 4th International Conference on Computer, Communication and Signal Processing (ICCCSP) , 1–6. doi: 10.1109/ICCCSP49186.2020.9315219.
- Md Sahrom, S. Rahayu, Aswami Ariffin, and Y. Robiah. 2018. Cyber threat intelligence – issue and challenges. Indonesian Journal of Electrical Engineering and Computer Science, 10, (Apr. 2018), 371–379. doi: 10.11591/ijeecs.v10.i1.pp371-379.
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15, 1, 1929–1958.
- Jonathan Thompson, Ross Goroshin, Arjun Jain, Yann LeCun, and ******************************opher Bregler. 2015. Efficient object localization using convolutional networks. (2015). arXiv: 1411.4280 [cs.CV].
- Antonio Torralba and Alexei A Efros. 2011. Unbiased look at dataset bias. In CVPR 2011. IEEE, 1521–1528.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.