
Carder
Professional
- Messages
- 2,619
- Reaction score
- 1,883
- Points
- 113

Эта анимация показывает выполнение простой программы на C. К концу статьи вы поймете, как это работает!
Язык программирования C - популярный и широко используемый язык программирования для создания компьютерных программ. Программисты во всем мире принимают C, потому что он дает программисту максимальный контроль и эффективность.
Если вы программист или хотите стать программистом, изучение C дает вам несколько преимуществ:
- Вы сможете читать и писать код для большого количества платформ - все, от микроконтроллеров до самых передовых научных систем, может быть написано на C, а многие современные операционные системы написаны на C.
- Переход к объектно-ориентированному языку C ++ становится намного проще. C ++ является расширением C, и практически невозможно изучить C ++ без предварительного изучения C.
Что такое C?

C - это компьютерный язык программирования. Это означает, что вы можете использовать C для создания списков инструкций, которым должен следовать компьютер. C - один из тысяч языков программирования, используемых в настоящее время. C существует уже несколько десятилетий и завоевал широкое признание, поскольку дает программистам максимальный контроль и эффективность. C - простой язык для изучения. По своему стилю он немного более загадочен, чем у некоторых других языков, но вы довольно быстро выходите за его рамки.
C - это то, что называется компилируемым языком. Это означает, что как только вы напишете свою программу на C, вы должны запустить ее через компилятор C, чтобы превратить вашу программу в исполняемый файлчто компьютер может запускать (выполнять). Программа C - это форма, удобочитаемая человеком, а исполняемый файл, который выходит из компилятора, - это машиночитаемая и исполняемая форма. Это означает, что для написания и запуска программы на C у вас должен быть доступ к компилятору C. Если вы используете машину UNIX (например, если вы пишете сценарии CGI на языке C на компьютере UNIX вашего хоста, или если вы студент, работающий на машине UNIX в лаборатории), компилятор C доступен бесплатно. Он называется «cc» или «gcc» и доступен в командной строке. Если вы студент, то школа, скорее всего, предоставит вам компилятор - узнайте, что школа использует, и узнайте об этом. Если вы работаете дома на компьютере с Windows, вам нужно будет загрузить бесплатный компилятор C или приобрести коммерческий компилятор. Широко используемый коммерческий компилятор - это среда Microsoft Visual C ++ (она компилирует программы как на C, так и на C ++). К сожалению, эта программа стоит несколько сотен долларов. Если у вас нет сотен долларов, которые можно потратить на коммерческий компилятор, вы можете использовать один из бесплатных компиляторов, доступных в Интернете. Видеть http://delorie.com/djgpp/ в качестве отправной точки для поиска.
Мы начнем с очень простой программы на языке C и продолжим работу над ней. Я предполагаю, что вы используете командную строку UNIX и gcc в качестве среды для этих примеров; в противном случае весь код будет работать нормально - вам просто нужно понять и использовать любой доступный компилятор.
Давайте начнем!
Простейшая программа на C
Давайте начнем с простейшей программы на C и будем использовать ее для понимания основ C и процесса компиляции C. Введите следующую программу в стандартный текстовый редактор (vi или emacs в UNIX, Блокнот в Windows или TeachText в Macintosh). Затем сохраните программу в файл с именем samp.c. Если вы оставите .c, вы, вероятно, получите какую-то ошибку при его компиляции, поэтому убедитесь, что вы помните .c. Также убедитесь, что ваш редактор не добавляет автоматически некоторые дополнительные символы (например, .txt) к имени файла. Вот первая программа:
Code:
#include <stdio.h>
int main ()
{
printf ("Это результат моей первой программы! \ n");
return 0;
}Компьютерная программа - ключ к цифровому городу: если вы знаете язык, вы можете заставить компьютер делать практически все, что захотите. Узнайте, как писать компьютерные программы на C.
При выполнении эта программа инструктирует компьютер распечатать строку «Это результат моей первой программы!» - затем программа закрывается. Вы не можете найти ничего проще!
Чтобы скомпилировать этот код, выполните следующие действия:
- На компьютере UNIX введите gcc samp.c -o samp (если gcc не работает, попробуйте cc). Эта строка вызывает компилятор C под названием gcc, просит его скомпилировать samp.c и просит разместить создаваемый исполняемый файл под именем samp. Чтобы запустить программу, введите samp (или на некоторых машинах UNIX ./samp ).
- На машине с DOS или Windows, использующей DJGPP, в командной строке MS-DOS введите gcc samp.c -o samp.exe. Эта строка вызывает компилятор C под названием gcc, просит его скомпилировать samp.c и просит его разместить создаваемый исполняемый файл под именем samp.exe. Чтобы запустить программу, введите samp .
- Если вы работаете с каким-либо другим компилятором или системой разработки, прочтите и следуйте инструкциям для компилятора, который вы используете для компиляции и выполнения программы.
Если вы неправильно наберете программу, она либо не скомпилируется, либо не запустится. Если программа не компилируется или работает некорректно, отредактируйте ее еще раз и посмотрите, где вы ошиблись при вводе текста. Исправьте ошибку и попробуйте еще раз.
Позиция
Когда вы входите в эту программу, поместите #include так, чтобы знак фунта находился в столбце 1 (крайний левый край). В противном случае интервалы и отступы могут быть любыми, как вам нравится. В некоторых системах UNIX вы найдете программу cb, C Beautifier, которая будет форматировать код за вас. Показанные выше интервалы и отступы - хороший пример для подражания.
Простейшая программа на C: что происходит?
Давайте пройдемся по этой программе и начнем видеть, что делают разные строки:- Эта программа на C начинается с #include <stdio.h>. Эта строка включает в вашу программу «стандартную библиотеку ввода-вывода». Стандартная библиотека ввода-вывода позволяет вам читать ввод с клавиатуры (так называемый «стандартный ввод »), записывать вывод на экран (так называемый «стандартный вывод»), обрабатывать текстовые файлы, хранящиеся на диске, и так далее. Это чрезвычайно полезная библиотека. C имеет большое количество стандартных библиотек, таких как stdio, включая библиотеки строк, времени и математики. Библиотека просто пакет кода, который кто - то написал, чтобы сделать вашу жизнь проще (мы обсудим библиотеку немного позже).
- Строка int main () объявляет главную функцию. Каждая программа на C должна иметь где-нибудь в коде функцию с именем main. Вскоре мы узнаем больше о функциях. Во время выполнения выполнение программы начинается с первой строки основной функции.
- В C символы { и } обозначают начало и конец блока кода. В этом случае блок кода, составляющий основную функцию, состоит из двух строк.
- Оператор printf в C позволяет отправлять вывод на стандартный вывод (для нас на экран). Часть в кавычках называется строкой формата и описывает, как данные должны быть отформатированы при печати. Строка формата может содержать строковые литералы, такие как «Это результат моей первой программы!», Символы для возврата каретки (\ n) и операторы в качестве заполнителей для переменных (см. Ниже). Если вы используете UNIX, вы можете набрать man 3 printf, чтобы получить полную документацию по функции printf. В противном случае см. Документацию, прилагаемую к вашему компилятору, для получения подробной информации о функции printf.
- Возврат 0;строка заставляет функцию возвращать код ошибки 0 (нет ошибки) оболочке, которая начала выполнение. Подробнее об этой возможности чуть позже.
Переменные
Как программист, вы часто хотите, чтобы ваша программа «запоминала» значение. Например, если ваша программа запрашивает значение у пользователя или вычисляет значение, вы захотите запомнить его где-нибудь, чтобы использовать его позже. Ваша программа запоминает вещи с помощью переменных. Например:
Code:
int b;
Code:
b = 5;
Code:
printf ("% d", b);В C есть несколько стандартных типов переменных:
- int - целые (целые числа) значения
- float - значения с плавающей запятой
- char - односимвольные значения (например, "m" или "Z")
Printf
Оператор printf позволяет отправлять вывод на стандартный вывод.Для нас стандартным выходом обычно является экран (хотя вы можете перенаправить стандартный выход в текстовый файл или другую команду).Вот еще одна программа, которая поможет вам узнать больше о printf:
Code:
#include <stdio.h>
int main()
{
int a, b, c;
a = 5;
b = 7;
c = a + b;
printf("%d + %d = %d\n", a, b, c);
return 0;
}Введите эту программу в файл и сохранить его как add.c. Скомпилируйте его с помощью строки gcc add.c -o add, а затем запустите, набрав add (или ./add). Вы увидите строку «5 + 7 = 12» в качестве вывода.
Вот объяснение различных строк в этой программе:
- Строка int a, b, c;объявляет три целочисленные переменные с именами a, b и c. Целочисленные переменные содержат целые числа.
- Следующая строка инициализирует переменную с именем a значением 5.
- Следующая строка устанавливает b равным 7.
- Следующая строка добавляет a и b и «присваивает» результат c. Компьютер добавляет значение в a (5) к значению в b (7), чтобы сформировать результат 12, а затем помещает это новое значение (12) в переменную c. Переменной c присваивается значение 12. По этой причине знак = в этой строке называется «оператором присваивания».
- Затем оператор printf выводит строку «5 + 7 = 12». В % D заполнители в PRINTF заявление выступает в качестве заполнителей для значений. Есть три заполнителя% d, а в конце строки printf есть три имени переменных: a, b и c. C сопоставляет первый% d с a и заменяет 5 там. Он сопоставляет второй% d с b и заменяет 7. Он сопоставляет третий% d с c и заменяет 12. Затем он выводит завершенную строку на экран: 5 + 7 = 12. Знаки +, = и интервал являются a часть строки формата и автоматически встраивается между операторами% d, как указано программистом.
Printf: чтение пользовательских значений
Предыдущая программа хороша, но было бы лучше, если бы она считывала значения 5 и 7 от пользователя вместо использования констант. Попробуйте вместо этого эту программу:
Code:
#include <stdio.h>
int main()
{
int a, b, c;
printf("Enter the first value:");
scanf("%d", &a);
printf("Enter the second value:");
scanf("%d", &b);
c = a + b;
printf("%d + %d = %d\n", a, b, c);
return 0;
}Вот как эта программа работает, когда вы ее выполняете:
Внесите изменения, затем скомпилируйте и запустите программу, чтобы убедиться, что она работает. Обратите внимание, что scanf использует тот же тип строки формата, что и printf ( для получения дополнительной информации введите man scanf ). Также обратите внимание на & перед a и b. Это оператор адреса в C: он возвращает адрес переменной (это не будет иметь смысла, пока мы не обсудим указатели). Вы должны использовать оператор & в scanf для любой переменной типа char, int или float, а также для типов структур (к которым мы вскоре вернемся). Если вы опустите оператор &, вы получите сообщение об ошибке при запуске программы. Попробуйте, чтобы увидеть, как выглядит такая ошибка времени выполнения.
Давайте рассмотрим некоторые варианты, чтобы полностью понять printf. Вот простейший оператор printf:
Code:
printf ("Hello");
Code:
printf ("Hello \ n");В следующей строке показано, как вывести значение переменной с помощью printf.
Code:
printf ("% d", b);
Code:
printf("The temperature is ");
printf("%d", b);
printf(" degrees\n");Проще сказать следующее:
Code:
printf("The temperature is %d degrees\n", b)Вы также можете использовать несколько заполнителей% d в одном операторе printf:
Code:
printf ("% d +% d =% d \ n", a, b, c);Вы можете распечатать все обычные типы C с помощью printf, используя разные заполнители:
- int (целочисленные значения) использует % d
- float (значения с плавающей запятой) использует % f
- char (односимвольные значения) использует % c
- character strings (массивы символов, обсуждаемые позже) используют % s
Ошибки C, которых следует избегать:
- Использование неправильного регистра символов - регистр имеет значение в C, поэтому вы не можете вводить Printf или PRINTF. Это должен быть printf.
- Забыть использовать & в scanf
- Слишком много или слишком мало параметров после оператора формата в printf или scanf
- Забыть объявить имя переменной перед ее использованием
Scanf
Функция scanf позволяет вам принимать ввод из стандартного in, которым для нас обычно является клавиатура. Функция scanf может делать много разных вещей, но может быть ненадежной, потому что не очень хорошо обрабатывает человеческие ошибки. Но для простых программ он достаточно хорош и прост в использовании.Самое простое приложение scanf выглядит так:
Code:
scanf ("% d", & b);Функция scanf использует те же заполнители, что и printf:
- int использует % d
- float использует % f
- char использует % c
- character strings (обсуждаемые позже) используют % s
В общем, лучше всего использовать scanf, как показано здесь - для чтения одного значения с клавиатуры. Используйте несколько вызовов scanf для чтения нескольких значений. В любой реальной программе вы будете использовать функции gets или fgets вместо того, чтобы читать текст построчно. Затем вы «проанализируете» строку, чтобы прочитать ее значения. Причина, по которой вы это делаете, заключается в том, чтобы вы могли обнаруживать ошибки во вводе и обрабатывать их по своему усмотрению.
Чтобы полностью понять функции printf и scanf, потребуется немного практики, но после освоения они становятся чрезвычайно полезными.
Попробуйте это:
Измените эту программу так, чтобы она принимала три значения вместо двух и складывала все три вместе:
Code:
#include <stdio.h>
int main ()
{
int a, b, c;
printf ("Введите первое значение:");
scanf ("% d", & a);
printf ("Введите второе значение:");
scanf ("% d", & b);
с = а + Ь;
printf ("% d +% d =% d \ n", a, b, c);
return 0;
}Вы также можете удалить переменную b в первой строке приведенной выше программы и посмотреть, что сделает компилятор, если вы забудете объявить переменную. Удалите точку с запятой и посмотрите, что произойдет. Оставьте одну из скоб. Уберите одну из скобок рядом с основной функцией. Сделайте каждую ошибку отдельно, а затем запустите программу через компилятор, чтобы посмотреть, что произойдет. Моделируя подобные ошибки, вы можете узнать о различных ошибках компилятора, и это упростит поиск ваших опечаток, если вы сделаете их по-настоящему.
Вариации
Попробуйте удалить или добавить случайные символы или слова в одной из предыдущих программ и посмотрите, как компилятор отреагирует на эти ошибки.
Ветвление и зацикливание

