
Friend
Professional
- Messages
- 2,677
- Reaction score
- 1,095
- Points
- 113
Эта статья представляет собой описание эксперимента по созданию системы обнаружения мошеннических платежей по банковским картам.
В первой части статьи я расскажу почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во второй части будут описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В третьей части будет рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения и наиболее интеллектуальную часть системы – аналитическую систему распознания мошеннических платежей.
Стремительный рост количества операций с пластиковыми картами, совершаемых через интернет, ставит перед разработчиками систем приема online-платежей все новые и новые вызовы, связанные с ростом масштаба таких систем и усложнением подходов к обеспечению их надежности и безопасности.
Не менее интенсивно растет количество мошеннических операций и разнообразие видов мошенничества. Россия, наряду с Англией, Францией, Германией, Испанией, входит в топ-5 европейский стран по годовому объему мошеннических операций с банковским картами. Общий объем потерь от мошенничества по картам в 2013 году в Европе превысило 1 млрд. евро. На Россию приходится 110 млн. евро, из них 2,4 млн. евро мошенничество при оплате через интернет.
Полная цепочка участников проведения online-платежа при покупке товара/услуги через интернет в общем случае выглядит приблизительно так:
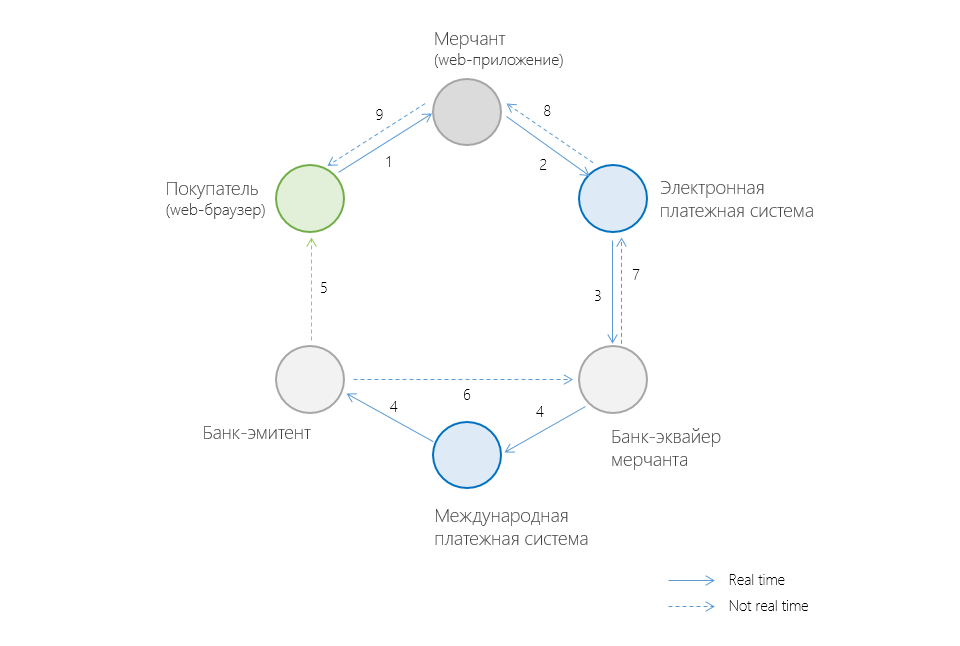
[+] Кто есть кто?Мерчант – продавец товара/услуги, представляет собой веб-приложение, в котором клиент может оплатить товар/услугу.
Клиент – покупатель, оплачивающий товара/услугу на сайте мерчанта с помощью своей банковской карты (или другим доступным образом).
Электронная платежная система (ПС) – сервис, принимающий оплату электронными деньгами, банковскими картами (и не только) через Интернет (примеры ПС: Яндекс.Деньги, WebMoney).
Банк-эквайер – банк, предоставляющий услуги по обработке платежей по банковским картам;
Международная платежная система (МПС) – система расчетов между банками разных стран, которые используют единые стандарты платежных средств. Примеры МПС: Visa, Master Card, American Express.
Банк-эмитент — банк выпустивший банковскую карту, которой клиент пытается оплатить товар/услугу.
Проблема
Проблема мошеннических транзакций (фрод, от англ. fraud) затрагивает всех участников этой цепочки: от покупателей до банка, выпустившего клиенту карту (банк-эмитент). Для всех участников за исключением держателей карт мошеннические транзакции подразумевают как значительные финансовые издержки, так и репутационные риски. Для ecommerce-отрасли в целом фрод также имеет ощутимые негативные последствия – это как недополученная прибыль, так и недоверие со стороны интернет-пользователей, что, в свою очередь, препятствует более широкому распространения электронных платежей.
Таким образом, наличие системы распознания мошеннических платежей (antifraud-система) для любого серьезного участника проведения online-платежа (опять же, кроме покупателя) – рыночная необходимость. В то же время хорошая антифрод-система – это чаще всего «долго, дорого…», сложности.
Сложности решения
Финансовые сложности: стоимость разработки vs штрафы за фрод
И если для банка затраты на антифрод-системы – это, в масштабах бизнеса, вполне приемлемая сумма; для платежной системы – составная часть бизнес-процесса; то мерчанты часто не имеют финансовой возможности и/или понимания, как создавать и поддерживать подобные системы.
Но и игнорировать фрод мерчант не может: деньги за мошеннические платежи в лучшем случае просто не достанутся мерчанту (даже если услуга уже оказана), в худшем – мерчант еще и будет оштрафован. Размер штрафа, в общем случае, начинает с 10$ и растет пропорционально объему мошеннических транзакций. Кроме того, при большом количестве фрода МПС (Visa, MasterCard) могут наложить (не побоюсь этого слова) санкции на мерчанта.
Эффективным способом снижения затрат на стороне мерчанта может быть введение дополнительных сложностей проверок для клиента и делегирование части/всех обязанностей проверки на фрод другому участнику. Наиболее распространенным способом является 3-D Secure (делегирование обязанности проверки банку-эмитенту).
[+] 3-D Secure3-D Secure – протокол, добавляющий дополнительный уровень безопасности для онлайн-кредитных и дебетовых карт. По сути представляет собой двухфакторную аутентификацию владельца карты.
Но стоит учитывать, что добавление таких шагов, требующих от пользователя дополнительных действий, нередко ведут драматическому снижению количества успешно завершенных транзакций (@Gremnix озвучивал цифру снижения количества успешных платежей в 20-25% при включении 3-D Secure для России).
Юридические сложности
В процессе разработки антифрод-системы неизбежно придется столкнуться с такой ответственной сферой как защита клиентских и платежных данных, а также с формальной частью этого вопроса – сертификации по одному из уровней PCI DSS.
[+] О стандарте PCI PSSPCI DSS (Payment Card Industry Data Security Standard) – стандарт безопасности данных индустрии платёжных карт, представляющий собой список требований по обеспечению безопасности хранения и передачи платежных данных. Для тех, кого интересуют детали стандарта: Official PCI Security Standards Council Site.
При разработке антифрод-системы необходимо также учитывать некоторые законодательные ограничения на хранение/обмен платежных и персональных данных клиента. В России это «О персональных данных» (152-ФЗ). Подробнее положений этого закона коснемся позже при рассмотрении программной архитектуры сервиса.
Технические сложности
Антифрод-система является business-critical системой, т.к. ее простой будет вести либо к остановке бизнес-процесса, либо, при некорректной работе системы, к увеличению рисков финансовых потерь для компании.
Отсюда повышенные требования к надежности работы, безопасности хранения данных, отказоустойчивости, масштабируемости системы.
В команде, занимающейся разработкой антифрод-системы, можно выделить следующие роли и сферы ответственности этих ролей:
Преимущества мерчанта
Во всей цепочке проведения online-платежа мерчант находится в одном из наиболее сложных положений: мерчант в отличие от покупателя отвечает за фрод собственными средствами, и в то же время, в отличие от банка зачастую не обладает достаточными ресурсами для эффективного противодействия мошенничеству.
Но у мерчанта есть и преимущество – уникальная информация о покупателе товара/услуги, которая чаще всего недоступна другим участникам online-платежа (например, банку эмитенту или МПС). Так ECN-площадки с большой вероятностью обладают реальным именем плательщика; интернет-магазины, предлагающие услугу доставки, с большой вероятностью знают реальную страну, город проживания плательщика и т.д.
Имя, фамилия владельца учетной записи, время существования учетной записи, количество ранее совершенных успешных платежей через сайт мерчанта, информация о хосте, с которого пришел http-запрос, информация о браузере – это лишь короткий перечень той информации, которая нередко доступна мерчанту и которая способна значительно улучшить эффективность поиска мошеннических транзакций.
Продолжение следует…
Мы рассмотрели основные аспекты проблемы мошеннических платежей. Очевидно, что недостаточное внимание к мошенническим платежам ведет к значительным финансовым издержкам. В то же время разработка полноценной антифрод-системы требует финансовых затрат как на инфраструктуру, так и на оплату работы команды специалистов с довольно редкими компетенциями.
В следующих частях статьи будет проведен эксперимент, целью которого будет создать распределенную высокомасштабируемую отказоустойчивую систему обнаружения мошеннических платежей.
Доступна antifraud-система будет как web-сервис и будет предусмотрена возможность подключения к сервису сторонних мерчантов. Финансовой целью будет сделать разработку сервиса на порядок(и) дешевле за счет применения ряда подходов, ведущих к значительному снижению первоначальных финансовых затрат на оборудование и ПО, сокращению количества специалистов и затраченных человеко-часов.
Подробности эксперимента, описание программной архитектуры сервиса и детальный разбор наиболее критичных модулей будут описаны в следующих частях статьи.
Антифрод. Функциональные и нефункциональные требования (часть 2)
В первой части эксперимента было описано, почему проблема мошеннических платежей (fraud) стоит остро перед всеми участниками рынка online-платежей, какие сложности на пути создания собственной системы мониторинга мошеннических платежей (antifraud-системы) предстоит преодолеть, и почему для большинства мерчантов такие системы – дорогое удовольствие, за которое они не всегда готовы платить.
Еще одно, усложняющее разработку подобных систем, обстоятельство — то, что antifraud-система является business-critical системой и ее простой будет вести либо к остановке бизнес-процесса (приема оплаты), либо при некорректной работе системы к увеличению рисков финансовых и репутационных потерь для компании (интернет-магазина, банка).
Поэтому практики и подходы, перечисленные в статье применимы не только на стороне мерчанта, но на стороне других участников интернет-эквайринга – агрегаторов, платежных систем, банков. Более того, перечисленные в статье подходы зачастую являются закрытыми от сообщества best practices в соответствующих организациях.
В этой части будут описаны требования к antifraud-системе, чье влияние на программную архитектуру является существенным.
Нефункциональные требования
Атрибуты качества
[+] Про выбор атрибутов качестваНе буду растягивать описание объяснением, почему я включил те иные атрибуты качества, так как такое объяснение носит очевидный характер, если принять во внимание тип проектируемой системы – business critical.
Кроме того, я намеренно не буду указывать конкретных цифр по времени доступности antifraud-системы и другим атрибутам качества, так как статья не ставит перед собой целью обсуждение отдельно взятой системы. Вместо этого описывается набор подходов и принципов, лежащих в основе подобных систем.
Атрибуты качества:
Законодательные ограничения
Законодательные ограничения, являются одним из важных факторов, определяющих программную архитектуру антифрод-системы.
Так, согласно требованиям стандарта PCI DSS, нельзя хранить полный номер карты (PAN)* или код безопасности (CVV). Разрешено хранить первые шесть и последние четыре цифры карты. Также ничто не запрещает генерировать внутренний уникальный идентификатор для карт клиентов. Имя держателя и срок экспирации карты разрешено передать только по защищенным каналам.
[+] * О хранении номера PANНа самом деле на высоком уровне (где-то на 80-ом сертификации стандарта PCI DSS разрешается хранить PAN в зашифрованном виде.
Кроме требования стандарта PCI DSS необходимо выполнять положения закона «О персональных данных» (152-ФЗ).
Обсуждение всего многообразия технико-бюрократических процедур (с вытекающими юридическими тонкостями), необходимых просто для хранения, обработки фамилии, имени клиента, скорее всего, займет 10 листов инструкций и 1,5 месяца работы на реализацию этих инструкций (шутка, но отчасти). Поэтому лучший способ не создавать себе лишней работы соблюдать положения 152-ФЗ – не попадать под его действие.
В проектируемой антифрод-системе все программные модули будут работать с деперсонифицированными данными.
Подытожив, ограничения, носящие юридический характер, добавим к системе следующие требования:
Функциональные требования
Требование к API
Для начала рассмотрим требования к системе с точки зрения внешнего мира, т.е. программных клиентов (мерчантов). Программные клиенты взаимодействует с антифрод-системой в соответствии со следующими требованиями к API:
Функциональные:
Нефункциональные:
Бизнес-требования
С точки зрения внутренней логики антифрод-системы выделим всего одно существенное бизнес-требование: предсказать по данным о платеже будет ли транзакция успешной.
В процессе реализации этого требования попытаемся доказать, что платеж не пройдет. Рассмотрим основные причины отказа в проведении транзакции: платежные данные сформированы некорректно или транзакция является мошеннической. Ниже разберем методы проверки каждой из перечисленных причин.
Проверка корректности введения платежных данных
Не стоит надеяться, что мерчант надлежащим образом проверит платежные данные. Вне зависимости от того была ли это ошибка пользовательского ввода или злонамеренные действия, выявление ошибок в платежных реквизитах на ранних этапах поможет сэкономить как такты CPU, так и предотвратить зашумление обучаемой модели (о ней речь еще пойдет позже).
Необходимо проверить содержит ли имя держателя карты хотя бы 2 буквы (тире и цифры в имени приемлемы), является ли карта действующей (у карты есть срок действия), проходит ли номер карты проверку алгоритмом Луна.
[+] Алгоритм ЛунаАлгоритм Луна (Luhn algorithm) — алгоритм вычисления контрольной цифры номера пластиковой карт. Предназначен для выявления ошибок, вызванных непреднамеренным искажением данных. Позволяет лишь с некоторой степенью достоверности судить об отсутствии ошибок в номере карты.
Проверка является ли транзакция мошеннической
Для выявления признака, что платеж является мошенническим, существует большое количество эвристик. Некоторые компании могут похвастаться цифрой под 200 эвристик. Хотя у меня сразу возникают подозрения, что некоторые из этих эвристик либо ничем не подкреплены, либо являются следствием какой-то другой эвристики, либо это вовсе костыль, позволяющий лучше подгонять результат под обучающую выборку и не дающий никакого эффекта на реальных данных. Большое количество эвристик дает лишь: переобученную модель, неправильное распознавание является ли транзакция мошеннической и уменьшение производительности приложения.
Поэтому перечислю лишь основные и, в общем случае, наиболее эффективные эвристики:
Часто основным подходом является наивное присвоение фиксированного значения для какого-то из фильтров и последующая обработка этих условий в конструкциях типа (это псевдокод, а не 1С):
Code:
if (количество_карт_с_одного_ip > 4) {
статус_платежа = отклонен;
return;
}
else {
if (количество_покупок_с_карты_за_1_час > 5) {
статус_платежа = отклонен;
return;
}
else {
// continuation magic…
}
}
// проведение платежа…
Даже не хочу начинать перечислять недостатки такого подхода и конечную стоимость такого кода, которая сложится из потерь от ложных срабатываний на отклонение «порядочных» платежей и пропуск фрода при небольшой смене стратегии мошенниками.
Поэтому единственно верным решением будет разработать систему, в которой эвристические фильтры способны к самообучению как на накопленной истории платежей, так и на новых платежах. Тут на наш выбор будет сразу несколько алгоритмов машинного обучения: логистическая регрессия, метод опорных векторов, нейронные сети.
Глобальные фильтры
Глобальными фильтрами я называю списки, при наличии плательщика в которых, проводить все остальные проверки – валидность платежных данных, проверка на фрод – бессмысленно. К таким спискам я отношу блэклисты банковских карт, IP, стран, мерчантов.
Глобальные фильтры могут быть как статическими, так и динамическими, могут быть связанны как с бизнес-правилами (мерчант не принимает платежи из Арктики), так и с детектированием аномальной активности (IP адрес).
Заключение 2-ой части
В первых двух частях мы рассмотрели основные аспекты преимущественно нетехнического характера, которые необходимо учесть при проектировании и разработке системы распознания мошеннических платежей.
Мы собираемся создать отказоустойчивый высокомасштабируемый надежный antifraud-сервис, который «снаружи» будет открыт для программных клиентов через REST API (https), а «внутри» – содержать логику, основанную на методах машинного обучения. Для придания еще большей интриги скажу, что сервис будет работать на одной из публичных облачных платформ.
В следующей части мы, наконец, займемся делом рассмотрим программную архитектуру antifraud-сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
---------- Сообщение добавлено в 09:24 PM ---------- Предыдущее сообщение размещено в 09:23 PM ----------
Это третья часть эксперимента по созданию системы распознания мошеннических платежей (antifraud-система). Целью является создание доступного (в плане стоимости разработки и владения) antifraud-сервиса, который позволит сразу нескольким участникам проведения online-платежей – мерчантам, агрегаторам, платежным системам, банкам – снизить риски проведения мошеннических платежей (fraud) через их площадки.
В прошлой части мы сфокусировали внимание на функциональных и нефункциональных требованиях к антифрод-сервису. В этой части статьи рассмотрим программную архитектуру сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
(с)Antifraud in azure
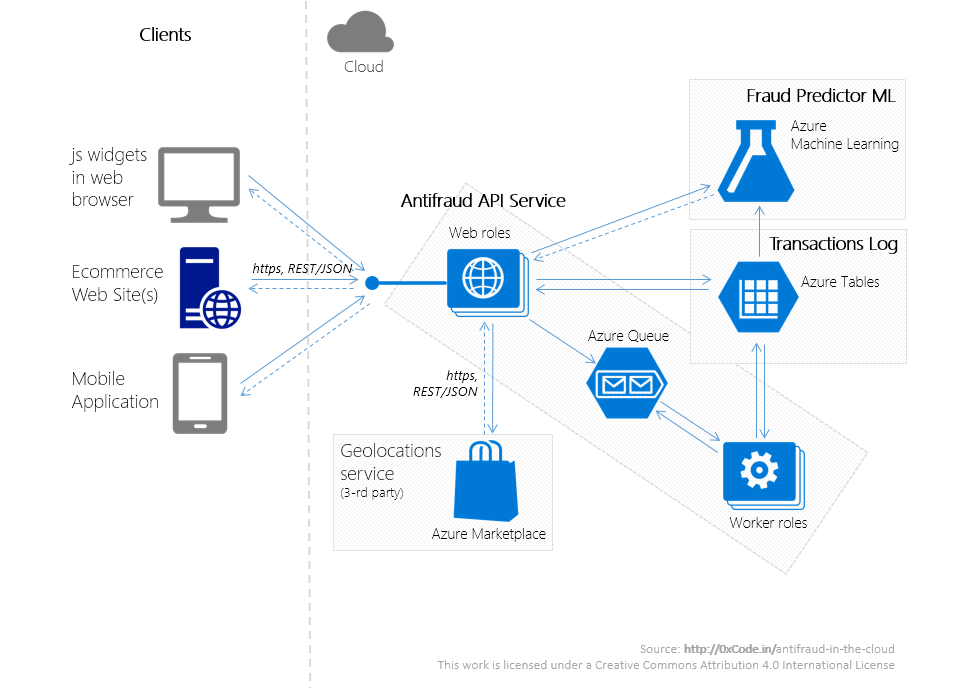
Инфраструктура
Сервис представляет собой несколько приложений, работающих в Microsoft Azure. Размещение с использованием облачной платформы вместо on-premise размещения не только позволит при незначительных временных затратах разработать сервис, отвечающий всем требованиям, перечисленным во второй части в разделе «Нефункциональные требования -> Атрибуты качества», но и существенно снизит первоначальные финансовые затраты на аппаратное и программное обеспечение.
Антифрод-сервис состоит из следующих систем:
Кроме того, у сервиса имеются многочисленные программные клиенты (Clients), представляющие собой web-приложения мерчантов, либо js-виджеты, вызывающие REST-сервисы Antifraud API Service.
Принципиальная схема взаимодействия этих систем проиллюстрирована выше.
Используемые архитектурные паттерны
Инфраструктура, наряду с предметной областью и законодательными актами, потенциально несет в себе большое количество ограничений, который должны быть учтены на архитектурном уровне. И если доменные и юридические ограничения мы уже обсудили в предыдущих частях статьи, то преимущества и ограничения, связанные с выбором облачной платформы Microsoft Azure обсудим ниже.
Используемые антифрод-системой сервисы Azure – Cloud service для web-/worker-ролей, Azure Table, Azure Queue, Azure ML, etc. – кроме почти нулевых начальных финансовых затрат на инфрастуктуру дают следующие преимущества из коробки:
В качестве бонусов я рассматриваю:
Необходимо также держать в голове, что у всех облачных сервисов есть ограничения:
Взаимодействие между компонентами сервиса
Для мерчанта сервис представляет собой REST-сервис, с которым можно взаимодействовать по протоколу https – Antifraud API Service. Antifraud API Service работает в кластере, состоящем из нескольких stateless web-ролей (web-роль в Azure – слой приложения, выполняющий роль веб-приложения).
Следующая диаграмма последовательностей описывает возможные взаимодействия мерчанта со всеми подсистемами антифрод-сервиса.

Рассмотрим каждый из шагов подробнее.
Запрос от мерчанта поступает на Контроллер (в терминах MVC) (Шаг 1). После чего полученная Модель (в терминах MVC) проходит:
1. трансформацию из модели контроллера в доменный объект;
2. запрос к внешним геолокационным сервисам (Azure Marketplace), с целью узнать страну по индексу плательщика и страну по IP хоста, с которого пришел запрос на снятие средств с карты;
3. этап проверки через глобальные фильтры;
4. этап проверки на валидность платежных данных;
5. предварительный анализ полученной транзакции – считаем эвристики для таймфреймов 5 секунд, 1 минута, 24 часа;
6. сокрытие личных данных покупателя и платежных данных – хэшируются имя владельца карты, имя владельца эккаунта на сайте мерчанта, адрес плательщика, телефон, email.
7. удаляем ненужные данные – например, данные о сроке действия карты после шага 4 не понадобятся.
Эвристики, глобальные фильтры и признаки валидности платежных данных были подробно обсуждены в предыдущей части статьи.
На шаге 2 объект предметной области трансформируется в DTO-объект, который:
1. передается в сервис Fraud Predictor ML (шаг 3);
2. после получения ответа от Fraud Predictor ML (шаг 4) информация о транзакции и ее результате сохраняется в лог транзакций (шаг 5) (о нем чуть ниже);
3. возвращаем клиенту ответ о предсказанном результате платежа (мошеннический или нет).
Для улучшения качества работы алгоритма предсказания клиентам доступен API уточнения результатов транзакции. Так, если реальный результат проведения платежа отличался от значения, которое вернул наш антифрод-сервис, мерчант может сообщить об этом, отправив запрос на уточнение результатов транзакций (шаг 9). Такие запросы:
Из очереди запросы забираются одним из роботов, представляющих собой stateless worker-роль (worker-роль – в Azure это слой приложения, выполняющий роль обработчика).