В C как операторы if, так и циклы while основаны на идее логических выражений. Вот простая программа на C, демонстрирующая оператор if:
Code:
#include int main () {int b; printf ("Введите значение:"); scanf ("% d", & b); if (b <0) printf ("Значение отрицательное n"); return 0; }Вот немного более сложный пример:
Code:
#include <stdio.h>
int main ()
{
int b;
printf ("Введите значение:");
scanf ("% d", & b);
если (b <0)
printf ("Значение отрицательное \ n");
return 0;
}Вот более сложное логическое выражение:
Code:
if ((x==y) && (j>k))
z=1;
else
q=10;В этом заявлении говорится: «Если значение в переменной x равно значению в переменной y, и если значение в переменной j больше, чем значение в переменной k, то установите для переменной z значение 1, в противном случае установите для переменной q значение 10. " Вы будете использовать подобные операторы if в своих программах на языке C для принятия решений. В общем, большинство решений, которые вы примете, будут простыми, как в первом примере; но иногда все становится сложнее.
Обратите внимание, что C использует == для проверки равенства, в то время как он использует = для присвоения значения переменной. && в C представляет собой логическое И операцию.
Вот все булевы операторы в C:
Code:
равенство ==
меньше чем <
Больше чем>
<= <=
> => =
неравенство! =
и &&
или ||
нет !
Вы обнаружите, что операторы while так же просты в использовании, как операторы if. Например:
в то время как (a <b)
Code:
{
printf ("% d \ n", а);
а = а + 1;
}C также предоставляет структуру do-while:
Code:
#include <stdio.h>
int main ()
{
int a;
printf ("Введите число:");
scanf ("% d", & a);
если)
{
printf ("Значение True \ n");
}
return 0;
}Цикл for в C - это просто сокращенный способ выражения оператора while. Например, предположим, что у вас есть следующий код на C:
Code:
x=1;
while (x<10)
{
blah blah blah
x ++; / * x ++ - это то же самое, что сказать x = x + 1 * /
}Вы можете преобразовать это в цикл for следующим образом:
Code:
for(x=1; x<10; x++)
{
blah blah blah
}Обратите внимание, что цикл while содержит шаг инициализации (x = 1), тестовый шаг (x <10) и шаг приращения (x ++). Цикл for позволяет поместить все три части в одну строку, но в эти три части можно поместить что угодно. Например, предположим, что у вас есть следующий цикл:
Code:
a=1;
b=6;
while (a < b)
{
a++;
printf("%d\n",a);
}Вы также можете поместить это в оператор for:
Code:
for (a = 1, b = 6; a <b; a ++, printf ("% d \ n", a));= vs. == в логических выражениях
Знак == является проблемой в C, потому что время от времени вы можете забыть и ввести просто = в логическом выражении. Это легко сделать, но для компилятора есть очень важное отличие. С будет принимать либо = и == в логическом выражении - поведение программы изменяется заметно между ними, однако.
Булевы выражения оценивают целые числа в C, и целые числа могут использоваться внутри логических выражений. Целочисленное значение 0 в C равно False, а любое другое целочисленное значение - True. В C допустимо следующее:
Если a не 0, выполняется инструкция printf.
В C, как и утверждение, если (а = б) средства, «Присвоить б к, а затем проверить для его логического значения». Итак, если a становится 0, оператор if принимает значение False; в противном случае это правда. Значение изменяется в процессе. Это не предполагаемое поведение, если вы хотели ввести == (хотя эта функция полезна при правильном использовании), поэтому будьте осторожны с использованием = и == .
Цикл: реальный пример
Предположим, вы хотите создать программу, которая печатает таблицу преобразования Фаренгейта в Цельсия. Это легко сделать с помощью цикла for или цикла while:
Code:
#include <stdio.h>
int main()
{
int a;
a = 0;
while (a <= 100)
{
printf("%4d degrees F = %4d degrees C\n",
a, (a - 32) * 5 / 9);
a = a + 10;
}
return 0;
}Если вы запустите эту программу, она создаст таблицу значений, начиная с 0 градусов по Фаренгейту и заканчивая 100 градусами F. Результат будет выглядеть следующим образом:
Code:
0 градусов F = -17 градусов C
10 градусов F = -12 градусов C
20 градусов F = -6 градусов C
30 градусов F = -1 градус C
40 градусов F = 4 градуса C
50 градусов F = 10 градусов C
60 градусов F = 15 градусов C
70 градусов F = 21 градус C
80 градусов F = 26 градусов C
90 градусов F = 32 градуса C
100 градусов F = 37 градусов CЕсли вы хотите, чтобы ваши значения были более точными, вы можете вместо этого использовать значения с плавающей запятой:
Code:
#include <stdio.h>
int main()
{
float a;
a = 0;
while (a <= 100)
{
printf("%6.2f degrees F = %6.2f degrees C\n",
a, (a - 32.0) * 5.0 / 9.0);
a = a + 10;
}
return 0;
}Вы можете видеть, что объявление для a было изменено на float, а символ % f заменяет символ % d в операторе printf. Кроме того, к символу% f применено некоторое форматирование: значение будет напечатано с шестью цифрами перед десятичной точкой и двумя цифрами после десятичной точки.
Теперь предположим, что мы хотели изменить программу, чтобы температура 98,6 была вставлена в таблицу в нужном месте. То есть, мы хотим, чтобы таблица увеличивалась каждые 10 градусов, но мы также хотим, чтобы таблица включала дополнительную строку для 98,6 градусов по Фаренгейту, потому что это нормальная температура тела для человека. Следующая программа достигает цели:
Code:
#include <stdio.h>
int main()
{
float a;
a = 0;
while (a <= 100)
{
if (a > 98.6)
{
printf("%6.2f degrees F = %6.2f degrees C\n",
98.6, (98.6 - 32.0) * 5.0 / 9.0);
}
printf("%6.2f degrees F = %6.2f degrees C\n",
a, (a - 32.0) * 5.0 / 9.0);
a = a + 10;
}
return 0;
}Эта программа работает, если конечное значение равно 100, но если вы измените конечное значение на 200, вы обнаружите, что в программе есть ошибка. Он слишком много раз печатает линию на 98,6 градуса. Мы можем решить эту проблему несколькими способами. Вот один из способов:
Code:
#include <stdio.h>
int main()
{
float a, b;
a = 0;
b = -1;
while (a <= 100)
{
if ((a > 98.6) && (b < 98.6))
{
printf("%6.2f degrees F = %6.2f degrees C\n",
98.6, (98.6 - 32.0) * 5.0 / 9.0);
}
printf("%6.2f degrees F = %6.2f degrees C\n",
a, (a - 32.0) * 5.0 / 9.0);
b = a;
a = a + 10;
}
return 0;
}Ошибки C, которых следует избегать:
- Ввод =, когда вы имеете в виду == в выражении if или while
- Забыть увеличить счетчик внутри цикла while - если вы забудете увеличить счетчик, вы получите бесконечный цикл (цикл никогда не заканчивается).
- Случайно положил; в конце цикла for или оператора if, чтобы оператор не имел эффекта - Например: for (x = 1; x <10; x ++); printf ("% d \ n", х); выводит только одно значение, потому что точка с запятой после оператора for действует как одна строка, которую выполняет цикл for.
Попробуйте это:
- Попробуйте изменить программу преобразования Фаренгейта в Цельсию так, чтобы она использовала scanf для принятия от пользователя начального, конечного и приращения значения таблицы.
- Добавьте строку заголовка к создаваемой таблице.
- Попробуйте найти другое решение ошибки, исправленной в предыдущем примере.
- Создайте таблицу, в которой фунты преобразуются в килограммы или мили в километры.
Массивы
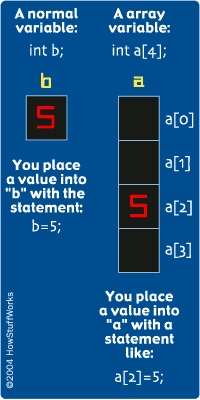
В этом разделе мы создадим небольшую программу на C, которая генерирует 10 случайных чисел и сортирует их. Для этого мы будем использовать новый порядок переменных, называемый массивом .
Массив позволяет объявлять набор значений одного типа и работать с ним. Например, вы можете захотеть создать коллекцию из пяти целых чисел. Один из способов сделать это - напрямую объявить пять целых чисел:
Code:
int a, b, c, d, e;
Code:
int a [5];
Code:
int a [5];
а [0] = 12;
а [1] = 9;
а [2] = 14;
а [3] = 5;
а [4] = 1;Одна из приятных особенностей индексирования массивов заключается в том, что вы можете использовать цикл для управления индексом. Например, следующий код инициализирует все значения в массиве равными 0:
Code:
int a[5];
int i;
for (i=0; i<5; i++)
a[i] = 0;Следующий код последовательно инициализирует значения в массиве и затем распечатывает их:
Code:
#include <stdio.h>
int main()
{
int a[5];
int i;
for (i=0; i<5; i++)
a[i] = i;
for (i=0; i<5; i++)
printf("a[%d] = %d\n", i, a[i]);
}Массивы используются в C. Все время используются массивы. Чтобы понять их общее использование, запустите редактор и введите следующий код:
Code:
#include <stdio.h>
#define MAX 10
int a [MAX];
int rand_seed = 10;
/ * из K&R
- возвращает случайное число от 0 до 32767. * /
int rand()
{
rand_seed = rand_seed * 1103515245 +12345;
return (unsigned int)(rand_seed / 65536) % 32768;
}
int main()
{
int i,t,x,y;
/ * заполняем массив * /
for (i=0; i < MAX; i++)
{
a[i]=rand();
printf("%d\n",a[i]);
}
/ * через минуту сюда будет добавлено больше * /
return 0;
}Этот код содержит несколько новых концепций. В строке #define объявляется константа с именем MAX и устанавливается значение 10. Имена констант традиционно пишутся заглавными буквами, чтобы сделать их очевидными в коде. Строка int a [MAX] ;показывает, как объявить массив целых чисел в C. Обратите внимание, что из-за позиции объявления массива он является глобальным для всей программы.
Строка int rand_seed = 10 также объявляет глобальную переменную, на этот раз с именем rand_seed, которая инициализируется значением 10 при каждом запуске программы. Это значение является начальным значением для следующего кода случайных чисел. В реальном генераторе случайных чисел начальное число должно инициализироваться как случайное значение, такое как системное время. Здесь функция rand будет выдавать одни и те же значения каждый раз, когда вы запускаете программу.
Строка int rand () - это объявление функции. Функция rand не принимает параметров и возвращает целочисленное значение. Мы узнаем больше о функциях позже. Следующие четыре строки реализуют функцию rand. Мы пока их игнорируем.
Основная функция нормальная. Объявлены четыре локальных целых числа, и массив заполняется 10 случайными значениями с помощью цикла for. Обратите внимание, что массив a содержит 10 отдельных целых чисел. Вы указываете на конкретное целое число в массиве, используя квадратные скобки. Таким образом, a [0] относится к первому целому числу в массиве, a [1] относится ко второму и так далее. Строка, начинающаяся с / * и заканчивающаяся * /, называется комментарием. Компилятор полностью игнорирует строку. Вы можете оставлять в комментариях заметки для себя или других программистов.
Теперь добавьте следующий код вместо дополнительных материалов ... комментарий:
Code:
/ * пузырьковая сортировка массива * /
for (x=0; x < MAX-1; x++)
for (y=0; y < MAX-x-1; y++)
if (a[y] > a[y+1])
{
t=a[y];
a[y]=a[y+1];
a[y+1]=t;
}
/ * распечатать отсортированный массив * /
printf ("-------------------- \ n");
для (i = 0; i <MAX; i ++)
printf ("% d \ n", a [i]);Этот код сортирует случайные значения и печатает их в отсортированном порядке. Каждый раз, когда вы запускаете его, вы будете получать одни и те же значения. Если вы хотите изменить сортируемые значения, изменяйте значение rand_seed каждый раз при запуске программы.
Единственный простой способ по-настоящему понять, что делает этот код, - выполнить его «вручную». То есть, предположим, что MAX равно 4, чтобы сделать его немного более управляемым, возьмите лист бумаги и представьте, что вы компьютер. Нарисуйте массив на бумаге и поместите в него четыре случайных несортированных значения. Выполните каждую строку раздела сортировки кода и определите, что именно происходит. Вы обнаружите, что каждый раз при прохождении внутреннего цикла большие значения в массиве смещаются в нижнюю часть массива, а меньшие значения всплывают вверх.
Попробуй это:
- В первом фрагменте кода попробуйте изменить цикл for, который заполняет массив, до одной строки кода. Убедитесь, что результат совпадает с исходным кодом.
- Выньте код пузырьковой сортировки и поместите его в отдельную функцию. Заголовок функции будет пустым, bubble_sort (). Затем переместите переменные, используемые пузырьковой сортировкой, в функцию и сделайте их там локальными. Поскольку массив является глобальным, вам не нужно передавать параметры.
- Инициализируйте начальное число случайных чисел разными значениями.
Ошибки C, которых следует избегать:
- В C нет проверки диапазона, поэтому, если вы индексируете за пределами конца массива, он не скажет вам об этом. В конечном итоге это приведет к сбою или выдаче мусора.
- Вызов функции должен включать (), даже если параметры не переданы. Например, C примет x = rand;, но звонок работать не будет. Вместо этого адрес памяти функции rand будет помещен в x. Вы должны сказать x = rand ();.
Подробнее о массивах
Типы переменныхВ C есть три стандартных типа переменных:
- Целое число: int
- Плавающая точка: float
- Характер: char
Существует ряд производных типов:
- double (8-байтовое значение с плавающей запятой)
- короткий (2-байтовое целое)
- unsigned short или unsigned int (положительные целые числа, без знака)
Операторы и приоритет операторов
Операторы в C аналогичны операторам в большинстве языков:
Code:
+ - сложение
- - вычитание
/ - разделение
* - умножение
% - модпустая функция()
Code:
{
float a;
а = 10/3;
printf ("% f \ n", а);
}Приоритет операторов в C также аналогичен приоритету операторов в большинстве других языков. Сначала происходит деление и умножение, затем сложение и вычитание. Результат вычисления 5 + 3 * 4 равен 17, а не 32, потому что оператор * имеет более высокий приоритет, чем + в C. Вы можете использовать круглые скобки, чтобы изменить нормальный порядок приоритета: (5 + 3) * 4 равно 32. 5 + 3 вычисляется первым, потому что он указан в скобках. Позже мы перейдем к вопросу о приоритетах - это становится несколько сложным в C после введения указателей.
Приведение типов
C позволяет выполнять преобразование типов на лету. Особенно часто это происходит при использовании указателей. Приведение типов также происходит во время операции присваивания для определенных типов. Например, в приведенном выше коде целочисленное значение было автоматически преобразовано в число с плавающей запятой.Вы выполняете приведение типов в C, помещая имя типа в круглые скобки и помещая его перед значением, которое вы хотите изменить. Таким образом, в приведенном выше коде замена строки a = 10/3;с a = (float) 10/3;в результате получается 3,33333, поскольку 10 перед делением преобразуется в значение с плавающей запятой.
Typedef
Вы объявляете именованные, определяемые пользователем типы в C с помощью оператора typedef. В следующем примере показан тип, который часто встречается в коде C:
Code:
#define TRUE 1
#define FALSE 0
typedef int boolean;
void main()
{
boolean b;
b=FALSE;
бла бла бла
}Этот код позволяет вам объявлять логические типы в программах на C.
Если вам не нравится слово «float» для реальных чисел, вы можете сказать:
Code:
typedef float real;
Code:
real r1, r2, r3;Структуры
Структуры в C позволяют группировать переменные в пакет. Вот пример:
Code:
struct rec
{
int a, b, c;
float d, e, f;
};
struct rec r;Как показано здесь, всякий раз, когда вы хотите объявить структуры типа rec, вы должны сказать struct rec. Эту строку очень легко забыть, и вы получите много ошибок компилятора, потому что вы по рассеянности упустите структуру. Вы можете сжать код в форму:
Code:
struct rec
{
int a, b, c;
float d, e, f;
} р;
Code:
typedef struct rec_type;
Code:
rec_type r;Массивы
Вы объявляете массивы, вставляя размер массива после обычного объявления, как показано ниже:
Code:
int a [10]; / * массив целых чисел * /
char s [100]; / * массив символов
(строка C) * /
float f [20]; / * массив реалов * /
struct rec r [50]; / * массив записей * /Приращение
Длинный путь короткий путь
Code:
i = i + 1; i ++;
i = i-1; i--;
i = i + 3; i + = 3;
i= i * j; i * = j;Попробуй это:
- Попробуйте разные фрагменты кода, чтобы проверить приведение типов и приоритет. Попробуйте int, char, float и т.д.
- Создайте массив записей и напишите код для сортировки этого массива по одному целочисленному полю.
Ошибки C, которых следует избегать:
Как описано в статье, использование оператора / с двумя целыми числами часто приводит к неожиданным результатам, поэтому думайте об этом всякий раз, когда будете его использовать.
Функции
Большинство языков позволяют создавать какие-либо функции. Функции позволяют разбивать длинную программу на именованные разделы, чтобы эти разделы можно было повторно использовать в программе. Функции принимают параметры и возвращают результат. Функции C могут принимать неограниченное количество параметров. В общем, C не заботится, в каком порядке вы помещаете свои функции в программу, если имя функции известно компилятору до ее вызова.О функциях мы уже немного поговорили. Функция rand, которую мы видели ранее, настолько проста, насколько это возможно. Он не принимает никаких параметров и возвращает целочисленный результат:
Code:
int rand ()
/ * из K&R
- производит случайное число от 0 до 32767. * /
{
rand_seed = rand_seed * 1103515245 +12345;
return (unsigned int)(rand_seed / 65536) % 32768;
}INT рандов () строка объявляет функцию рэнд к остальной части программы и указывает, что рант не будет принимать никаких параметров и возвращать целочисленный результат. У этой функции нет локальных переменных, но если бы ей потребовались локальные переменные, они бы пошли прямо под открытием { (C позволяет вам объявлять переменные после любого { - они существуют до тех пор, пока программа не достигнет соответствия }, а затем они исчезнут. Локальные переменные функции поэтому переменные исчезают, как только в функции достигается соответствие }. Пока они существуют, локальные переменные находятся в системном стеке.) Обратите внимание, что нет ;после ()в первой строке. Если вы случайно вставите его, вы получите от компилятора огромный каскад бессмысленных сообщений об ошибках. Также обратите внимание, что даже если нет параметров, вы должны использовать (). Они сообщают компилятору, что вы объявляете функцию, а не просто объявляете int.
Оператор return важен для любой функции, возвращающей результат. Он указывает значение, которое функция вернет, и вызывает немедленный выход из функции. Это означает, что вы можете поместить в функцию несколько операторов return, чтобы дать ей несколько точек выхода. Если вы не поместите оператор return в функцию, функция вернется, когда достигнет }, и вернет случайное значение (многие компиляторы предупредят вас, если вы не вернете определенное значение). В C функция может возвращать значения любого типа: int, float, char, struct и т. д.
Есть несколько правильных способов вызвать функцию rand. Например: x = rand ();. Переменной x присваивается значение, возвращаемое rand в этом операторе. Обратите внимание, что вы должны использовать () в вызове функции, даже если параметр не передается. В противном случае x присваивается адрес памяти функции rand, что обычно не соответствует вашим намерениям.
Вы также можете вызвать rand таким образом:
Code:
если (rand ()> 100)
Code:
rand ();Функции могут использовать возвращаемый тип void, если вы не собираетесь ничего возвращать. Например:
Code:
void print_header ()
{
printf ("Номер программы 1 \ n");
printf ("Маршалл Брейн \ n");
printf ("Версия 1.0, от 26.12.91 \ n");
}
Code:
print_header ();Функции C могут принимать параметры любого типа. Например:
Code:
int fact(int i)
{
int j, k;
j = 1;
for (k = 2; k <= i; k ++)
j = j * k;
return j;
}
Code:
int add (int i, int j)
{
return i + j;
}C эволюционировал с годами. Иногда вы можете встретить такие функции, как add, написанные в «старом стиле», как показано ниже:
Code:
int add (i, j)
int i;
int j;
{
return i + j;
}Функции: прототипы функций
Сейчас считается хорошим тоном использовать прототипы функций для всех функций в вашей программе. Прототип объявляет имя функции, ее параметры и тип возвращаемого значения для остальной части программы до фактического объявления функции. Чтобы понять, почему прототипы функций полезны, введите следующий код и запустите его:
Code:
#include <stdio.h>
void main()
{
printf("%d\n",add(3));
}
int add(int i, int j)
{
return i+j;
}Чтобы решить эту проблему, C позволяет размещать прототипы функций в начале (фактически, в любом месте) программы. Если вы это сделаете, C проверяет типы и количество всех списков параметров. Попробуйте скомпилировать следующее:
Code:
#include <stdio.h>
int add (int,int); /* function prototype for add */
void main()
{
printf("%d\n",add(3));
}
int add(int i, int j)
{
return i+j;
}Разместите по одному прототипу для каждой функции в начале своей программы. Они могут сэкономить вам много времени на отладку, а также решают проблему, возникающую при компиляции функций, которые вы используете до их объявления. Например, следующий код не будет компилироваться:
Code:
#include <stdio.h>
void main()
{
printf("%d\n",add(3));
}
float add(int i, int j)
{
return i+j;
}Попробуйте это:
- Вернитесь к примеру пузырьковой сортировки, представленному ранее, и создайте функцию пузырьковой сортировки.
- Вернитесь к более ранним программам и создайте функцию для получения ввода от пользователя, а не для ввода данных в основной функции.
Библиотеки
Библиотеки очень важны в C, потому что язык C поддерживает только самые базовые функции, которые ему нужны. C даже не содержит функций ввода-вывода для чтения с клавиатуры и записи на экран. Все, что выходит за рамки основного языка, должно быть написано программистом. Полученные фрагменты кода часто помещаются в библиотеки, чтобы их можно было легко использовать повторно. Мы уже видели стандартную библиотеку ввода-вывода или stdio: стандартные библиотеки существуют для стандартного ввода-вывода, математических функций, обработки строк, управления временем и т.д. Вы можете использовать библиотеки в своих собственных программах, чтобы разбить свои программы на модули. Это упрощает их понимание, тестирование и отладку, а также позволяет повторно использовать код из других программ, которые вы пишете.Вы можете легко создавать свои собственные библиотеки. В качестве примера мы возьмем код из предыдущей статьи этой серии и сделаем библиотеку из двух его функций. Вот код, с которого мы начнем:
Code:
#include <stdio.h>
#define MAX 10
int a[MAX];
int rand_seed=10;
int rand()
/* from K&R
- produces a random number between 0 and 32767.*/
{
rand_seed = rand_seed * 1103515245 +12345;
return (unsigned int)(rand_seed / 65536) % 32768;
}
void main()
{
int i,t,x,y;
/* fill array */
for (i=0; i < MAX; i++)
{
a[i]=rand();
printf("%d\n",a[i]);
}
/* bubble sort the array */
for (x=0; x < MAX-1; x++)
for (y=0; y < MAX-x-1; y++)
if (a[y] > a[y+1])
{
t=a[y];
a[y]=a[y+1];
a[y+1]=t;
}
/* print sorted array */
printf("--------------------\n");
for (i=0; i < MAX; i++)
printf("%d\n",a[i]);
}Возьмите код пузырьковой сортировки и используйте то, что вы узнали в предыдущей статье, чтобы создать из него функцию. Поскольку и массив a, и константа MAX известны во всем мире, создаваемая функция не требует параметров и не должна возвращать результат. Однако вы должны использовать локальные переменные для x, y и t.
После того, как вы проверили функцию, чтобы убедиться, что она работает, передайте количество элементов в качестве параметра вместо использования MAX:
Code:
#include <stdio.h>
#define MAX 10
int a[MAX];
int rand_seed=10;
/* from K&R
- returns random number between 0 and 32767.*/
int rand()
{
rand_seed = rand_seed * 1103515245 +12345;
return (unsigned int)(rand_seed / 65536) % 32768;
}
void bubble_sort(int m)
{
int x,y,t;
for (x=0; x < m-1; x++)
for (y=0; y < m-x-1; y++)
if (a[y] > a[y+1])
{
t=a[y];
a[y]=a[y+1];
a[y+1]=t;
}
}
void main()
{
int i,t,x,y;
/* fill array */
for (i=0; i < MAX; i++)
{
a[i]=rand();
printf("%d\n",a[i]);
}
bubble_sort(MAX);
/* print sorted array */
printf("--------------------\n");
for (i=0; i < MAX; i++)
printf("%d\n",a[i]);
}Кроме того, можно обобщить bubble_sort функции еще пропускания в в качестве параметра:
Code:
bubble_sort(int m, int a[])
Code:
bubble_sort(MAX, a);Создание библиотеки
Поскольку функции rand и bubble_sort в предыдущей программе полезны, вы, вероятно, захотите повторно использовать их в других программах, которые вы пишете. Вы можете поместить их в служебную библиотеку, чтобы упростить повторное использование.Каждая библиотека состоит из двух частей: файла заголовка и собственно файла кода. Заголовочный файл, обычно обозначаемый суффиксом .h, содержит информацию о библиотеке, которую должны знать программы, использующие его. Как правило, файл заголовка содержит константы и типы, а также прототипы функций, доступных в библиотеке. Введите следующий файл заголовка и сохранить его в файл с именем util.h .
Code:
/* util.h */
extern int rand();
extern void bubble_sort(int, int []);Введите следующий код в файл с именем util.c.
Code:
/* util.c */
#include "util.h"
int rand_seed=10;
/* from K&R
- produces a random number between 0 and 32767.*/
int rand()
{
rand_seed = rand_seed * 1103515245 +12345;
return (unsigned int)(rand_seed / 65536) % 32768;
}
void bubble_sort(int m,int a[])
{
int x,y,t;
for (x=0; x < m-1; x++)
for (y=0; y < m-x-1; y++)
if (a[y] > a[y+1])
{
t=a[y];
a[y]=a[y+1];
a[y+1]=t;
}
}Обратите внимание, что файл включает собственный заголовочный файл (util.h) и использует кавычки вместо символов < and >, которые используются только для системных библиотек. Как видите, это выглядит как обычный код C. Обратите внимание, что переменная rand_seed, поскольку ее нет в файле заголовка, не может быть просмотрена или изменена программой, использующей эту библиотеку. Это называется сокрытием информации. Добавление слова static перед int приводит к полному скрытию.
Введите следующую основную программу в файл с именем main.c.
Code:
#include <stdio.h>
#include "util.h"
#define MAX 10
int a[MAX];
void main()
{
int i,t,x,y;
/* fill array */
for (i=0; i < MAX; i++)
{
a[i]=rand();
printf("%d\n",a[i]);
}
bubble_sort(MAX,a);
/* print sorted array */
printf("--------------------\n");
for (i=0; i < MAX; i++)
printf("%d\n",a[i]);
}Компиляция и запуск с библиотекой
Чтобы скомпилировать библиотеку, введите в командной строке следующее (при условии, что вы используете UNIX) (замените gcc на cc, если ваша система использует cc):
Code:
gcc -c -g util.cЧтобы скомпилировать основную программу, введите следующее:
Code:
gcc -c -g main.c
Code:
gcc -o main main.o util.oMake-файлы немного упрощают работу с библиотеками. Вы узнаете о make-файлах дальше.
Make-файлы
Набирать все строки gcc снова и снова может быть неудобно, особенно если вы вносите много изменений в код и в нем есть несколько библиотек. Средство make решает эту проблему. Вы можете использовать следующий make-файл для замены приведенной выше последовательности компиляции:
Code:
main: main.o util.o
gcc -o main main.o util.o
main.o: main.c util.h
gcc -c -g main.c
util.o: util.c util.h
gcc -c -g util.cЭтот make-файл содержит два типа строк. Линии, расположенные заподлицо слева, являются линиями зависимости. Строки, которым предшествует табуляция, являются исполняемыми строками, которые могут содержать любую допустимую команду UNIX. В строке зависимости говорится, что какой-то файл зависит от другого набора файлов. Например, main.o: main.c util.h говорит, что файл main.o зависит от файлов main.c и util.h. Если какой- либо из этих двух файлов изменений, следующая исполняемая строка (ы) должна быть выполнена, чтобы воссоздают main.o.
Обратите внимание, что последний исполняемый файл, созданный всем make-файлом, является главным в строке 1 make-файла. Окончательный результат Makefile всегда должен идти на линии 1, который в этом Makefile говорит, что файл основной зависит от main.o и util.o. В случае любого из этих изменений выполните строку gcc -o main main.o util.o, чтобы воссоздать main.
Можно поместить несколько строк для выполнения под строкой зависимости - все они должны начинаться с табуляции. Большая программа может иметь несколько библиотек и основную программу. Makefile автоматически перекомпилирует все, что нужно перекомпилировать из-за изменений.
Если вы не работаете на машине UNIX, ваш компилятор почти наверняка имеет функциональность, эквивалентную make-файлам. Прочтите документацию к вашему компилятору, чтобы узнать, как его использовать.
Теперь вы понимаете, почему вы включали stdio.h в предыдущие программы. Это просто стандартная библиотека, которую кто-то давно создал и предоставил другим программистам, чтобы облегчить им жизнь.
Текстовые файлы
Текстовые файлы на C просты и понятны. Все функции и типы текстовых файлов в C взяты из библиотеки stdio .Когда вам нужен текстовый ввод-вывод в программе на C, и вам нужен только один источник для входной информации и один приемник для выходной информации, вы можете положиться на stdin (стандартный вход ) и stdout (стандартный выход). Затем вы можете использовать перенаправление ввода и вывода в командной строке для перемещения различных информационных потоков через программу. В <stdio.h> есть шесть различных команд ввода-вывода, которые можно использовать с stdin и stdout:
- printf - выводит форматированный вывод на стандартный вывод
- scanf - читает форматированный ввод со стандартного ввода
- put - выводит строку в стандартный вывод
- gets - читает строку из стандартного ввода
- putc - выводит символ на стандартный вывод
- getc, getchar - читает символ из стандартного ввода
Преимущество stdin и stdout в том, что они просты в использовании. Точно так же возможность перенаправления ввода-вывода очень мощная. Например, может быть, вы хотите создать программу, которая читает из стандартного ввода и подсчитывает количество символов:
Code:
#include <stdio.h>
#include <string.h>
void main()
{
char s[1000];
int count=0;
while (gets(s))
count += strlen(s);
printf("%d\n",count);
}Введите этот код и запустите его. Он ожидает ввода от стандартного ввода, поэтому введите несколько строк. Когда вы закончите, нажмите CTRL-D, чтобы обозначить конец файла (eof). Функция gets читает строку, пока не обнаружит eof, затем возвращает 0, так что цикл while заканчивается. Когда вы нажимаете CTRL-D, вы видите количество символов в stdout (на экране). (Используйте man gets или документацию вашего компилятора, чтобы узнать больше о функции gets.)
Теперь предположим, что вы хотите подсчитать символы в файле. Если вы скомпилировали программу в исполняемый файл с именем xxx, вы можете ввести следующее:
Code:
xxx <имя файла
Code:
cat <имя файла | ххх
Code:
xxx <имя файла> outИногда вам нужно напрямую использовать текстовый файл. Например, вам может потребоваться открыть определенный файл и прочитать или записать в него. Возможно, вы захотите управлять несколькими потоками ввода или вывода или создать программу, например текстовый редактор, который может сохранять и вызывать данные или файлы конфигурации по команде. В этом случае используйте функции текстового файла в stdio:
- fopen - открывает текстовый файл
- fclose - закрывает текстовый файл
- feof - определяет маркер конца файла в файле
- fprintf - выводит форматированный вывод в файл
- fscanf - читает форматированный ввод из файла
- fputs - выводит строку в файл
- fgets - читает строку из файла
- fputc - печатает символ в файл
- fgetc - читает символ из файла
Текстовые файлы: открытие
Вы используете fopen, чтобы открыть файл. Он открывает файл для указанного режима (три наиболее распространенных: r, w и a для чтения, записи и добавления). Затем он возвращает указатель файла, который вы используете для доступа к файлу. Например, предположим, что вы хотите открыть файл и записать в него числа от 1 до 10. Вы можете использовать следующий код:
Code:
#include <stdio.h>
#define MAX 10
int main()
{
FILE *f;
int x;
f=fopen("out","w");
if (!f)
return 1;
for(x=1; x<=MAX; x++)
fprintf(f,"%d\n",x);
fclose(f);
return 0;
}Оператор fprintf должен выглядеть очень знакомо: он похож на printf, но в качестве первого параметра использует указатель файла. Оператор fclose закрывает файл, когда вы закончите.
Возвращаемые значения основной функции
Эта программа - первая программа в этой серии, которая возвращает значение ошибки из основной программы. Если команда fopen не удалась, f будет содержать значение NULL (ноль). Мы проверяем наличие этой ошибки с помощью оператора if. Оператор if проверяет значение True / False переменной f. Помните, что в C 0 - это ложь, а все остальное - истина. Поэтому, если при открытии файла произошла ошибка, f будет содержать ноль, что соответствует False. !- НЕ оператор. Он инвертирует логическое значение. Итак, оператор if можно было бы написать так:
Это эквивалентно. Однако if (!f) встречается чаще.
Если есть ошибка файла, мы возвращаем 1 из основной функции. В UNIX вы можете проверить это значение в командной строке. Подробнее см. Документацию по оболочке.
Текстовые файлы: чтение
Чтобы прочитать файл, откройте его в режиме r. В общем, использование fscanf для чтения - не лучшая идея : если файл не отформатирован идеально, fscanf не обработает его правильно. Вместо этого используйте fgets, чтобы читать каждую строку, а затем разбирать нужные фрагменты.Следующий код демонстрирует процесс чтения файла и вывода его содержимого на экран:
Code:
#include <stdio.h>
int main()
{
FILE *f;
char s[1000];
f=fopen("infile","r");
if (!f)
return 1;
while (fgets(s,1000,f)!=NULL)
printf("%s",s);
fclose(f);
return 0;
}Оператор fgets возвращает значение NULL в маркере конца файла. Он считывает строку (в данном случае до 1000 символов) и затем выводит ее на стандартный вывод. Обратите внимание, что оператор printf не включает \ n в строку формата, потому что fgets добавляет \ n в конец каждой считываемой строки. Таким образом, вы можете определить, является ли строка незавершенной, если она превышает максимальную длину строки, указанную во втором параметре, до fgets.
Ошибки C, которых следует избегать:
Не набирайте случайно close вместо fclose. Функция закрытия существует, поэтому компилятор принимает ее. Он даже будет работать, если программа откроет или закроет только несколько файлов. Однако, если программа открывает и закрывает файл в цикле, в конечном итоге у нее заканчиваются доступные дескрипторы файлов и / или пространство памяти, и происходит сбой, потому что закрытие не закрывает файлы правильно.
Указатели
Указатели используются в C повсюду, поэтому, если вы хотите полностью использовать язык C, вам необходимо хорошо разбираться в указателях. Они должны быть удобными для вас. Цель этого и следующих нескольких разделов - помочь вам получить полное представление об указателях и о том, как C их использует. Большинству людей требуется немного времени и некоторой практики, чтобы полностью освоить указатели, но как только вы освоите их, вы станете полноценным программистом на C.C использует указатели тремя разными способами:
- C использует указатели для создания динамических структур данных - структур данных, построенных из блоков памяти, выделенных из кучи во время выполнения.
- C использует указатели для обработки переменных параметров, передаваемых функциям.
- Указатели в C предоставляют альтернативный способ доступа к информации, хранящейся в массивах. Указатели особенно ценны при работе со строками. Между массивами и указателями в C. существует тесная связь.
Мы начнем это обсуждение с базового введения в указатели и концепции, связанные с указателями, а затем перейдем к трем методам, описанным выше. Особенно в этой статье вам захочется прочитать дважды. С первого раза вы можете изучить все концепции. Во второй раз вы можете работать над объединением концепций в единое целое в вашем уме. После того, как вы изучите материал во второй раз, это будет иметь большой смысл.
Указатели: Почему?
Представьте, что вы хотите создать текстовый редактор - программу, которая позволяет вам редактировать обычные текстовые файлы ASCII, такие как «vi» в UNIX или «Блокнот» в Windows. Текстовый редактор - довольно обычная вещь для кого-то, потому что, если подумать, текстовый редактор, вероятно, является наиболее часто используемым программным обеспечением программиста. Текстовый редактор - это интимная связь программиста с компьютером: здесь вы вводите все свои мысли, а затем манипулируете ими. Очевидно, что со всем, что вы часто используете и с чем тесно работаете, вы хотите, чтобы все было правильно. Поэтому многие программисты создают свои собственные редакторы и настраивают их в соответствии со своим индивидуальным стилем работы и предпочтениями.Итак, однажды вы садитесь за работу над своим редактором. Подумав о желаемых функциях, вы начинаете думать о «структуре данных» для вашего редактора. То есть вы начинаете думать о том, как сохранить редактируемый документ в памяти, чтобы вы могли управлять им в своей программе. Что вам нужно, так это способ сохранить вводимую вами информацию в форме, которой можно будет быстро и легко управлять. Вы считаете, что один из способов сделать это - организовать данные на основе строк символов. Учитывая то, что мы обсуждали до сих пор, единственное, что у вас есть на данный момент, - это массив. Вы думаете: «Типичная строка составляет 80 символов, а типичный файл - не более 1000 строк». Поэтому вы объявляете двумерный массив, например:
Code:
char doc [1000] [80];Однако, подумав о своем редакторе и его структуре данных, вы можете понять три вещи:
- Некоторые документы представляют собой длинные списки. Каждая строка короткая, но строк тысячи.
- Некоторые текстовые файлы специального назначения содержат очень длинные строки. Например, в определенном файле данных могут быть строки, содержащие 542 символа, каждый из которых представляет пары аминокислот в сегментах ДНК.
- В большинстве современных редакторов можно одновременно открывать несколько файлов.
Code:
char doc [50000] [1000] [10];Даже если компьютер примет запрос на такой большой массив, вы увидите, что это непомерная трата места. Кажется странным объявлять массив из 500 миллионов символов, когда в подавляющем большинстве случаев вы запускаете этот редактор для просмотра 100 строчных файлов, которые занимают не более 4000 или 5000 байтов. Проблема с массивом заключается в том, что вам нужно с самого начала объявить его максимальный размер в каждом измерении.Эти максимальные размеры часто перемножаются и образуют очень большие числа. Кроме того, если вам нужно иметь возможность редактировать нечетный файл со строкой в 2000 символов, вам не повезло. На самом деле у вас нет способа предсказать и обработать максимальную длину строки текстового файла, потому что технически это число бесконечно.
Указатели предназначены для решения этой проблемы. С помощью указателей вы можете создавать динамические структуры данных. Вместо того, чтобы заранее объявлять в массиве о потреблении памяти в наихудшем случае, вы выделяете память из кучиво время работы программы. Таким образом, вы можете без потерь использовать тот объем памяти, который требуется документу. Кроме того, когда вы закрываете документ, вы можете вернуть память в кучу, чтобы другие части программы могли ее использовать. С помощью указателей память можно повторно использовать во время работы программы.
Кстати, если вы прочитали предыдущее обсуждение и у вас возник один из главных вопросов: «Что такое байт на самом деле?», То статья «Как работают биты и байты» поможет вам понять концепции, а также такие вещи, как «мега», «гига» и «тера». Пойдите, посмотрите, а затем вернитесь.
Основы указателя