Хранилище транзакций
Как информация о транзакциях, так и дополнительная информация по ним (в основном статистика) сохраняется в лог транзакций – долговременное хранилище на основе Azure Table (сервис, представляющий собой отказоустойчивое NoSQL-хранилище (key-value)).
Лог транзакция представляет собой 2 таблицы:
Подробнее вопроса обучения модели обнаружения мошеннических платежей коснемся в следующей заключительной части.
Заключение 3-ей части
В этой части мы обсудили архитектуру антифрод-сервиса, выделили в нем функциональные части – Antifraud API Service, Fraud Predictor ML, Transactions Log, определили их зоны ответственности, а также способы взаимодействия между собой.
При правильном подходе к архитектуре развертывание антифрод-сервиса в облаке Microsoft Azure позволит существенно сократить первоначальные финансовые затраты на инфраструктуру, а также уменьшить время, затраченное на вопросы, связанные с масштабируемостью системы, надежным хранением данных и высокой доступностью сервисов.
В следующей заключительной части мы продолжим создавать антифрод-сервис, на порядок более дешевый по стоимости разработки и владения, чем его аналоги – разработаем сервис Fraud Predictor ML, который базируется на сервисе Azure Machine Learning и является аналитическим ядром антифрод-сервиса.
---------- Сообщение добавлено в 09:25 PM ---------- Предыдущее сообщение размещено в 09:24 PM ----------
В заключительной четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения часть antifraud-сервиса – аналитическую систему распознания мошеннических платежей по банковским картам.
Выявление различного рода мошенничеств является типичным кейсом для задач обучения с учителем (supervised learning), поэтому аналитическая часть антифрод-сервиса, в соответствии с лучшими отраслевыми практиками, будет построена с использованием алгоритмов машинного обучения.
Для стоящей перед нами задачи воспользуемся Azure Machine Learning – облачным сервисом выполнения задач прогнозной аналитики (predictive analytics). Для понимания статьи будут необходимы базовые знания в области машинного обучения и знакомство с сервисом Azure Machine Learning.
[+] Что уже было сделано? (для тех, кто не читал предыдущие 3 части, но интересуется)В первой части статьи мы обсудили, почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во 2-ой части были описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В 3-ей части была рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В заключительной четвертой части у нас следующая цель…
Цель
В этой части я опишу проект, на первом шаге которого мы обучим четыре модели, используя логистическую регрессию, персептрон, метод опорных векторов и дерево решений. Из обученных моделей выберем ту, которая дает большую точность на тестовой выборке и опубликуем ее в виде REST/JSON-сервиса. Далее для полученного сервиса напишем программного клиента и проведем нагрузочное тестирование на REST-сервис.
Создание модели
Создадим новый эксперимент в Azure ML Studio. В конечном виде он будет выглядеть так, как показано на иллюстрации ниже. Соотнесем каждый элемент эксперимента с этапом последовательности, который среднестатистический data scientist проделывает в процессе обучения модели.
Azure ML experiment
Рассмотрим каждый из этапов создания модели распознания мошеннических платежей, принимая во внимания технические детали, описанные в прошлой 3-ей части статьи.
Гипотеза
Основные концепции и предположения, полезные для создания модели, были обсуждены в первых 2-ух частях статьи. Повторяться не буду, лишь отмечу, что создание хорошей гипотезы – это итеративный процесс проб и ошибок, фундаментом для которого являются знания как в исследуемой предметной области, так и в области Data Science.
Получение данных
Набором данных для модели распознания мошеннических платежей будет являться лог транзакций, который состоит из 2-ух таблиц в NoSQL-хранилище (Azure Table): таблицы фактов о транзакциях TransactionsInfo и таблицы с предварительно рассчитанными статистическими метриками TransactionsStatistics.
На этапе получения данных загрузим эти 2 таблицы через элемент управления Reader.
Подготовка и исследование данных
Сделаем Inner Join загруженных таблиц по полю TransactionId. C помощь элемента управления Metadata Editor укажем типы данных (string, integer, timestamp), отметим столбец с ответами (label) и столбцы с предикторами (features), а также тип шкалы у этих данных: номинальные, абсолютные.
Не стоит недооценивать важность подготовки для создания адекватной модели: приведу простой пример с валютой платежа, которая храниться в виде ISO-кодов (целочисленное значение). ISO-коды – имеет номинальную (классификационную) шкалу. Но вряд ли стоит надеяться, что система автоматически определит, что в столбце «Currency» хранится не целочисленное значение с абсолютной шкалой (т.е. возможны такие операции как + или >). Потому что это слишком неочевидное правило, знаниями о котором система не обладает.
Набор данных может содержать пропущенные значения. В нашем случае, страну или IP-адрес плательщика не всегда есть возможность определить, такие поля могут содержать пустые значения. Проверив имеющийся набор данных, заменим пустые значения стран на «undefined» с помощью элемента управления Clean Missing Data. С помощью этого же элемента управления удалим строки, где в поле держатель карты, сумма платежа или валюта не содержатся значения, как строки, содержащие заведомо некорректные данные, то есть вносящие шум в модель.
На следующем этапе избавимся от неиспользуемых в модели полей: адрес (нас интересует только совпала ли страна плательщика со страной, откуда пришел запрос), хэш имени держателя карта (т.к. не имеет никакого влияния на результат платежа), RowId и PartitionId (служебные данные, попавшие к нам из Azure Table).
В заключении с помощью элемента управления Normalize Data проведем ZScore-нормализацию данных, содержащих большие числовые значения, такие как сумма платежа (столбец TransactionAmount).
Деление данных
Поделим получившийся набор данных на обучающую и тестовую выборку. Выберем оптимальное соотношение данных в обучающей выборки и в тестовой. Для наших целей с помощью элемента управления Split «отправим» 70% всех имеющихся данных в обучающую выборку, дополнительно включив произвольное смешивание данных (флаг Randomized split) при делении на поднаборы данных. Смешивание данных при делении позволит избежать «перекосов» в обучающей выборке, связанных с большими утечками номеров пластиковых карт (и, как следствие, аномальной активностью фрод-роботов в этой период).
Построение и оценка модели
Инициализируем несколько алгоритмов классификации и сравним какой из них дает лучший результат (точность) на тестовой выборке. Важно отметить, что совсем не факт, что на реальных данных будет достигнута та же производительность, что и тестовых данных. Поэтому очень важно понять, что в модели было не учтено, почему один из алгоритмов дает существенно худший или лучший результат, исправить ошибки и запустить алгоритм обучения заново. Этот процесс, заканчивается тогда, когда исследователь получает приемлемую по точности модель.
Azure ML позволяет нам подключать в одном эксперименте неограниченное количество алгоритмов машинного обучения. Это дает возможность на этапе исследования сравнить производительность нескольких алгоритмов с целью выявления того, который из них наилучшим образом подходит для нашей задачи. В нашем эксперименте мы используем несколько алгоритмов двуклассовой классификации: Two-Class Logistic Regression (логистическая регрессия), Two-Class Boosted Decision Tree (дерево решений, построенное методом градиентного роста), Two-Class Support Vector Machine (метод опорных векторов), Two-Class Neural Network (нейросеть).
Еще одна возможность получить лучшую производительность модели – настроить алгоритм машинного обучения, используя большое число параметров доступных для настройки алгоритма. Так для алгоритма Two-Class Boosted Decision Tree было указано количество деревьев, которое необходимо построить, а также минимальное/максимальное количество листьев на каждом дереве; для алгоритма Two-Class Neural Network количество скрытых узлов, итераций обучения и начальные веса.
На заключительном этапе просмотрим выходные данные элемента управления Evaluate Model (команда Visualize из контекстного меню элемента) для каждого из алгоритмов.

antifraud evaluate model
Элемент управления Evaluate Model содержит матрицу неточностей (confusion matrix), рассчитанные показатели точности работы алгоритма Accuracy, Precision, Recall, F1 Score, AUC, графики ROC и Precision/Recall. Если говорить упрощенно, то мы выберем алгоритм, чьи значения Accuracy, Precision, AUC ближе к 1, график ROC сильнее вогнут в сторону оси Y как для обучающей, так и для тестовой выборки.
Кроме того, непроходимо посмотреть на изменение AUC в зависимости от устанавливаемого значения Threshold. В случае с фродом – это важно, так как стоимость нераспознанных мошеннической платежей (False Positive) намного выше, чем стоимость платежей, ошибочно принятых за фрод (False Negative).
В таких случаях необходимо выбирать значение Threshold отличное от значения по умолчанию 0,5.
При выборе наиболее подходящего алгоритма для получения оптимальной модели распознания фрода, кроме уровня Threshold, учтем и тот факт, что логику принятия решения для некоторых алгоритмов (например, дерево решений) возможно воспроизвести, а для некоторых нет (персептрон). Наличие такой возможности может быть критичным, если важно знать, почему по определенному прецеденту система приняла конкретное решение.
Лучшую точность показал алгоритм двуклассовой нейронной сети – Two-Class Neural Network (показатели точности показаны на иллюстрации выше), за ним алгоритм на основе деревьев решений — Two-Class Boosted Decision Tree.
Публикация модели как веб-сервиса
После того, как была получена модель, работающая с требуемой точностью, опубликуем наш эксперимент как веб-сервис. Операция публикации проходит по нажатию кнопки «Publish Web Service» в Azure ML Studio. Процесс создания веб-сервиса из эксперимента тривиален и его описание я пропущу.
В результате Azure ML развернет масштабируемый отказоустойчивый (SLA 99,95%) web-сервис. После публикации сервиса станет доступна страница документации по API сервиса – API help, которая кроме общего описания сервиса, описания форматов ожидаемых входных и выходных сообщений, содержит еще и примеры вызова сервиса на C#, Python и R.
Принцип вызова сервиса программным клиентом можно изобразить так.

Azure ML services.
Подключение к Azure ML web-сервису
Возьмем пример на C# из API help и, немного изменив его, вызовем web-сервис Azure ML.
Листинг 1. Вызов web-сервиса Azure ML
Code:
private async Task<RequestStatistics> InvokePredictorService(TransactionInfo transactionInfo, TransactionStatistics transactionStatistics)
{
Contract.Requires<ArgumentNullException>(transactionInfo != null);
Contract.Requires<ArgumentNullException>(transactionStatistics != null);
var statistics = new RequestStatistics();
var watch = new Stopwatch();
using (var client = new HttpClient())
{
var scoreRequest = new
{
Inputs = new Dictionary<string, StringTable>() {
{
"transactionInfo",
new StringTable()
{
ColumnNames = new []
{
#region Column name list
},
Values = new [,]
{
{
#region Column value list
}
}
}
},
},
GlobalParameters = new Dictionary<string, string>()
};
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", ConfigurationManager.AppSettings["FraudPredictorML:ServiceApiKey"]);
client.BaseAddress = new Uri("https://ussouthcentral.services.azureml.net/workspaces/<workspace_id>/services/<service_id>/execute?api-version=2.0&details=true");
watch.Start();
HttpResponseMessage response = await client.PostAsJsonAsync("", scoreRequest);
if (response.IsSuccessStatusCode)
await response.Content.ReadAsStringAsync();
statistics.TimeToResponse = watch.Elapsed;
statistics.ResponseStatusCode = response.StatusCode;
watch.Stop();
}
return statistics;
}
Получим следующие запрос/ответ:
Листинг 2.1. Запрос к web-сервису Azure ML
Code:
POST https://ussouthcentral.services.azureml.net/workspaces/<workspace_id>/services/<service_id>/execute?api-version=2.0&details=true HTTP/1.1
Authorization: Bearer <api key>
Content-Type: application/json; charset=utf-8
Host: ussouthcentral.services.azureml.net
/* другие заголовки */
{
"Inputs": {
"transactionInfo": {
"ColumnNames": [
"PartitionKey",
"RowKey",
"Timestamp",
"CardId",
"CrmAccountId",
"MCC",
"MerchantId",
"TransactionAmount",
"TransactionCreatedTime",
"TransactionCurrency",
"TransactionId",
"TransactionResult",
"CardExpirationDate",
"CardholderName",
"CrmAccountFullName",
"TransactionRequestHost",
"PartitionKey (2)",
"RowKey (2)",
"Timestamp (2)",
"CardsCountFromThisCrmAccount1D",
"CardsCountFromThisCrmAccount1H",
"CardsCountFromThisCrmAccount1M",
"CardsCountFromThisCrmAccount1S",
"CardsCountFromThisHost1D",
"CrmAccountsCountFromThisCard1D",
"FailedPaymentsCountByThisCard1D",
"SecondsPassedFromPreviousPaymentByThisCard1D",
"PaymentsCountByThisCard1D",
"HostsCountFromThisCard1D",
"HasHumanEmail",
"HasHumanPhone",
"IsCardholderNameIsTheSameAsCrmAccountName",
"IsRequestCountryIsTheSameAsCrmAccountCountry",
"TransactionDayOfWeek",
"TransactionLocalTimeOfDay"
/* значения прочие предикторы */
],
"Values": [
[
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"349567471",
"10145",
"32",
"990",
"136.69",
"2015-03-15T20:54:28.6508575Z",
"840",
"f31f64f367644b1cb173a48a34817fbc",
null,
"2015-04-15T23:44:28.6508575+03:00",
"640ab2bae07bedc4c163f679a746f7ab7fb5d1fa",
"640ab2bae07bedc4c163f679a746f7ab7fb5d1fa",
"20.30.30.40",
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"2",
"1",
"0",
"0",
"0",
"0",
"1",
"2",
"0",
"0",
"true",
null,
"true",
"true",
"Monday",
"Morning"
/* значения прочих предикторов */
]
]
}
},
"GlobalParameters": { }
}
Листинг 2.2. Ответ web-сервиса Azure ML
Code:
HTTP/1.1 200 OK
Content-Length: 1619
Content-Type: application/json; charset=utf-8
Server: Microsoft-HTTPAPI/2.0
x-ms-request-id: f8cb48b8-6bb5-4813-a8e9-5baffaf49e15
Date: Sun, 15 Mar 2015 20:44:31 GMT
{
"Results": {
"transactionPrediction": {
"type": "table",
"value": {
"ColumnNames": [
"PartitionKey",
"RowKey",
"Timestamp",
"CardId",
"CrmAccountId",
"MCC",
"MerchantId",
"TransactionAmount",
"TransactionCreatedTime",
"TransactionCurrency",
"TransactionId",
/* значения прочие предикторы */
"Scored Labels",
"Scored Probabilities"
],
"Values": [
[
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"349567471",
"10145",
"32",
"990",
"136.69",
"2015-03-15T20:54:28.6508575Z",
"840",
"f31f64f367644b1cb173a48a34817fbc",
/* значения прочих предикторов */
"Success",
"0.779961256980896"
]
]
}
}
}
}
Нагрузочное тестирование
Для целей нагрузочного тестирования воспользуемся IaaS-возможностями Azure – поднимем виртуальную машину (Instance A8: 8x CPU, 56Gb RAM, 40Gbit/s InfiniBand, Windows Server 2012 R2, $2.45/hr) в том же регионе (US Central South), в котором находиться наш Azure ML web-сервис. Запустим на VM задачу на ~20K запросов и посмотрим на результаты.
Листинг 3. Код клиента сервиса и задачи
Code:
/// <summary>
/// Entry point
/// </summary>
public void Main()
{
var client = new FraudPredictorMLClient();
RequestsStatistics invokeParallelStatistics = client.InvokeParallel(1024, 22);
LogResult(invokeParallelStatistics);
RequestsStatistics invokeAsyncStatistics = client.InvokeAsync(1024).Result;
LogResult(invokeAsyncStatistics);
}
private static void LogResult(RequestsStatistics statistics)
{
Contract.Requires<ArgumentNullException>(statistics != null);
Func<double, string> format = d => d.ToString("F3");
Log.Info("Results:");
Log.Info("Min: {0} ms", format(statistics.Min));
Log.Info("Average: {0} ms", format(statistics.Average));
Log.Info("Max: {0} ms", format(statistics.Max));
Log.Info("Count of failed requests: {0}", statistics.FailedRequestsCount);
}
/// <summary>
/// Client for FraudPredictorML web-service
/// </summary>
public class FraudPredictorMLClient
{
/// <summary>
/// Async invocation of method
/// </summary>
/// <param name="merchantId">Merchant id</param>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
public async Task<RequestsStatistics> InvokeAsync(int merchantId)
{
Contract.Requires<ArgumentOutOfRangeException>(merchantId > 0);
IEnumerable<TransactionInfo> tis = null; IEnumerable<TransactionStatistics> tss = null;
// upload input data
Parallel.Invoke(
() => tis = new TransactionsInfoRepository().Get(merchantId),
() => tss = new TransactionsStatisticsRepository().Get(merchantId)
);
var inputs = tis
.Join(tss, ti => ti.TransactionId, ts => ts.TransactionId, (ti, ts) => new { TransactionInfo = ti, TransactionStatistics = ts })
.ToList();
// send requests
var statistics = new List<RequestStatistics>(inputs.Count);
foreach (var input in inputs)
{
RequestStatistics stats = await InvokePredictorService(input.TransactionInfo, input.TransactionStatistics).ConfigureAwait(false);
statistics.Add(stats);
}
// return result
return new RequestsStatistics(statistics);
}
/// <summary>
/// Parallel invocation of method (for load testing purposes)
/// </summary>
/// <param name="merchantId">Merchant id</param>
/// <param name="degreeOfParallelism">Count of parallel requests</param>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
public RequestsStatistics InvokeParallel(int merchantId, int degreeOfParallelism)
{
Contract.Requires<ArgumentOutOfRangeException>(merchantId > 0);
Contract.Requires<ArgumentOutOfRangeException>(degreeOfParallelism > 0);
IEnumerable<TransactionInfo> tis = null; IEnumerable<TransactionStatistics> tss = null;
// upload input data
Parallel.Invoke(
() => tis = new TransactionsInfoRepository().Get(merchantId),
() => tss = new TransactionsStatisticsRepository().Get(merchantId)
);
var inputs = tis
.Join(tss, ti => ti.TransactionId, ts => ts.TransactionId, (ti, ts) => new { TransactionInfo = ti, TransactionStatistics = ts })
.ToList();
// send requests
var statistics = new List<RequestStatistics>(inputs.Count);
for (int i = 0; i < inputs.Count; i = i + degreeOfParallelism)
{
var tasks = new List<Task<RequestStatistics>>();
for (int j = i; j < i + degreeOfParallelism; j++)
{
if (inputs.Count <= j) break;
var input = inputs[j];
tasks.Add(InvokePredictorService(input.TransactionInfo, input.TransactionStatistics));
}
Task.WaitAll(tasks.ToArray());
statistics.AddRange(tasks.Select(t => t.Result));
}
// return result
return new RequestsStatistics(statistics);
}
/* other members */
}
Вызов InvokeParallel():
Лучшее время ответа: 421.683 ms
Худшее время: 1355.516 ms
Среднее время: 652.935 ms
Количество успешных запросов: 20061
Количество отказов: 956
Вызов InvokeAsync():
Лучшее время ответа: 478.102 ms
Худшее время: 1344.348 ms
Среднее время: 605.911 ms
Количество успешных запросов: 21017
Количество отказов: 0
Ограничения (потенциальные)
Бутылочным горлышком разрабатываемой системы, на первый взгляд, будет являться Azure ML. Поэтому крайне важно понимать ограничения Azure ML в общем и web-сервисов Azure ML, в частности. Но по данному вопросу очень мало как официальной документации, так и результатов, полученных от community.
Так остается открытым вопрос с throttled policy конечных точек web-сервиса Azure ML: не ясно максимальное значение параллельных запросов web-сервису Azure ML (эмпирически проверена цифра 20 параллельных запросов на одну конечную точку), а также максимальный размер принимаемого сообщения (актуального для пакетного режима работы сервиса).
Менее актуально, но стоит вопрос с максимальным размером входных данных (Criteo Labs разместили датасет на 1 Тб данных), максимальным количеством предикторов и прецедентов, которые можно отдать на вход алгоритму машинного обучения в Azure ML.
Критически важно сократить время ответа веб-сервиса FraudPredictorML, а также время переобучения модели до минимальных значений, но пока нет никаких официальных рекомендаций по тому, как это возможно сделать (и возможно ли вообще).
Рекомендации клиентам
Антифрод-сервис никак не ограничивает клиентов как в предварительной проверке платежей, так и в последующей интерпретации результатов предсказания. Предварительные специфичные для бизнес-процесса проверки, а также окончательное принятие решения о принятии/отклонение платежа – это задачи, которые явно выходят из зоны ответственности антифрод-сервиса.
В независимости о роли клиента – интернет-магазин, платежная система или банк – для клиентов существуют следующие рекомендации:
[+] Рекомендации для комментирующихВ рамках этого цикла статей мы касались проблематики вопроса, юридической и технической стороны проблемы. Это техническая статья, она не преследует собой цели создать бизнес-план, сравнить с решениями конкурентов, вычислить дисконтированную стоимость проекта. Со всеми этими вопросами на РБК – не ко мне, не в это хаб, и, есть подозрение, даже не на этот сайт.
Заключение
В этом цикле, состоящем из 4-ех статей, мы провели эксперимент по проектированию и разработке высокомасштабируемого отказоустойчивого надежного antifraud-сервиса, работающего в near real-time режиме, с открытым для внешних программным клиентов REST/JSON API.
Применение алгоритмов машинного обучения (дерево решений, нейросети) позволили создать аналитическую систему, способную к самообучению как на накопленной истории, так и на новых платежах. Благодаря использованию PaaS-/IaaS-сервисов удалось сократить первоначальные финансовые затраты на инфраструктуру и ПО практически до нуля. Наличие у разработчика компетенций в предметной области, data science, архитектуре распределенных систем помогло драматически снизить количество участников команды разработки.
В результате менее чем за 60 человеко-часов и с минимальными начальными затратами на инфраструктуру (<$150, которые были покрыты из подписки MSDN) удалось создать ядро антифрод-системы.
Получившийся сервис, конечно, требует еще тщательной проверки (и последующего исправления) основных модулей, более тонкой настройки работы классификатора(ов), разработки серии вспомогательных подсистем, интереса и (что тут греха таить) инвестиций. Но и несмотря на указанные выше недоработки, сервис на порядок (и больше) эффективнее аналогичных разработок в отрасли как с точки зрения стоимости разработки, так и с точки зрения стоимости владения.
В первой части статьи я расскажу почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во второй части будут описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В третьей части будет рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения и наиболее интеллектуальную часть системы – аналитическую систему распознания мошеннических платежей.
Get Started!
Антифрод. Быстро, дешево… отлично (часть 1)
Стремительный рост количества операций с пластиковыми картами, совершаемых через интернет, ставит перед разработчиками систем приема online-платежей все новые и новые вызовы, связанные с ростом масштаба таких систем и усложнением подходов к обеспечению их надежности и безопасности.