На этом чертеже были объявлены три переменные i, j и p, но ни одна из трех не была инициализирована.
Чтобы понять указатели, полезно сравнить их с обычными переменными.
«Обычная переменная» - это место в памяти, которое может содержать значение. Например, когда вы объявляете переменную i как целое число, для нее выделяются четыре байта памяти. В вашей программе вы обращаетесь к этому месту в памяти по имени i. На уровне машины это место имеет адрес памяти. Четыре байта по этому адресу известны вам, программисту, как i, а четыре байта могут содержать одно целое значение.
Указатель другой. Указатель - это переменная, которая указывает на другую переменную. Это означает, что указатель содержит адрес в памяти другой переменной. Другими словами, указатель не содержит значения в традиционном смысле; вместо этого он содержит адрес другой переменной. Указатель «указывает на» эту другую переменную, удерживая копию ее адреса.
Поскольку указатель содержит адрес, а не значение, он состоит из двух частей. Сам указатель содержит адрес. Этот адрес указывает на значение. Есть указатель и указанное значение. Этот факт может немного сбивать с толку, пока вы не освоитесь с ним, но как только вы освоитесь, он станет чрезвычайно мощным.
В следующем примере кода показан типичный указатель:
Code:
#include <stdio.h>
int main()
{
int i,j;
int *p; / * указатель на целое число * /
p = &i;
*p=5;
j=i;
printf("%d %d %d\n", i, j, *p);
return 0;
}Первое объявление в этой программе объявляет две обычные целочисленные переменные с именами i и j. Строка int * p объявляет указатель с именем p. Эта строка просит компилятор объявить переменную p, которая является указателем на целое число. * Указывает на то, что указатель был объявлен вместо обычной переменной. Вы можете создать указатель на что угодно: на объект с плавающей запятой, структуру, символ и т. Д. Просто используйте *, чтобы указать, что вам нужен указатель, а не обычная переменная.
Строка p = & i;определенно будет для вас новым. В языке C & называется адресным оператором. Выражение & i означает «адрес памяти переменной i». Таким образом, выражение p = & i;означает: «Назначить p адрес i ». После выполнения этого оператора p "указывает на" i. Прежде чем вы это сделаете, p содержит случайный неизвестный адрес, и его использование, вероятно, вызовет ошибку сегментации или аналогичный сбой программы.
Один из хороших способов визуализировать происходящее - нарисовать картинку. После объявления i, j и p мир будет выглядеть как на изображении выше.
На этом чертеже были объявлены три переменные i, j и p, но ни одна из трех не была инициализирована. Таким образом, две целочисленные переменные изображены в виде прямоугольников с вопросительными знаками - они могут содержать любое значение на данном этапе выполнения программы. Указатель нарисован в виде круга, чтобы отличить его от обычной переменной, содержащей значение, а случайные стрелки указывают, что в данный момент он может указывать куда угодно.
После строки p = & I;, p инициализируется и указывает на i, например:

Как только p указывает на i, у ячейки памяти i есть два имени. Он по-прежнему известен как i, но теперь он также известен как * p. Вот как C говорит о двух частях переменной-указателя: p - это местоположение, содержащее адрес, а * p - это местоположение, на которое указывает этот адрес. Следовательно, * p = 5 означает, что местоположение, на которое указывает p, должно быть установлено на 5, например:

Поскольку местоположение * p также является i, i также принимает значение 5. Следовательно, j = i;устанавливает j в 5, а оператор printf возвращает 5 5 5.
Главная особенность указателя - его двухчастный характер. Сам указатель содержит адрес. Указатель также указывает на значение определенного типа - значение по адресу, который содержит точка. Сам указатель в данном случае - p. Указанное значение - * p.
Указатели: общие сведения об адресах памяти

Переменная f занимает четыре байта ОЗУ в памяти. У этого места есть конкретный адрес, в данном случае 248 440.
Предыдущее обсуждение станет немного яснее, если вы поймете, как адреса памяти работают в аппаратном обеспечении компьютера. Если вы еще не читали его, сейчас самое время прочитать, как работают биты и байты, чтобы полностью понять биты, байты и слова.
Все компьютеры имеют память, также известную как RAM (оперативная память). Например, на вашем компьютере прямо сейчас может быть установлено 16, 32 или 64 мегабайта оперативной памяти. ОЗУ содержит программы, которые в настоящее время выполняет ваш компьютер, а также данные, которыми они в данный момент управляют (их переменные и структуры данных). Память можно рассматривать просто как массив байтов. В этом массиве каждая ячейка памяти имеет свой собственный адрес - адрес первого байта равен 0, за ним идут 1, 2, 3 и так далее. Адреса памяти действуют так же, как индексы обычного массива. Компьютер может получить доступ к любому адресу в памяти в любое время (отсюда и название «оперативная память»). Он также может группировать байты вместе, если это необходимо для формирования более крупных переменных, массивов и структур. Например, переменная с плавающей запятой занимает в памяти 4 непрерывных байта. Вы можете сделать в программе следующее глобальное объявление:
float f;
Этот оператор говорит: «Объявите место с именем f, которое может содержать одно значение с плавающей запятой». Когда программа запускается, компьютер резервирует место для переменной f где-нибудь в памяти. Это место имеет фиксированный адрес в памяти, например:
Когда вы думаете о переменной f, компьютер думает о конкретном адресе в памяти (например, 248 440). Поэтому, когда вы создаете такой оператор:
Code:
f = 3,14;Между прочим, существует несколько интересных побочных эффектов того, как ваш компьютер обрабатывает память. Например, предположим, что вы включаете следующий код в одну из своих программ:
Code:
int i, s[4], t[4], u=0;
for (i=0; i<=4; i++)
{
s[i] = i;
t[i] =i;
}
printf("s:t\n");
for (i=0; i<=4; i++)
printf("%d:%d\n", s[i], t[i]);
printf("u = %d\n", u);Результат, который вы увидите в программе, вероятно, будет выглядеть так:
Code:
s: t
1: 5
2: 2
3: 3
4: 4
5: 5
u = 5
Массивы, расположенные рядом друг с другом.
Поэтому, когда вы пытаетесь записать в s [4], которого не существует, система вместо этого записывает в t [0], потому что t [0] - это то место, где должно быть s [4]. Когда вы пишете в t [4], вы действительно пишете в u. Что касается компьютера, s [4] - это просто адрес, и он может писать в него. Однако, как вы можете видеть, даже если компьютер выполняет программу, она неверна или неверна. Программа портит массив t в процессе работы. Если вы выполните следующую инструкцию, это приведет к более серьезным последствиям:
Code:
s [1000000] = 5;Поскольку C и C ++ не выполняют никакой проверки диапазона при доступе к элементу массива, важно, чтобы вы, как программист, сами уделяли особое внимание диапазонам массивов и не выходили за соответствующие границы массива. Непреднамеренное чтение или запись за пределами массива всегда приводит к неправильному поведению программы.
В качестве другого примера попробуйте следующее:
Code:
#include <stdio.h>
int main ()
{
int i, j;
int * p; / * указатель на целое число * /
printf ("% d% d \ n", p, & i);
р = & i;
printf ("% d% d \ n", p, & i);
return 0;
}Этот код сообщает компилятор, чтобы распечатать адреса провели в р, вместе с адресом в I.Переменная p начинается с какого-то сумасшедшего значения или с 0. Адрес i обычно имеет большое значение. Например, когда я запустил этот код, я получил следующий результат:
Code:
0 2147478276
2147478276 2147478276
Code:
#include <stdio.h>
void main()
{
int * p; / * указатель на целое число * /
printf ("% d \ n", * p);
}Сказав все это, теперь мы можем взглянуть на указатели в совершенно новом свете. Возьмем, к примеру, эту программу:
Code:
#include <stdio.h>
int main ()
{
int i;
int * p; / * указатель на целое число * /
р = & i;
* р = 5;
printf ("% d% d \ n", i, * p);
return 0;
}Вот что происходит:

Переменная i занимает 4 байта памяти. Указатель p также занимает 4 байта (на большинстве машин, используемых сегодня, указатель потребляет 4 байта памяти. На большинстве процессоров сегодня адреса памяти имеют длину 32 бита, хотя наблюдается возрастающая тенденция к 64-битной адресации). Местоположение i имеет конкретный адрес, в данном случае 248 440. Указатель p содержит этот адрес, когда вы говорите p = & i;. Следовательно, переменные * p и i эквивалентны.
Указатель p буквально содержит адрес i. Когда вы говорите что-то подобное в программе:
printf ("% d", p);
в результате получается фактический адрес переменной i.
Указатели: указание на один и тот же адрес

Вот отличный аспект C: любое количество указателей может указывать на один и тот же адрес. Например, вы можете объявить p, q и r как целочисленные указатели и установить их все так, чтобы они указывали на i, как показано здесь:
Code:
int i;
int *p, *q, *r;
p = &i;
q = &i;
r = p;Переменная i теперь имеет четыре имени: i, * p, * q и * r. Не существует ограничений на количество указателей, которые могут содержать (и, следовательно, указывать) один и тот же адрес.
Указатели: распространенные ошибки
Ошибка №1 - неинициализированные указателиОдин из самых простых способов создать ошибку указателя - попытаться ссылаться на значение указателя, даже если указатель не инициализирован и еще не указывает на действительный адрес. Например:
Code:
int * p;
* р = 12;Указатель p не инициализирован и указывает на случайное место в памяти, когда вы его объявляете. Это может быть указание на системный стек или глобальные переменные, или на пространство кода программы, или на операционную систему. Когда вы говорите * p = 12;, программа просто попытается записать 12 в любое случайное место, на которое указывает p. Программа может взорваться немедленно, или может подождать полчаса, а затем взорваться, или она может незаметно повредить данные в другой части вашей программы, и вы, возможно, никогда этого не осознаете. Это может затруднить отслеживание этой ошибки. Убедитесь, что вы инициализировали все указатели на действительный адрес, прежде чем разыменовать их.
Ошибка № 2 - Недействительные ссылки на указатели
Недопустимая ссылка указателя возникает, когда указывается значение указателя, даже если указатель не указывает на действительный блок.
Один из способов создать эту ошибку - сказать p = q;, когда q неинициализировано. Указатель p также станет неинициализированным, и любая ссылка на * p будет недействительной ссылкой на указатель.
Единственный способ избежать этой ошибки - нарисовать изображения каждого шага программы и убедиться, что все указатели куда-то указывают. Недопустимые ссылки на указатели вызывают необъяснимый сбой программы по тем же причинам, что и в Ошибке №1.
Ошибка № 3 - Ссылка на нулевой указатель
Ссылка на нулевой указатель возникает всякий раз, когда указатель, указывающий на ноль, используется в инструкции, которая пытается ссылаться на блок. Например, если p - указатель на целое число, следующий код недействителен:
Code:
р = 0;
* р = 12;Все эти ошибки фатальны для программы, которая их содержит. Вы должны следить за своим кодом, чтобы этих ошибок не произошло. Лучший способ сделать это - поэтапно рисовать картинки выполнения кода.
Использование указателей для параметров функций

Большинство программистов на C сначала используют указатели для реализации в функциях того, что называется параметрами переменных. Фактически вы использовали параметры переменных в функции scanf - вот почему вам пришлось использовать & (оператор адреса) для переменных, используемых в функции scanf. Теперь, когда вы разбираетесь в указателях, вы можете видеть, что на самом деле происходит.
Чтобы понять, как работают переменные параметры, давайте посмотрим, как мы могли бы реализовать функцию подкачки в C. Чтобы реализовать функцию подкачки, вам нужно передать две переменные, а функция поменять местами их значения. Вот одна попытка реализации - введите и выполните следующий код и посмотрите, что произойдет:
Code:
#include <stdio.h>
void swap(int i, int j)
{
int t;
t=i;
i=j;
j=t;
}
void main()
{
int a,b;
a=5;
b=10;
printf("%d %d\n", a, b);
swap(a,b);
printf("%d %d\n", a, b);
}Чтобы эта функция работала правильно, вы можете использовать указатели, как показано ниже:
Code:
#include <stdio.h>
void swap(int *i, int *j)
{
int t;
t = *i;
*i = *j;
*j = t;
}
void main()
{
int a,b;
a=5;
b=10;
printf("%d %d\n",a,b);
swap(&a,&b);
printf("%d %d\n",a,b);
}Предположим, вы случайно забыли & при вызове функции подкачки, и что строка подкачки случайно выглядит так: swap (a, b);. Это вызывает ошибку сегментации. Когда вы выходите из &, то значение из передаются вместо его адреса. Следовательно, i указывает на недопустимое место в памяти, и при использовании * i происходит сбой системы.
По этой же причине происходит сбой scanf, если вы забыли переданные ему переменные & on. Функция scanf использует указатели, чтобы поместить считываемое значение обратно в переданную вами переменную. Без &, scanf передается неверный адрес и вылетает.
Переменные параметры - одно из наиболее распространенных применений указателей в C. Теперь вы понимаете, что происходит!
Динамические структуры данных
Динамические структуры данных - это структуры данных, которые увеличиваются и уменьшаются по мере необходимости за счет выделения и освобождения памяти из места, называемого кучей. Они чрезвычайно важны в C, потому что позволяют программисту точно контролировать потребление памяти.Динамические структуры данных выделяют блоки памяти из кучи по мере необходимости и связывают эти блоки вместе в некую структуру данных с помощью указателей. Когда структуре данных больше не нужен блок памяти, она вернет блок в кучу для повторного использования. Эта переработка позволяет очень эффективно использовать память.
Чтобы полностью понять динамические структуры данных, нам нужно начать с кучи.
Динамические структуры данных: куча

Операционная система и несколько приложений, а также их глобальные переменные и пространства стека потребляют часть памяти. Когда программа завершает выполнение, она освобождает свою память для повторного использования другими программами. Обратите внимание, что часть пространства памяти остается неиспользованной в любой момент времени.
На типичном персональном компьютере или рабочей станции сегодня установлено от 16 до 64 мегабайт оперативной памяти. Использование техники, называемой виртуальной памятью, система может менять местами память на жестком диске машины и за ее пределами, чтобы создать для ЦП иллюзию, что у него гораздо больше памяти, например от 200 до 500 мегабайт. Хотя эта иллюзия полна в том, что касается ЦП, иногда с точки зрения пользователя она может сильно замедлить работу. Несмотря на этот недостаток, виртуальная память - чрезвычайно полезный метод недорогого «увеличения» объема ОЗУ в машине. Давайте предположим для этого обсуждения, что типичный компьютер имеет общий объем памяти, например, 50 мегабайт (независимо от того, реализована ли эта память в реальной или виртуальной памяти).
Операционная система на машине отвечает за пространство памяти 50 мегабайта. Операционная система использует пространство несколькими способами, как показано здесь.
Это, конечно, идеализация, но основные принципы верны. Как видите, в памяти хранится исполняемый код для различных приложений, запущенных в данный момент на машине, а также исполняемый код самой операционной системы. С каждым приложением связаны определенные глобальные переменные. Эти переменные также потребляют память. Наконец, каждое приложение использует область памяти, называемую стеком., который содержит все локальные переменные и параметры, используемые любой функцией. Стек также запоминает порядок, в котором вызываются функции, чтобы возврат функций происходил правильно. Каждый раз при вызове функции ее локальные переменные и параметры «помещаются» в стек. Когда функция возвращается, эти локальные переменные и параметры «выталкиваются». Из-за этого размер стека программы постоянно колеблется во время выполнения программы, но имеет некоторый максимальный размер.
Когда программа завершает выполнение, операционная система выгружает ее, свои глобальные переменные и пространство стека из памяти. Новая программа может использовать это пространство позже. Таким образом, память компьютерной системы постоянно «перерабатывается» и повторно используется программами по мере их выполнения и завершения.
В общем, возможно, 50 процентов общего объема памяти компьютера могут быть неиспользованными в любой момент. Операционная система владеет неиспользуемой памятью и управляет ею, и все вместе это называется кучей. Куча чрезвычайно важна, потому что она доступна для использования приложениями во время выполнения с использованием функций C malloc (выделение памяти) и free. Куча позволяет программам выделять память именно тогда, когда она им нужна во время выполнения программы, а не предварительно выделять ее с помощью объявления массива определенного размера.
Динамические структуры данных: Malloc и Free

Блок справа - это блок памяти, выделенный malloc.
Допустим, вы хотите выделить определенный объем памяти во время выполнения вашего приложения. Вы можете вызвать функцию malloc в любое время, и она запросит блок памяти из кучи. Операционная система зарезервирует блок памяти для вашей программы, и вы можете использовать его как угодно. Когда вы закончите с блоком, вы возвращаете его в операционную систему для повторного использования, вызывая функцию free. Затем другие приложения могут зарезервировать его позже для собственного использования.
Например, следующий код демонстрирует простейшее возможное использование кучи:
Code:
int main()
{
int *p;
p = (int *)malloc(sizeof(int));
if (p == 0)
{
printf("ERROR: Out of memory\n");
return 1;
}
*p = 5;
printf("%d\n", *p);
free(p);
return 0;
}Первая строка в этой программе вызывает функцию malloc. Эта функция выполняет три функции:
- Оператор malloc сначала проверяет объем доступной памяти в куче и спрашивает: «Достаточно ли памяти для выделения блока памяти запрошенного размера?» Объем памяти, необходимый для блока, известен из параметра, переданного в malloc - в этом случае sizeof (int) составляет 4 байта. Если доступной памяти недостаточно, функция malloc возвращает нулевой адрес, чтобы указать на ошибку (другое имя для нуля - NULL, и вы увидите, что оно используется во всем коде C). В противном случае malloc продолжается.
- Если память доступна в куче, система «выделяет» или «резервирует» блок из кучи указанного размера. Система резервирует блок памяти, чтобы он случайно не использовался более чем одним оператором malloc.
- Затем система помещает в указательную переменную (в данном случае p) адрес зарезервированного блока. Сама указательная переменная содержит адрес. Выделенный блок может содержать значение указанного типа, и указатель указывает на него.
На самом деле нет никакой разницы между этим кодом и предыдущим кодом, который устанавливает p равным адресу существующего целого числа i. Единственное отличие состоит в том, что в случае переменной i память существовала как часть предварительно выделенного пространства памяти программы и имела два имени: i и * p. В случае выделения памяти из кучи, блок имеет единственное имя * p и выделяется во время выполнения программы. Два общих вопроса:
- Действительно ли важно проверять, что указатель равен нулю после каждого выделения?Да. Поскольку размер кучи постоянно меняется в зависимости от того, какие программы работают, сколько памяти они выделили и т. Д., Нет никакой гарантии, что вызов malloc будет успешным. Вы должны проверять указатель после любого вызова malloc, чтобы убедиться, что указатель действителен.
- Что произойдет, если я забуду удалить блок памяти до завершения программы?Когда программа завершается, операционная система «очищается после нее», освобождая пространство исполняемого кода, стек, пространство глобальной памяти и все выделения кучи для повторного использования. Таким образом, оставление отложенных распределений при завершении программы не имеет долгосрочных последствий. Однако это считается дурным тоном, и «утечки памяти» во время выполнения программы вредны, как обсуждается ниже.
Code:
пустая функция()
{
int * p, * q;
p = (int *) malloc (sizeof (int));
q = p;
* р = 10;
printf ("% d \ n", * q);
* q = 20;
printf ("% d \ n", * q);
}Следующий код немного отличается:
Code:
пустая функция()
{
int * p, * q;
p = (int *) malloc (sizeof (int));
q = (int *) malloc (sizeof (int));
* р = 10;
* q = 20;
* p = * q;
printf ("% d \ n", * p);
}[IMG"]https://cdn.hswstatic.com/gif/c-heap2.gif[/IMG]
Окончательный вывод этого кода будет 10 из строки 4 и 20 из строки 6.

Окончательный вывод этого кода будет 20 из строки 6.
Обратите внимание, что компилятор разрешит * p = * q, потому что * p и * q являются целыми числами. Этот оператор говорит: «Переместите целое значение, на которое указывает q, в целое значение, на которое указывает p». Заявление перемещает значения. Компилятор также разрешит p = q, потому что p и q являются указателями, и оба указывают на один и тот же тип (если s - указатель на символ, p = s не допускается, потому что они указывают на разные типы). Утверждение p = q говорит: «Укажите p на тот же блок, на который указывает q». Другими словами, адрес, на который указывает q, перемещается в p, поэтому они оба указывают на один и тот же блок. Этот оператор перемещает адреса.
Из всех этих примеров вы можете видеть, что существует четыре различных способа инициализировать указатель. Когда указатель объявлен, как в int * p, он запускается в программе в неинициализированном состоянии. Он может указывать куда угодно, и поэтому разыменование является ошибкой. Инициализация переменной-указателя включает указание на известное место в памяти.
- Один из способов, как уже было показано, - использовать оператор malloc. Этот оператор выделяет блок памяти из кучи, а затем указывает указатель на блок. Это инициализирует указатель, потому что теперь он указывает на известное местоположение. Указатель инициализируется, потому что он был заполнен действительным адресом - адресом нового блока.
- Второй способ, который мы видели только что, - использовать такой оператор, как p = q, чтобы p указывал на то же место, что и q. Если q указывает на допустимый блок, то инициализируется p. В указатель p загружается действительный адрес, который содержит q. Однако, если q неинициализирован или недействителен, p получит тот же бесполезный адрес.
- Третий способ - указать указатель на известный адрес, например, на адрес глобальной переменной. Например, если i - целое число, а p - указатель на целое число, то оператор p = & i инициализирует p, указывая его на i.
- Четвертый способ инициализировать указатель - использовать нулевое значение. Ноль - это специальные значения, используемые с указателями, как показано здесь: p = 0; или: p = NULL; Это физически помещает ноль в p. Адрес указателя p равен нулю. Обычно это изображается как:
Любой указатель может быть установлен на ноль. Однако, когда p указывает на ноль, это не указывает на блок. Указатель просто содержит нулевой адрес, и это значение полезно как тег. Вы можете использовать его в таких заявлениях, как:
Code:
if (p == 0){...}
Code:
while (p! = 0) {...}Система также распознает нулевое значение и будет генерировать сообщения об ошибках, если вы случайно разыменовываете нулевой указатель. Например, в следующем коде:
Code:
р = 0; * р = 5;Команда malloc используется для выделения блока памяти. Также возможно освободить блок памяти, когда он больше не нужен. Когда блок освобождается, его можно повторно использовать с помощью следующей команды malloc, которая позволяет системе повторно использовать память. Команда, используемая для освобождения памяти, называется свободной и принимает в качестве параметра указатель. Бесплатная команда делает две вещи:
- Блок памяти, на который указывает указатель, не зарезервирован и возвращается в свободную память в куче. Затем его можно будет повторно использовать в более поздних новых операторах.
- Указатель остается в неинициализированном состоянии, и его необходимо повторно инициализировать, прежде чем его можно будет использовать снова.
В следующем примере показано, как использовать кучу. Он выделяет целочисленный блок, заполняет его, записывает и удаляет:
Code:
#include <stdio.h>
int main()
{
int *p;
p = (int *)malloc (sizeof(int));
*p=10;
printf("%d\n",*p);
free(p);
return 0;
}Функция malloc возвращает указатель на выделенный блок. Этот указатель является универсальным. Использование указателя без преобразования типов обычно вызывает предупреждение о типе от компилятора. Приведение типа (int *) преобразует универсальный указатель, возвращаемый malloc, в «указатель на целое число», чего и ожидает p. Оператор free в C возвращает блок в кучу для повторного использования.
Второй пример иллюстрирует те же функции, что и предыдущий, но использует структуру вместо целого числа. В C код выглядит так:
Code:
#include <stdio.h>
struct rec
{
int i;
float f;
char c;
};
int main()
{
struct rec *p;
p=(struct rec *) malloc (sizeof(struct rec));
(*p).i=10;
(*p).f=3.14;
(*p).c='a';
printf("%d %f %c\n",(*p).i,(*p).f,(*p).c);
free(p);
return 0;
}Обратите внимание на следующую строку:
Code:
(* p) .i = 10;
Code:
*p.i=10;Большинство людей устают постоянно набирать (* p) .i, поэтому C предоставляет сокращенную запись. Следующие два оператора полностью эквивалентны, но второй легче набрать:
Code:
(* p) .i = 10;
p-> i = 10;Расширенные указатели
Обычно вы будете использовать указатели несколько более сложными способами, чем те, которые показаны в некоторых из предыдущих примеров. Например, гораздо проще создать обычное целое число и работать с ним, чем создать и использовать указатель на целое число. В этом разделе будут рассмотрены некоторые из наиболее распространенных и продвинутых способов работы с указателями.
Типы указателей
Возможно, законно и полезно создавать типы указателей в C, как показано ниже:
Code:
typedef int * IntPointer;
...
IntPointer p;Это то же самое, что сказать:
Code:
int * p;Указатели на структуры
В C можно создать указатель практически на любой тип, включая типы, определяемые пользователем. Чрезвычайно распространено создание указателей на структуры. Пример показан ниже:
Code:
typedef struct
{
char name[21];
char city[21];
char state[3];
} Rec;
typedef Rec *RecPointer;
RecPointer r;
r = (RecPointer)malloc(sizeof(Rec));Указатель r - это указатель на структуру. Обратите внимание на тот факт, что r является указателем и, следовательно, занимает четыре байта памяти, как и любой другой указатель. Однако оператор malloc выделяет 45 байт памяти из кучи. * r - это такая же структура, как и любая другая структура типа Rec. В следующем коде показано типичное использование переменной-указателя:
Code:
strcpy((*r).name, "Leigh");
strcpy((*r).city, "Raleigh");
strcpy((*r).state, "NC");
printf("%s\n", (*r).city);
free(r);
Code:
strcpy(r->name, "Leigh");
Указатели на массивы
Также возможно создавать указатели на массивы, как показано ниже:
Code:
int *p;
int i;
p = (int *)malloc(sizeof(int[10]));
for (i=0; i<10; i++)
p[i] = 0;
free(p);
or:
int *p;
int i;
p = (int *)malloc(sizeof(int[10]));
for (i=0; i<10; i++)
*(p+i) = 0;
free(p);
Обратите внимание, что когда вы создаете указатель на массив целых чисел, вы просто создаете обычный указатель на int. Вызов malloc выделяет массив любого желаемого размера, а указатель указывает на первый элемент этого массива. Вы можете либо проиндексировать массив, на который указывает p, используя обычную индексацию массива, либо вы можете сделать это, используя арифметику указателей. C рассматривает обе формы как эквивалентные.
Этот конкретный метод чрезвычайно полезен при работе со строками. Он позволяет выделить достаточно памяти, чтобы точно хранить строку определенного размера.
Массивы указателей
Иногда можно сэкономить много места или решить определенные проблемы с интенсивным использованием памяти, объявив массив указателей. В приведенном ниже примере кода объявляется массив из 10 указателей на структуры вместо объявления массива структур. Если бы вместо этого был создан массив структур, для этого массива потребовалось бы 243 * 10 = 2430 байт. Использование массива указателей позволяет массиву занимать минимальное пространство до тех пор, пока фактические записи не будут выделены операторами malloc. Приведенный ниже код просто выделяет одну запись, помещает в нее значение и удаляет запись, чтобы продемонстрировать процесс:
Code:
typedef struct
{
char s1[81];
char s2[81];
char s3[81];
} Rec;
Rec *a[10];
a[0] = (Rec *)malloc(sizeof(Rec));
strcpy(a[0]->s1, "hello");
free(a[0]);Структуры, содержащие указатели
Структуры могут содержать указатели, как показано ниже:
Code:
typedef struct
{
char name[21];
char city[21];
char phone[21];
char *comment;
} Addr;
Addr s;
char comm[100];
gets(s.name, 20);
gets(s.city, 20);
gets(s.phone, 20);
gets(comm, 100);
s.comment =
(char *)malloc(sizeof(char[strlen(comm)+1]));
strcpy(s.comment, comm);
Этот метод полезен, когда только некоторые записи фактически содержат комментарий в поле комментария. Если для записи нет комментария, то поле комментария будет состоять только из указателя (4 байта). Те записи, у которых есть комментарий, затем выделяют ровно достаточно места для хранения строки комментария в зависимости от длины строки, введенной пользователем.
Указатели на указатели