Не менее интенсивно растет количество мошеннических операций и разнообразие видов мошенничества. Россия, наряду с Англией, Францией, Германией, Испанией, входит в топ-5 европейский стран по годовому объему мошеннических операций с банковским картами. Общий объем потерь от мошенничества по картам в 2013 году в Европе превысило 1 млрд. евро. На Россию приходится 110 млн. евро, из них 2,4 млн. евро мошенничество при оплате через интернет.
Полная цепочка участников проведения online-платежа при покупке товара/услуги через интернет в общем случае выглядит приблизительно так:
[+] Кто есть кто?Мерчант – продавец товара/услуги, представляет собой веб-приложение, в котором клиент может оплатить товар/услугу.
Клиент – покупатель, оплачивающий товара/услугу на сайте мерчанта с помощью своей банковской карты (или другим доступным образом).
Электронная платежная система (ПС) – сервис, принимающий оплату электронными деньгами, банковскими картами (и не только) через Интернет (примеры ПС: Яндекс.Деньги, WebMoney).
Банк-эквайер – банк, предоставляющий услуги по обработке платежей по банковским картам;
Международная платежная система (МПС) – система расчетов между банками разных стран, которые используют единые стандарты платежных средств. Примеры МПС: Visa, Master Card, American Express.
Банк-эмитент — банк выпустивший банковскую карту, которой клиент пытается оплатить товар/услугу.
Проблема
Проблема мошеннических транзакций (фрод, от англ. fraud) затрагивает всех участников этой цепочки: от покупателей до банка, выпустившего клиенту карту (банк-эмитент). Для всех участников за исключением держателей карт мошеннические транзакции подразумевают как значительные финансовые издержки, так и репутационные риски. Для ecommerce-отрасли в целом фрод также имеет ощутимые негативные последствия – это как недополученная прибыль, так и недоверие со стороны интернет-пользователей, что, в свою очередь, препятствует более широкому распространения электронных платежей.
Таким образом, наличие системы распознания мошеннических платежей (antifraud-система) для любого серьезного участника проведения online-платежа (опять же, кроме покупателя) – рыночная необходимость. В то же время хорошая антифрод-система – это чаще всего «долго, дорого…», сложности.
Сложности решения
Финансовые сложности: стоимость разработки vs штрафы за фрод
И если для банка затраты на антифрод-системы – это, в масштабах бизнеса, вполне приемлемая сумма; для платежной системы – составная часть бизнес-процесса; то мерчанты часто не имеют финансовой возможности и/или понимания, как создавать и поддерживать подобные системы.
Но и игнорировать фрод мерчант не может: деньги за мошеннические платежи в лучшем случае просто не достанутся мерчанту (даже если услуга уже оказана), в худшем – мерчант еще и будет оштрафован. Размер штрафа, в общем случае, начинает с 10$ и растет пропорционально объему мошеннических транзакций. Кроме того, при большом количестве фрода МПС (Visa, MasterCard) могут наложить (не побоюсь этого слова) санкции на мерчанта.
Эффективным способом снижения затрат на стороне мерчанта может быть введение дополнительных сложностей проверок для клиента и делегирование части/всех обязанностей проверки на фрод другому участнику. Наиболее распространенным способом является 3-D Secure (делегирование обязанности проверки банку-эмитенту).
[+] 3-D Secure3-D Secure – протокол, добавляющий дополнительный уровень безопасности для онлайн-кредитных и дебетовых карт. По сути представляет собой двухфакторную аутентификацию владельца карты.
Но стоит учитывать, что добавление таких шагов, требующих от пользователя дополнительных действий, нередко ведут драматическому снижению количества успешно завершенных транзакций (@Gremnix озвучивал цифру снижения количества успешных платежей в 20-25% при включении 3-D Secure для России).
Юридические сложности
В процессе разработки антифрод-системы неизбежно придется столкнуться с такой ответственной сферой как защита клиентских и платежных данных, а также с формальной частью этого вопроса – сертификации по одному из уровней PCI DSS.
[+] О стандарте PCI PSSPCI DSS (Payment Card Industry Data Security Standard) – стандарт безопасности данных индустрии платёжных карт, представляющий собой список требований по обеспечению безопасности хранения и передачи платежных данных. Для тех, кого интересуют детали стандарта: Official PCI Security Standards Council Site.
При разработке антифрод-системы необходимо также учитывать некоторые законодательные ограничения на хранение/обмен платежных и персональных данных клиента. В России это «О персональных данных» (152-ФЗ). Подробнее положений этого закона коснемся позже при рассмотрении программной архитектуры сервиса.
Технические сложности
Антифрод-система является business-critical системой, т.к. ее простой будет вести либо к остановке бизнес-процесса, либо, при некорректной работе системы, к увеличению рисков финансовых потерь для компании.
Отсюда повышенные требования к надежности работы, безопасности хранения данных, отказоустойчивости, масштабируемости системы.
В команде, занимающейся разработкой антифрод-системы, можно выделить следующие роли и сферы ответственности этих ролей:
- эксперт в предметной области: платежные системы, банковские системы, оплата через интернет, юридические ньансы работы таких систем;
- архитектор: проектирование высокодоступного надежного (лучше еще и распределенного и масштабируемого) приложения;
- разработчик: высокоуровневый язык программирования, асинхронное и многопоточное программирование, хорошая математическая подготовка;
- data scientist: исследователь, любит данные и математику;
- project manager (куда ж без них): координация разработки.
Преимущества мерчанта
Во всей цепочке проведения online-платежа мерчант находится в одном из наиболее сложных положений: мерчант в отличие от покупателя отвечает за фрод собственными средствами, и в то же время, в отличие от банка зачастую не обладает достаточными ресурсами для эффективного противодействия мошенничеству.
Но у мерчанта есть и преимущество – уникальная информация о покупателе товара/услуги, которая чаще всего недоступна другим участникам online-платежа (например, банку эмитенту или МПС). Так ECN-площадки с большой вероятностью обладают реальным именем плательщика; интернет-магазины, предлагающие услугу доставки, с большой вероятностью знают реальную страну, город проживания плательщика и т.д.
Имя, фамилия владельца учетной записи, время существования учетной записи, количество ранее совершенных успешных платежей через сайт мерчанта, информация о хосте, с которого пришел http-запрос, информация о браузере – это лишь короткий перечень той информации, которая нередко доступна мерчанту и которая способна значительно улучшить эффективность поиска мошеннических транзакций.
Продолжение следует…
Мы рассмотрели основные аспекты проблемы мошеннических платежей. Очевидно, что недостаточное внимание к мошенническим платежам ведет к значительным финансовым издержкам. В то же время разработка полноценной антифрод-системы требует финансовых затрат как на инфраструктуру, так и на оплату работы команды специалистов с довольно редкими компетенциями.
В следующих частях статьи будет проведен эксперимент, целью которого будет создать распределенную высокомасштабируемую отказоустойчивую систему обнаружения мошеннических платежей.
Доступна antifraud-система будет как web-сервис и будет предусмотрена возможность подключения к сервису сторонних мерчантов. Финансовой целью будет сделать разработку сервиса на порядок(и) дешевле за счет применения ряда подходов, ведущих к значительному снижению первоначальных финансовых затрат на оборудование и ПО, сокращению количества специалистов и затраченных человеко-часов.
Подробности эксперимента, описание программной архитектуры сервиса и детальный разбор наиболее критичных модулей будут описаны в следующих частях статьи.
Антифрод. Функциональные и нефункциональные требования (часть 2)
В первой части эксперимента было описано, почему проблема мошеннических платежей (fraud) стоит остро перед всеми участниками рынка online-платежей, какие сложности на пути создания собственной системы мониторинга мошеннических платежей (antifraud-системы) предстоит преодолеть, и почему для большинства мерчантов такие системы – дорогое удовольствие, за которое они не всегда готовы платить.
Еще одно, усложняющее разработку подобных систем, обстоятельство — то, что antifraud-система является business-critical системой и ее простой будет вести либо к остановке бизнес-процесса (приема оплаты), либо при некорректной работе системы к увеличению рисков финансовых и репутационных потерь для компании (интернет-магазина, банка).
Поэтому практики и подходы, перечисленные в статье применимы не только на стороне мерчанта, но на стороне других участников интернет-эквайринга – агрегаторов, платежных систем, банков. Более того, перечисленные в статье подходы зачастую являются закрытыми от сообщества best practices в соответствующих организациях.
В этой части будут описаны требования к antifraud-системе, чье влияние на программную архитектуру является существенным.
Нефункциональные требования
Атрибуты качества
[+] Про выбор атрибутов качестваНе буду растягивать описание объяснением, почему я включил те иные атрибуты качества, так как такое объяснение носит очевидный характер, если принять во внимание тип проектируемой системы – business critical.
Кроме того, я намеренно не буду указывать конкретных цифр по времени доступности antifraud-системы и другим атрибутам качества, так как статья не ставит перед собой целью обсуждение отдельно взятой системы. Вместо этого описывается набор подходов и принципов, лежащих в основе подобных систем.
Атрибуты качества:
- распределенность;
- отказоустойчивость;
- высокая масштабируемость;
- надежность.
Законодательные ограничения
Законодательные ограничения, являются одним из важных факторов, определяющих программную архитектуру антифрод-системы.
Так, согласно требованиям стандарта PCI DSS, нельзя хранить полный номер карты (PAN)* или код безопасности (CVV). Разрешено хранить первые шесть и последние четыре цифры карты. Также ничто не запрещает генерировать внутренний уникальный идентификатор для карт клиентов. Имя держателя и срок экспирации карты разрешено передать только по защищенным каналам.
[+] * О хранении номера PANНа самом деле на высоком уровне (где-то на 80-ом сертификации стандарта PCI DSS разрешается хранить PAN в зашифрованном виде.
Кроме требования стандарта PCI DSS необходимо выполнять положения закона «О персональных данных» (152-ФЗ).
Обсуждение всего многообразия технико-бюрократических процедур (с вытекающими юридическими тонкостями), необходимых просто для хранения, обработки фамилии, имени клиента, скорее всего, займет 10 листов инструкций и 1,5 месяца работы на реализацию этих инструкций (шутка, но отчасти). Поэтому лучший способ не создавать себе лишней работы соблюдать положения 152-ФЗ – не попадать под его действие.
В проектируемой антифрод-системе все программные модули будут работать с деперсонифицированными данными.
Подытожив, ограничения, носящие юридический характер, добавим к системе следующие требования:
- не хранить PAN и CVV карты в любом виде;
- другие платежные данные хранить только в защищенном виде;
- передать информацию между мерчантом (программным клиентом) и антифрод-системой только по защищенным каналам связи;
- работать только с деперсонифицированными данными.
Функциональные требования
Требование к API
Для начала рассмотрим требования к системе с точки зрения внешнего мира, т.е. программных клиентов (мерчантов). Программные клиенты взаимодействует с антифрод-системой в соответствии со следующими требованиями к API:
Функциональные:
- Предоставить клиенту API для отправки данных о платеже;
- Вернуть клиенту результат предсказания является ли платеж мошенническим;
- Предоставить клиенту API для корректировки результатов проведения платежа.
Нефункциональные:
- Предоставить общедоступный протокол взаимодействия с клиентом;
- Вести взаимодействие с клиентом только по защищенным каналам связи.
Бизнес-требования
С точки зрения внутренней логики антифрод-системы выделим всего одно существенное бизнес-требование: предсказать по данным о платеже будет ли транзакция успешной.
В процессе реализации этого требования попытаемся доказать, что платеж не пройдет. Рассмотрим основные причины отказа в проведении транзакции: платежные данные сформированы некорректно или транзакция является мошеннической. Ниже разберем методы проверки каждой из перечисленных причин.
Проверка корректности введения платежных данных
Не стоит надеяться, что мерчант надлежащим образом проверит платежные данные. Вне зависимости от того была ли это ошибка пользовательского ввода или злонамеренные действия, выявление ошибок в платежных реквизитах на ранних этапах поможет сэкономить как такты CPU, так и предотвратить зашумление обучаемой модели (о ней речь еще пойдет позже).
Необходимо проверить содержит ли имя держателя карты хотя бы 2 буквы (тире и цифры в имени приемлемы), является ли карта действующей (у карты есть срок действия), проходит ли номер карты проверку алгоритмом Луна.
[+] Алгоритм ЛунаАлгоритм Луна (Luhn algorithm) — алгоритм вычисления контрольной цифры номера пластиковой карт. Предназначен для выявления ошибок, вызванных непреднамеренным искажением данных. Позволяет лишь с некоторой степенью достоверности судить об отсутствии ошибок в номере карты.
Проверка является ли транзакция мошеннической
Для выявления признака, что платеж является мошенническим, существует большое количество эвристик. Некоторые компании могут похвастаться цифрой под 200 эвристик. Хотя у меня сразу возникают подозрения, что некоторые из этих эвристик либо ничем не подкреплены, либо являются следствием какой-то другой эвристики, либо это вовсе костыль, позволяющий лучше подгонять результат под обучающую выборку и не дающий никакого эффекта на реальных данных. Большое количество эвристик дает лишь: переобученную модель, неправильное распознавание является ли транзакция мошеннической и уменьшение производительности приложения.
Поэтому перечислю лишь основные и, в общем случае, наиболее эффективные эвристики:
- одна карта – много IP, и обратный случай: один IP – много карт;
- одна карта – много покупок/неудачных попыток;
- один клиент – много карт (особенно эмитированных различными банками);
- один клиент – много индексов, email'ов;
- имя клиента не совпадает с именем владельца эккаунта на сайте мерчанта (если есть);
- страна клиента не совпадает со страной владельца эккаунта на сайте мерчанта (если есть);
- оплата происходит ночь (по локальному времени клиента).
Часто основным подходом является наивное присвоение фиксированного значения для какого-то из фильтров и последующая обработка этих условий в конструкциях типа (это псевдокод, а не 1С):
Code:
if (количество_карт_с_одного_ip > 4) {
статус_платежа = отклонен;
return;
}
else {
if (количество_покупок_с_карты_за_1_час > 5) {
статус_платежа = отклонен;
return;
}
else {
// continuation magic…
}
}
// проведение платежа…
Даже не хочу начинать перечислять недостатки такого подхода и конечную стоимость такого кода, которая сложится из потерь от ложных срабатываний на отклонение «порядочных» платежей и пропуск фрода при небольшой смене стратегии мошенниками.
Поэтому единственно верным решением будет разработать систему, в которой эвристические фильтры способны к самообучению как на накопленной истории платежей, так и на новых платежах. Тут на наш выбор будет сразу несколько алгоритмов машинного обучения: логистическая регрессия, метод опорных векторов, нейронные сети.
Глобальные фильтры
Глобальными фильтрами я называю списки, при наличии плательщика в которых, проводить все остальные проверки – валидность платежных данных, проверка на фрод – бессмысленно. К таким спискам я отношу блэклисты банковских карт, IP, стран, мерчантов.
Глобальные фильтры могут быть как статическими, так и динамическими, могут быть связанны как с бизнес-правилами (мерчант не принимает платежи из Арктики), так и с детектированием аномальной активности (IP адрес).
Заключение 2-ой части
В первых двух частях мы рассмотрели основные аспекты преимущественно нетехнического характера, которые необходимо учесть при проектировании и разработке системы распознания мошеннических платежей.
Мы собираемся создать отказоустойчивый высокомасштабируемый надежный antifraud-сервис, который «снаружи» будет открыт для программных клиентов через REST API (https), а «внутри» – содержать логику, основанную на методах машинного обучения. Для придания еще большей интриги скажу, что сервис будет работать на одной из публичных облачных платформ.
В следующей части мы, наконец, займемся делом рассмотрим программную архитектуру antifraud-сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
---------- Сообщение добавлено в 09:24 PM ---------- Предыдущее сообщение размещено в 09:23 PM ----------
Антифрод. Архитектура сервиса (часть 3)
Это третья часть эксперимента по созданию системы распознания мошеннических платежей (antifraud-система). Целью является создание доступного (в плане стоимости разработки и владения) antifraud-сервиса, который позволит сразу нескольким участникам проведения online-платежей – мерчантам, агрегаторам, платежным системам, банкам – снизить риски проведения мошеннических платежей (fraud) через их площадки.
В прошлой части мы сфокусировали внимание на функциональных и нефункциональных требованиях к антифрод-сервису. В этой части статьи рассмотрим программную архитектуру сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
(с)Antifraud in azure
Инфраструктура
Сервис представляет собой несколько приложений, работающих в Microsoft Azure. Размещение с использованием облачной платформы вместо on-premise размещения не только позволит при незначительных временных затратах разработать сервис, отвечающий всем требованиям, перечисленным во второй части в разделе «Нефункциональные требования -> Атрибуты качества», но и существенно снизит первоначальные финансовые затраты на аппаратное и программное обеспечение.
Антифрод-сервис состоит из следующих систем:
- Antifraud API Service – REST-сервис, предоставляющий API для взаимодействия с сервисом Fraud Predictor ML.
- Fraud Predictor ML – сервис обнаружения мошеннических платежей, в основе которого лежат алгоритмы машинного обучения.
- Transactions Log (лог транзакций) – NoSQL хранилище информации о транзакциях.
Кроме того, у сервиса имеются многочисленные программные клиенты (Clients), представляющие собой web-приложения мерчантов, либо js-виджеты, вызывающие REST-сервисы Antifraud API Service.
Принципиальная схема взаимодействия этих систем проиллюстрирована выше.
Используемые архитектурные паттерны
Инфраструктура, наряду с предметной областью и законодательными актами, потенциально несет в себе большое количество ограничений, который должны быть учтены на архитектурном уровне. И если доменные и юридические ограничения мы уже обсудили в предыдущих частях статьи, то преимущества и ограничения, связанные с выбором облачной платформы Microsoft Azure обсудим ниже.
Используемые антифрод-системой сервисы Azure – Cloud service для web-/worker-ролей, Azure Table, Azure Queue, Azure ML, etc. – кроме почти нулевых начальных финансовых затрат на инфрастуктуру дают следующие преимущества из коробки:
- высокая доступность: SLA не ниже 99,95%;
- надежность хранения: системы хранения данных с высокой избыточностью;
- безопасность хранения: сертификаты ISO 27001/27002 и другие, включая PCI DSS 3.0;
- отказоустойчивость: все рабочие узлы можно (рекомендуется) запускать в нескольких экземплярах;
- масштабируемость: возможно автоматическое масштабирование количества рабочих узлов в зависимости от нагрузки, партицирование таблиц NoSQL-хранилища на основе PartitionKey;
В качестве бонусов я рассматриваю:
- удобный мониторинг приложения;
- глубокая интеграция с Visual Studio.
- web/worker-узлы являются stateless;
- горизонтальное партицирование для хранения структурированных или полуструктурированных данных (Sharding Pattern [1]);
- сетевых взаимодействия происходят только асинхронно и только с применением retry-политик (Retry Pattern [1]);
- для выравнивания нагрузок и гарантированной обработки задач используются очереди сообщений (паттерн Queue-Based Load Leveling Pattern [1]).
- используем алгоритмы параллельные по данным (простейший и один из самых эффективных MapReduce);
- применяем подход Push'n'Forget для таких мест как сохранение единичной записи в лог транзакций (на точность работы алгоритма машинного обучения одна пропавшая запись из 10K успешных не окажет сильного влияния);
- избегаем блокировок лога транзакций (любых разделяемых ресурсов), что достигается добавлением поля timestamp к информации о транзакции;
- «убиваем» (или хотя бы что-то с ними делаем) долгие запросы.
Необходимо также держать в голове, что у всех облачных сервисов есть ограничения:
- как технического характера: наиболее частые из них максимальное количество запросов в секунду, максимальный размер сообщения;
- так и технологического характера: наиболее серьезное из них – поддерживаемые протоколы взаимодействия с PaaS-сервисами.
Взаимодействие между компонентами сервиса
Для мерчанта сервис представляет собой REST-сервис, с которым можно взаимодействовать по протоколу https – Antifraud API Service. Antifraud API Service работает в кластере, состоящем из нескольких stateless web-ролей (web-роль в Azure – слой приложения, выполняющий роль веб-приложения).
Следующая диаграмма последовательностей описывает возможные взаимодействия мерчанта со всеми подсистемами антифрод-сервиса.
Antifraud sequence diagram
- Шаг 1. Отправка запроса с информацией о платеже.
- Шаг 2. Трансформация Модели (в терминах MVC).
- Шаг 3. Отправка запроса на сервис предсказания результата платежа.
- Шаг 4. Возвращение результата – будет ли платеж успешным.
- Шаг 5. Сохранение данных.
- Шаг 6. Возвращение результата клиенту.
- Шаг 7, 8. Пересчет и обновление обучающей выборки, переобучение модели.
- Шаг 9-12 (опционально). Клиент инициирует отправку запроса с информацией о результате платежа (в случае, когда результат предсказания отличается от реального результата платежа, переданного в запросе).
Рассмотрим каждый из шагов подробнее.
Запрос от мерчанта поступает на Контроллер (в терминах MVC) (Шаг 1). После чего полученная Модель (в терминах MVC) проходит:
1. трансформацию из модели контроллера в доменный объект;
2. запрос к внешним геолокационным сервисам (Azure Marketplace), с целью узнать страну по индексу плательщика и страну по IP хоста, с которого пришел запрос на снятие средств с карты;
3. этап проверки через глобальные фильтры;
4. этап проверки на валидность платежных данных;
5. предварительный анализ полученной транзакции – считаем эвристики для таймфреймов 5 секунд, 1 минута, 24 часа;
6. сокрытие личных данных покупателя и платежных данных – хэшируются имя владельца карты, имя владельца эккаунта на сайте мерчанта, адрес плательщика, телефон, email.
7. удаляем ненужные данные – например, данные о сроке действия карты после шага 4 не понадобятся.
Эвристики, глобальные фильтры и признаки валидности платежных данных были подробно обсуждены в предыдущей части статьи.
На шаге 2 объект предметной области трансформируется в DTO-объект, который:
1. передается в сервис Fraud Predictor ML (шаг 3);
2. после получения ответа от Fraud Predictor ML (шаг 4) информация о транзакции и ее результате сохраняется в лог транзакций (шаг 5) (о нем чуть ниже);
3. возвращаем клиенту ответ о предсказанном результате платежа (мошеннический или нет).
Для улучшения качества работы алгоритма предсказания клиентам доступен API уточнения результатов транзакции. Так, если реальный результат проведения платежа отличался от значения, которое вернул наш антифрод-сервис, мерчант может сообщить об этом, отправив запрос на уточнение результатов транзакций (шаг 9). Такие запросы:
- имеют формат <transaction_id, transaction_result, last_update_time>;
- обрабатываются Merchant API Service и после валидации ставятся в Azure Queue (отказоустойчивый сервис очередей).
Из очереди запросы забираются одним из роботов, представляющих собой stateless worker-роль (worker-роль – в Azure это слой приложения, выполняющий роль обработчика).
Хранилище транзакций
Как информация о транзакциях, так и дополнительная информация по ним (в основном статистика) сохраняется в лог транзакций – долговременное хранилище на основе Azure Table (сервис, представляющий собой отказоустойчивое NoSQL-хранилище (key-value)).
Лог транзакция представляет собой 2 таблицы:
- таблицу с фактами о транзакции TransactionsInfo: id транзакции (Row Key), id мерчанта, хэш имени держателя карты (если доступен), сумма и валюта платежа и т.п.;
- таблицу с рассчитанными статистическими метриками TransactionsStatistics: сколько раз платили с этой карты (несколько таймфреймов), со скольких IP адресов, как временной интервал был между платежами, как давно зарегистрировался покупатель у мерчанта, сколько раз совершал успешные платежи и т.д.
Подробнее вопроса обучения модели обнаружения мошеннических платежей коснемся в следующей заключительной части.
Заключение 3-ей части
В этой части мы обсудили архитектуру антифрод-сервиса, выделили в нем функциональные части – Antifraud API Service, Fraud Predictor ML, Transactions Log, определили их зоны ответственности, а также способы взаимодействия между собой.
При правильном подходе к архитектуре развертывание антифрод-сервиса в облаке Microsoft Azure позволит существенно сократить первоначальные финансовые затраты на инфраструктуру, а также уменьшить время, затраченное на вопросы, связанные с масштабируемостью системы, надежным хранением данных и высокой доступностью сервисов.
В следующей заключительной части мы продолжим создавать антифрод-сервис, на порядок более дешевый по стоимости разработки и владения, чем его аналоги – разработаем сервис Fraud Predictor ML, который базируется на сервисе Azure Machine Learning и является аналитическим ядром антифрод-сервиса.
---------- Сообщение добавлено в 09:25 PM ---------- Предыдущее сообщение размещено в 09:24 PM ----------
Антифрод (часть 4): аналитическая система распознания мошеннических платежей.
В заключительной четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения часть antifraud-сервиса – аналитическую систему распознания мошеннических платежей по банковским картам.
Выявление различного рода мошенничеств является типичным кейсом для задач обучения с учителем (supervised learning), поэтому аналитическая часть антифрод-сервиса, в соответствии с лучшими отраслевыми практиками, будет построена с использованием алгоритмов машинного обучения.
Для стоящей перед нами задачи воспользуемся Azure Machine Learning – облачным сервисом выполнения задач прогнозной аналитики (predictive analytics). Для понимания статьи будут необходимы базовые знания в области машинного обучения и знакомство с сервисом Azure Machine Learning.
[+] Что уже было сделано? (для тех, кто не читал предыдущие 3 части, но интересуется)В первой части статьи мы обсудили, почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во 2-ой части были описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В 3-ей части была рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В заключительной четвертой части у нас следующая цель…
Цель
В этой части я опишу проект, на первом шаге которого мы обучим четыре модели, используя логистическую регрессию, персептрон, метод опорных векторов и дерево решений. Из обученных моделей выберем ту, которая дает большую точность на тестовой выборке и опубликуем ее в виде REST/JSON-сервиса. Далее для полученного сервиса напишем программного клиента и проведем нагрузочное тестирование на REST-сервис.
Создание модели
Создадим новый эксперимент в Azure ML Studio. В конечном виде он будет выглядеть так, как показано на иллюстрации ниже. Соотнесем каждый элемент эксперимента с этапом последовательности, который среднестатистический data scientist проделывает в процессе обучения модели.
Azure ML experiment
Рассмотрим каждый из этапов создания модели распознания мошеннических платежей, принимая во внимания технические детали, описанные в прошлой 3-ей части статьи.
Гипотеза
Основные концепции и предположения, полезные для создания модели, были обсуждены в первых 2-ух частях статьи. Повторяться не буду, лишь отмечу, что создание хорошей гипотезы – это итеративный процесс проб и ошибок, фундаментом для которого являются знания как в исследуемой предметной области, так и в области Data Science.
Получение данных
Набором данных для модели распознания мошеннических платежей будет являться лог транзакций, который состоит из 2-ух таблиц в NoSQL-хранилище (Azure Table): таблицы фактов о транзакциях TransactionsInfo и таблицы с предварительно рассчитанными статистическими метриками TransactionsStatistics.
На этапе получения данных загрузим эти 2 таблицы через элемент управления Reader.
Подготовка и исследование данных
Сделаем Inner Join загруженных таблиц по полю TransactionId. C помощь элемента управления Metadata Editor укажем типы данных (string, integer, timestamp), отметим столбец с ответами (label) и столбцы с предикторами (features), а также тип шкалы у этих данных: номинальные, абсолютные.
Не стоит недооценивать важность подготовки для создания адекватной модели: приведу простой пример с валютой платежа, которая храниться в виде ISO-кодов (целочисленное значение). ISO-коды – имеет номинальную (классификационную) шкалу. Но вряд ли стоит надеяться, что система автоматически определит, что в столбце «Currency» хранится не целочисленное значение с абсолютной шкалой (т.е. возможны такие операции как + или >). Потому что это слишком неочевидное правило, знаниями о котором система не обладает.
Набор данных может содержать пропущенные значения. В нашем случае, страну или IP-адрес плательщика не всегда есть возможность определить, такие поля могут содержать пустые значения. Проверив имеющийся набор данных, заменим пустые значения стран на «undefined» с помощью элемента управления Clean Missing Data. С помощью этого же элемента управления удалим строки, где в поле держатель карты, сумма платежа или валюта не содержатся значения, как строки, содержащие заведомо некорректные данные, то есть вносящие шум в модель.
На следующем этапе избавимся от неиспользуемых в модели полей: адрес (нас интересует только совпала ли страна плательщика со страной, откуда пришел запрос), хэш имени держателя карта (т.к. не имеет никакого влияния на результат платежа), RowId и PartitionId (служебные данные, попавшие к нам из Azure Table).
В заключении с помощью элемента управления Normalize Data проведем ZScore-нормализацию данных, содержащих большие числовые значения, такие как сумма платежа (столбец TransactionAmount).
Деление данных
Поделим получившийся набор данных на обучающую и тестовую выборку. Выберем оптимальное соотношение данных в обучающей выборки и в тестовой. Для наших целей с помощью элемента управления Split «отправим» 70% всех имеющихся данных в обучающую выборку, дополнительно включив произвольное смешивание данных (флаг Randomized split) при делении на поднаборы данных. Смешивание данных при делении позволит избежать «перекосов» в обучающей выборке, связанных с большими утечками номеров пластиковых карт (и, как следствие, аномальной активностью фрод-роботов в этой период).
Построение и оценка модели
Инициализируем несколько алгоритмов классификации и сравним какой из них дает лучший результат (точность) на тестовой выборке. Важно отметить, что совсем не факт, что на реальных данных будет достигнута та же производительность, что и тестовых данных. Поэтому очень важно понять, что в модели было не учтено, почему один из алгоритмов дает существенно худший или лучший результат, исправить ошибки и запустить алгоритм обучения заново. Этот процесс, заканчивается тогда, когда исследователь получает приемлемую по точности модель.
Azure ML позволяет нам подключать в одном эксперименте неограниченное количество алгоритмов машинного обучения. Это дает возможность на этапе исследования сравнить производительность нескольких алгоритмов с целью выявления того, который из них наилучшим образом подходит для нашей задачи. В нашем эксперименте мы используем несколько алгоритмов двуклассовой классификации: Two-Class Logistic Regression (логистическая регрессия), Two-Class Boosted Decision Tree (дерево решений, построенное методом градиентного роста), Two-Class Support Vector Machine (метод опорных векторов), Two-Class Neural Network (нейросеть).
Еще одна возможность получить лучшую производительность модели – настроить алгоритм машинного обучения, используя большое число параметров доступных для настройки алгоритма. Так для алгоритма Two-Class Boosted Decision Tree было указано количество деревьев, которое необходимо построить, а также минимальное/максимальное количество листьев на каждом дереве; для алгоритма Two-Class Neural Network количество скрытых узлов, итераций обучения и начальные веса.
На заключительном этапе просмотрим выходные данные элемента управления Evaluate Model (команда Visualize из контекстного меню элемента) для каждого из алгоритмов.
antifraud evaluate model
Элемент управления Evaluate Model содержит матрицу неточностей (confusion matrix), рассчитанные показатели точности работы алгоритма Accuracy, Precision, Recall, F1 Score, AUC, графики ROC и Precision/Recall. Если говорить упрощенно, то мы выберем алгоритм, чьи значения Accuracy, Precision, AUC ближе к 1, график ROC сильнее вогнут в сторону оси Y как для обучающей, так и для тестовой выборки.
Кроме того, непроходимо посмотреть на изменение AUC в зависимости от устанавливаемого значения Threshold. В случае с фродом – это важно, так как стоимость нераспознанных мошеннической платежей (False Positive) намного выше, чем стоимость платежей, ошибочно принятых за фрод (False Negative).
В таких случаях необходимо выбирать значение Threshold отличное от значения по умолчанию 0,5.
При выборе наиболее подходящего алгоритма для получения оптимальной модели распознания фрода, кроме уровня Threshold, учтем и тот факт, что логику принятия решения для некоторых алгоритмов (например, дерево решений) возможно воспроизвести, а для некоторых нет (персептрон). Наличие такой возможности может быть критичным, если важно знать, почему по определенному прецеденту система приняла конкретное решение.
Лучшую точность показал алгоритм двуклассовой нейронной сети – Two-Class Neural Network (показатели точности показаны на иллюстрации выше), за ним алгоритм на основе деревьев решений — Two-Class Boosted Decision Tree.
Публикация модели как веб-сервиса
После того, как была получена модель, работающая с требуемой точностью, опубликуем наш эксперимент как веб-сервис. Операция публикации проходит по нажатию кнопки «Publish Web Service» в Azure ML Studio. Процесс создания веб-сервиса из эксперимента тривиален и его описание я пропущу.
В результате Azure ML развернет масштабируемый отказоустойчивый (SLA 99,95%) web-сервис. После публикации сервиса станет доступна страница документации по API сервиса – API help, которая кроме общего описания сервиса, описания форматов ожидаемых входных и выходных сообщений, содержит еще и примеры вызова сервиса на C#, Python и R.
Принцип вызова сервиса программным клиентом можно изобразить так.
Azure ML services.
Подключение к Azure ML web-сервису
Возьмем пример на C# из API help и, немного изменив его, вызовем web-сервис Azure ML.
Листинг 1. Вызов web-сервиса Azure ML
Code:
private async Task<RequestStatistics> InvokePredictorService(TransactionInfo transactionInfo, TransactionStatistics transactionStatistics)
{
Contract.Requires<ArgumentNullException>(transactionInfo != null);
Contract.Requires<ArgumentNullException>(transactionStatistics != null);
var statistics = new RequestStatistics();
var watch = new Stopwatch();
using (var client = new HttpClient())
{
var scoreRequest = new
{
Inputs = new Dictionary<string, StringTable>() {
{
"transactionInfo",
new StringTable()
{
ColumnNames = new []
{
#region Column name list
},
Values = new [,]
{
{
#region Column value list
}
}
}
},
},
GlobalParameters = new Dictionary<string, string>()
};
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", ConfigurationManager.AppSettings["FraudPredictorML:ServiceApiKey"]);
client.BaseAddress = new Uri("https://ussouthcentral.services.azureml.net/workspaces/<workspace_id>/services/<service_id>/execute?api-version=2.0&details=true");
watch.Start();
HttpResponseMessage response = await client.PostAsJsonAsync("", scoreRequest);
if (response.IsSuccessStatusCode)
await response.Content.ReadAsStringAsync();
statistics.TimeToResponse = watch.Elapsed;
statistics.ResponseStatusCode = response.StatusCode;
watch.Stop();
}
return statistics;
}
Получим следующие запрос/ответ:
Листинг 2.1. Запрос к web-сервису Azure ML
Code:
POST https://ussouthcentral.services.azureml.net/workspaces/<workspace_id>/services/<service_id>/execute?api-version=2.0&details=true HTTP/1.1
Authorization: Bearer <api key>
Content-Type: application/json; charset=utf-8
Host: ussouthcentral.services.azureml.net
/* другие заголовки */
{
"Inputs": {
"transactionInfo": {
"ColumnNames": [
"PartitionKey",
"RowKey",
"Timestamp",
"CardId",
"CrmAccountId",
"MCC",
"MerchantId",
"TransactionAmount",
"TransactionCreatedTime",
"TransactionCurrency",
"TransactionId",
"TransactionResult",
"CardExpirationDate",
"CardholderName",
"CrmAccountFullName",
"TransactionRequestHost",
"PartitionKey (2)",
"RowKey (2)",
"Timestamp (2)",
"CardsCountFromThisCrmAccount1D",
"CardsCountFromThisCrmAccount1H",
"CardsCountFromThisCrmAccount1M",
"CardsCountFromThisCrmAccount1S",
"CardsCountFromThisHost1D",
"CrmAccountsCountFromThisCard1D",
"FailedPaymentsCountByThisCard1D",
"SecondsPassedFromPreviousPaymentByThisCard1D",
"PaymentsCountByThisCard1D",
"HostsCountFromThisCard1D",
"HasHumanEmail",
"HasHumanPhone",
"IsCardholderNameIsTheSameAsCrmAccountName",
"IsRequestCountryIsTheSameAsCrmAccountCountry",
"TransactionDayOfWeek",
"TransactionLocalTimeOfDay"
/* значения прочие предикторы */
],
"Values": [
[
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"349567471",
"10145",
"32",
"990",
"136.69",
"2015-03-15T20:54:28.6508575Z",
"840",
"f31f64f367644b1cb173a48a34817fbc",
null,
"2015-04-15T23:44:28.6508575+03:00",
"640ab2bae07bedc4c163f679a746f7ab7fb5d1fa",
"640ab2bae07bedc4c163f679a746f7ab7fb5d1fa",
"20.30.30.40",
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"2",
"1",
"0",
"0",
"0",
"0",
"1",
"2",
"0",
"0",
"true",
null,
"true",
"true",
"Monday",
"Morning"
/* значения прочих предикторов */
]
]
}
},
"GlobalParameters": { }
}
Листинг 2.2. Ответ web-сервиса Azure ML
Code:
HTTP/1.1 200 OK
Content-Length: 1619
Content-Type: application/json; charset=utf-8
Server: Microsoft-HTTPAPI/2.0
x-ms-request-id: f8cb48b8-6bb5-4813-a8e9-5baffaf49e15
Date: Sun, 15 Mar 2015 20:44:31 GMT
{
"Results": {
"transactionPrediction": {
"type": "table",
"value": {
"ColumnNames": [
"PartitionKey",
"RowKey",
"Timestamp",
"CardId",
"CrmAccountId",
"MCC",
"MerchantId",
"TransactionAmount",
"TransactionCreatedTime",
"TransactionCurrency",
"TransactionId",
/* значения прочие предикторы */
"Scored Labels",
"Scored Probabilities"
],
"Values": [
[
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"349567471",
"10145",
"32",
"990",
"136.69",
"2015-03-15T20:54:28.6508575Z",
"840",
"f31f64f367644b1cb173a48a34817fbc",
/* значения прочих предикторов */
"Success",
"0.779961256980896"
]
]
}
}
}
}
Нагрузочное тестирование
Для целей нагрузочного тестирования воспользуемся IaaS-возможностями Azure – поднимем виртуальную машину (Instance A8: 8x CPU, 56Gb RAM, 40Gbit/s InfiniBand, Windows Server 2012 R2, $2.45/hr) в том же регионе (US Central South), в котором находиться наш Azure ML web-сервис. Запустим на VM задачу на ~20K запросов и посмотрим на результаты.
Листинг 3. Код клиента сервиса и задачи
Code:
/// <summary>
/// Entry point
/// </summary>
public void Main()
{
var client = new FraudPredictorMLClient();
RequestsStatistics invokeParallelStatistics = client.InvokeParallel(1024, 22);
LogResult(invokeParallelStatistics);
RequestsStatistics invokeAsyncStatistics = client.InvokeAsync(1024).Result;
LogResult(invokeAsyncStatistics);
}
private static void LogResult(RequestsStatistics statistics)
{
Contract.Requires<ArgumentNullException>(statistics != null);
Func<double, string> format = d => d.ToString("F3");
Log.Info("Results:");
Log.Info("Min: {0} ms", format(statistics.Min));
Log.Info("Average: {0} ms", format(statistics.Average));
Log.Info("Max: {0} ms", format(statistics.Max));
Log.Info("Count of failed requests: {0}", statistics.FailedRequestsCount);
}
/// <summary>
/// Client for FraudPredictorML web-service
/// </summary>
public class FraudPredictorMLClient
{
/// <summary>
/// Async invocation of method
/// </summary>
/// <param name="merchantId">Merchant id</param>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
public async Task<RequestsStatistics> InvokeAsync(int merchantId)
{
Contract.Requires<ArgumentOutOfRangeException>(merchantId > 0);
IEnumerable<TransactionInfo> tis = null; IEnumerable<TransactionStatistics> tss = null;
// upload input data
Parallel.Invoke(
() => tis = new TransactionsInfoRepository().Get(merchantId),
() => tss = new TransactionsStatisticsRepository().Get(merchantId)
);
var inputs = tis
.Join(tss, ti => ti.TransactionId, ts => ts.TransactionId, (ti, ts) => new { TransactionInfo = ti, TransactionStatistics = ts })
.ToList();
// send requests
var statistics = new List<RequestStatistics>(inputs.Count);
foreach (var input in inputs)
{
RequestStatistics stats = await InvokePredictorService(input.TransactionInfo, input.TransactionStatistics).ConfigureAwait(false);
statistics.Add(stats);
}
// return result
return new RequestsStatistics(statistics);
}
/// <summary>
/// Parallel invocation of method (for load testing purposes)
/// </summary>
/// <param name="merchantId">Merchant id</param>
/// <param name="degreeOfParallelism">Count of parallel requests</param>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
public RequestsStatistics InvokeParallel(int merchantId, int degreeOfParallelism)
{
Contract.Requires<ArgumentOutOfRangeException>(merchantId > 0);
Contract.Requires<ArgumentOutOfRangeException>(degreeOfParallelism > 0);
IEnumerable<TransactionInfo> tis = null; IEnumerable<TransactionStatistics> tss = null;
// upload input data
Parallel.Invoke(
() => tis = new TransactionsInfoRepository().Get(merchantId),
() => tss = new TransactionsStatisticsRepository().Get(merchantId)
);
var inputs = tis
.Join(tss, ti => ti.TransactionId, ts => ts.TransactionId, (ti, ts) => new { TransactionInfo = ti, TransactionStatistics = ts })
.ToList();
// send requests
var statistics = new List<RequestStatistics>(inputs.Count);
for (int i = 0; i < inputs.Count; i = i + degreeOfParallelism)
{
var tasks = new List<Task<RequestStatistics>>();
for (int j = i; j < i + degreeOfParallelism; j++)
{
if (inputs.Count <= j) break;
var input = inputs[j];
tasks.Add(InvokePredictorService(input.TransactionInfo, input.TransactionStatistics));
}
Task.WaitAll(tasks.ToArray());
statistics.AddRange(tasks.Select(t => t.Result));
}
// return result
return new RequestsStatistics(statistics);
}
/* other members */
}
Вызов InvokeParallel():
Лучшее время ответа: 421.683 ms
Худшее время: 1355.516 ms
Среднее время: 652.935 ms
Количество успешных запросов: 20061
Количество отказов: 956
Вызов InvokeAsync():
Лучшее время ответа: 478.102 ms
Худшее время: 1344.348 ms
Среднее время: 605.911 ms
Количество успешных запросов: 21017
Количество отказов: 0
Ограничения (потенциальные)
Бутылочным горлышком разрабатываемой системы, на первый взгляд, будет являться Azure ML. Поэтому крайне важно понимать ограничения Azure ML в общем и web-сервисов Azure ML, в частности. Но по данному вопросу очень мало как официальной документации, так и результатов, полученных от community.
Так остается открытым вопрос с throttled policy конечных точек web-сервиса Azure ML: не ясно максимальное значение параллельных запросов web-сервису Azure ML (эмпирически проверена цифра 20 параллельных запросов на одну конечную точку), а также максимальный размер принимаемого сообщения (актуального для пакетного режима работы сервиса).
Менее актуально, но стоит вопрос с максимальным размером входных данных (Criteo Labs разместили датасет на 1 Тб данных), максимальным количеством предикторов и прецедентов, которые можно отдать на вход алгоритму машинного обучения в Azure ML.
Критически важно сократить время ответа веб-сервиса FraudPredictorML, а также время переобучения модели до минимальных значений, но пока нет никаких официальных рекомендаций по тому, как это возможно сделать (и возможно ли вообще).
Рекомендации клиентам
Антифрод-сервис никак не ограничивает клиентов как в предварительной проверке платежей, так и в последующей интерпретации результатов предсказания. Предварительные специфичные для бизнес-процесса проверки, а также окончательное принятие решения о принятии/отклонение платежа – это задачи, которые явно выходят из зоны ответственности антифрод-сервиса.
В независимости о роли клиента – интернет-магазин, платежная система или банк – для клиентов существуют следующие рекомендации:
- выполняйте предварительную проверку платежей, как используя технологии, принятые в отрасли (fingerprint и т.п.), так и использую собственные знания о клиенте (историю заказов и т.п.);
- интерпретируйте результат, применяя следующую практику: вероятность фрода ниже 0,35 – принимать оплату без 3D-Secure, вероятность от 0,35 до 0,85 – принимайте оплату с включенным 3DS, вероятность фрода – более отказывайте;
- выбирайте уровни, предложенные в предыдущем пункте, на основе собственной аналитики и регулярно пересматривайте их (минимизируйте упущенные выгоды и штрафы за фрод).
[+] Рекомендации для комментирующихВ рамках этого цикла статей мы касались проблематики вопроса, юридической и технической стороны проблемы. Это техническая статья, она не преследует собой цели создать бизнес-план, сравнить с решениями конкурентов, вычислить дисконтированную стоимость проекта. Со всеми этими вопросами на РБК – не ко мне, не в это хаб, и, есть подозрение, даже не на этот сайт.
Заключение
В этом цикле, состоящем из 4-ех статей, мы провели эксперимент по проектированию и разработке высокомасштабируемого отказоустойчивого надежного antifraud-сервиса, работающего в near real-time режиме, с открытым для внешних программным клиентов REST/JSON API.
Применение алгоритмов машинного обучения (дерево решений, нейросети) позволили создать аналитическую систему, способную к самообучению как на накопленной истории, так и на новых платежах. Благодаря использованию PaaS-/IaaS-сервисов удалось сократить первоначальные финансовые затраты на инфраструктуру и ПО практически до нуля. Наличие у разработчика компетенций в предметной области, data science, архитектуре распределенных систем помогло драматически снизить количество участников команды разработки.
В результате менее чем за 60 человеко-часов и с минимальными начальными затратами на инфраструктуру (<$150, которые были покрыты из подписки MSDN) удалось создать ядро антифрод-системы.
Получившийся сервис, конечно, требует еще тщательной проверки (и последующего исправления) основных модулей, более тонкой настройки работы классификатора(ов), разработки серии вспомогательных подсистем, интереса и (что тут греха таить) инвестиций. Но и несмотря на указанные выше недоработки, сервис на порядок (и больше) эффективнее аналогичных разработок в отрасли как с точки зрения стоимости разработки, так и с точки зрения стоимости владения.
(c) habra