Можно и часто полезно создавать указатели на указатели. Этот метод иногда называют дескриптором и полезен в определенных ситуациях, когда операционная система хочет иметь возможность перемещать блоки памяти в куче по своему усмотрению. В следующем примере демонстрируется указатель на указатель:
Code:
int **p;
int *q;
p = (int **)malloc(sizeof(int *));
*p = (int *)malloc(sizeof(int));
**p = 12;
q = *p;
printf("%d\n", *q);
free(q);
free(p);Указатели на структуры, содержащие указатели
Также возможно создавать указатели на структуры, содержащие указатели. В следующем примере используется запись Addr из предыдущего раздела:
Code:
typedef struct
{
char name[21];
char city[21];
char phone[21];
char *comment;
} Addr;
Addr *s;
char comm[100];
s = (Addr *)malloc(sizeof(Addr));
gets(s->name, 20);
gets(s->city, 20);
gets( s->phone, 20);
gets(comm, 100);
s->comment =
(char *)malloc(sizeof(char[strlen(comm)+1]));
strcpy(s->comment, comm);
Указатель s указывает на структуру, содержащую указатель, указывающий на строку.
В этом примере очень легко создать потерянные блоки, если вы не будете осторожны. Например, вот другая версия примера AP.
Code:
s = (Addr *)malloc(sizeof(Addr));
gets(comm, 100);
s->comment =
(char *)malloc(sizeof(char[strlen(comm)+1]));
strcpy(s->comment, comm);
free(s);
Этот код создает потерянный блок, потому что структура, содержащая указатель, указывающий на строку, удаляется до того, как будет удален строковый блок, как показано здесь.
Связывание
Наконец, можно создавать структуры, которые могут указывать на идентичные структуры, и эту возможность можно использовать для связывания целой строки идентичных записей в структуре, называемой связным списком.
Code:
typedef struct
{
char name[21];
char city[21];
char state[21];
Addr *next;
} Addr;
Addr *first;
Компилятор позволит вам это сделать, и его можно использовать с небольшим опытом для создания структур, подобных показанной слева.
Пример связанного стека
Хорошим примером динамических структур данных является простая библиотека стека, которая использует динамический список и включает функции для инициализации, очистки, push и pop. Заголовочный файл библиотеки выглядит так:
Code:
/ * Библиотека стека - Эта библиотека предлагает
минимальные стековые операции для
стек целых чисел (легко заменяемый) * /
typedef int stack_data;
extern void stack_init ();
/ * Инициализирует эту библиотеку. * /
extern void stack_clear ();
/ * Очищает стек от всех записей. * /
внешний int stack_empty ();
/ * Возвращает 1, если стек пуст, в противном случае - 0. * /
extern void stack_push (stack_data d);
/ * Помещает значение d в стек. * /
extern stack_data stack_pop ();
/ * Возвращает верхний элемент стека, и удаляет этот элемент.
Возвращает мусор, если стек пуст. * /Ниже приведен файл кода библиотеки:
Code:
#include "stack.h"
#include <stdio.h>
/ * Библиотека стека - Эта библиотека предлагает
минимальные стековые операции для стека целых чисел * /
struct stack_rec
{
stack_data data;
struct stack_rec *next;
};
struct stack_rec * top = NULL;
void stack_init ()
/ * Инициализирует эту библиотеку. * /
{
top = NULL;
}
void stack_clear ()
/ * Очищает стек от всех записей. * /
{
stack_data x;
while (!stack_empty())
x=stack_pop();
}
int stack_empty()
/ * Возвращает 1, если стек пуст, в противном случае - 0. * /
{
if (top==NULL)
return(1);
else
return(0);
}
/ * Помещает значение d в стек. * /
{
struct stack_rec *temp;
temp=
(struct stack_rec *)malloc(sizeof(struct stack_rec));
temp->data=d;
temp->next=top;
top=temp;
}
stack_data stack_pop()
/ * Возвращает верхний элемент стека,
и удаляет этот элемент.
Возвращает мусор, если стек пуст. * /
{
struct stack_rec *temp;
stack_data d=0;
if (top!=NULL)
{
d=top->data;
temp=top;
top=top->next;
free(temp);
}
return(d);Ошибки C, которых следует избегать:
- Забыть о скобках при ссылке на запись, как в (* p) .i выше
- Неспособность удалить какой-либо блок, который вы выделяете - например, вы не должны указывать top = NULL в функции стека, потому что это действие лишает блоки, которые необходимо удалить.
- Забыть включить stdio.h в какие-либо операции с указателями, чтобы у вас был доступ к NULL.
Что еще стоит попробовать
Добавить DUP, а количество, и добавить функцию в библиотеку стека, чтобы дублировать верхний элемент стека, возвращает счетчик количества элементов в стеке, а также добавить два верхних элемента в стеке.Попробуйте это:
- Создайте программу драйвера и make-файл, а затем скомпилируйте библиотеку стека с драйвером, чтобы убедиться, что он работает.
Использование указателей с массивами
Массивы и указатели тесно связаны в C. Чтобы использовать массивы эффективно, вы должны знать, как использовать с ними указатели. Для полного понимания отношений между ними, вероятно, потребуется несколько дней изучения и экспериментов, но это того стоит.Начнем с простого примера массивов на C:
Code:
#define MAX 10
int main()
{
int a[MAX];
int b[MAX];
int i;
for(i=0; i<MAX; i++)
a[i]=i;
b=a;
return 0;
}Введите этот код и попробуйте его скомпилировать. Вы обнаружите, что C не будет его компилировать. Если вы хотите скопировать a в b, вы должны вместо этого ввести что-то вроде следующего:
Code:
for (i=0; i<MAX; i++)
b[i]=a[i];Или, говоря короче:
Code:
for (i=0; i<MAX; b[i]=a[i], i++);Массивы в C необычны тем, что переменные a и b технически не являются массивами. Вместо этого они являются постоянными указателями на массивы. a и b постоянно указывают на первые элементы своих соответствующих массивов - они содержат адреса a [0] и b [0] соответственно. Поскольку они являются постоянными указателями, вы не можете изменить их адреса. Утверждение a = b;поэтому не работает.
Поскольку a и b являются указателями, с указателями и массивами можно делать несколько интересных вещей. Например, работает следующий код:
Code:
#define MAX 10
void main()
{
int a[MAX];
int i;
int *p;
p=a;
for(i=0; i<MAX; i++)
a[i]=i;
printf("%d\n",*p);
}
Состояние переменных прямо перед началом выполнения цикла for.
Утверждение p = a;работает, потому что это указатель. Технически a указывает на адрес 0-го элемента фактического массива. Этот элемент является целым числом, поэтому a - указатель на одно целое число. Следовательно, объявление p как указателя на целое число и установка его равным a работает. Другой способ сказать то же самое - заменить p = a;с p = & a [0];. Поскольку a содержит адрес a [0], a и & a [0] означают одно и то же.
Теперь, когда p указывает на 0-й элемент a, вы можете делать с ним довольно странные вещи. Переменная является постоянным указателем и не может быть изменен, но р не подлежит таким ограничениям. C на самом деле поощряет вас перемещать его, используя арифметику указателя. Например, если вы скажете p ++;, компилятор знает, что p указывает на целое число, поэтому этот оператор увеличивает p на соответствующее количество байтов, чтобы переместить его к следующему элементу массива. Если p указывал на массив структур длиной 100 байт, p ++;переместится pболее чем на 100 байт. C заботится о деталях размера элемента.
Вы также можете скопировать массив a в b, используя указатели. Следующий код может заменить (для i = 0; i <MAX; a = b, i ++);:
Code:
p=a;
q=b;
for (i=0; i<MAX; i++)
{
*q = *p;
q++;
p++;
}Вы можете сократить этот код следующим образом:
Code:
p=a;
q=b;
for (i=0; i<MAX; i++)
*q++ = *p++;И вы можете сократить его до:
Code:
for (p=a,q=b,i=0; i<MAX; *q++ = *p++, i++);Вы можете передать массив, такой как a или b, в функцию двумя разными способами. Представьте себе дамп функции, который принимает массив целых чисел в качестве параметра и выводит содержимое массива на стандартный вывод. Есть два способа создать дамп кода:
Code:
void dump(int a[],int nia)
{
int i;
for (i=0; i<nia; i++)
printf("%d\n",a[i]);
}
Code:
void dump(int *p,int nia)
{
int i;
for (i=0; i<nia; i++)
printf("%d\n",*p++);
}Струны

Строки в C в значительной степени переплетаются с указателями. Вы должны ознакомиться с концепциями указателей, описанными в предыдущих статьях, чтобы эффективно использовать строки C. Однако, как только вы к ним привыкнете, вы часто сможете очень эффективно выполнять манипуляции со строками.
Строка в C - это просто массив символов. В следующей строке объявляется массив, который может содержать строку длиной до 99 символов.
char str [100];
Он содержит символы, как и следовало ожидать: str [0] - первый символ строки, str [1] - второй символ и так далее. Но почему массив из 100 элементов не может содержать до 100 символов? Поскольку C использует строки с завершающим нулем, это означает, что конец любой строки отмечен значением ASCII 0 (нулевой символ), который также представлен в C как '\ 0' .
Нулевое завершение сильно отличается от того, как многие другие языки обрабатывают строки. Например, в Паскале каждая строка состоит из массива символов с байтом длины, в котором ведется подсчет количества символов, хранящихся в массиве. Эта структура дает Паскалю определенное преимущество, когда вы спрашиваете длину строки. Паскаль может просто вернуть байт длины, тогда как C должен считать символы, пока не найдет '\ 0'. Этот факт в некоторых случаях делает C намного медленнее, чем Pascal, но в других он делает его быстрее, как мы увидим в примерах ниже.
Поскольку C не предоставляет явной поддержки строк в самом языке, все функции обработки строк реализованы в библиотеках. Операции ввода / вывода строк (получение, размещение и т. Д.) Реализованы в <stdio.h>, а набор довольно простых функций обработки строк реализован в <string.h> (в некоторых системах <strings.h >).
Тот факт, что строки не являются родными для C, заставляет вас создавать довольно окольный код. Например, предположим, что вы хотите присвоить одну строку другой строке; то есть вы хотите скопировать содержимое одной строки в другую. В C, как мы видели в прошлой статье, нельзя просто назначить один массив другому. Вы должны копировать его элемент за элементом. Библиотека строк (<string.h> или <strings.h>) содержит функцию strcpy для этой задачи. Вот чрезвычайно распространенный фрагмент кода, который можно найти в обычной программе на C:
Code:
char s[100];
strcpy(s, "hello");После выполнения этих двух строк следующая диаграмма показывает содержимое s:
На верхней диаграмме показан массив с его символами. На нижней диаграмме показаны эквивалентные значения кода ASCII для символов и показано, как C на самом деле думает о строке (как о массиве байтов, содержащих целочисленные значения). См. Как работают биты и байты для обсуждения кодов ASCII.
Следующий код показывает, как использовать strcpy в C:
Code:
#include <string.h>
int main()
{
char s1[100],s2[100];
strcpy(s1,"hello"); /* copy "hello" into s1 */
strcpy(s2,s1); /* copy s1 into s2 */
return 0;
}
Code:
#include <stdio.h>
#include <string.h>
int main()
{
char s1[100],s2[100];
gets(s1);
gets(s2);
if (strcmp(s1,s2)==0)
printf("equal\n");
else if (strcmp(s1,s2)<0)
printf("s1 less than s2\n");
else
printf("s1 greater than s2\n");
return 0;
}Чтобы вы начали создавать строковые функции и помочь вам понять код других программистов (кажется, каждый имеет свой собственный набор строковых функций для специальных целей в программе), мы рассмотрим два примера, strlen и strcpy. Ниже приведена версия strlen строго в стиле Паскаля:
Code:
int strlen(char s[])
{
int x;
x=0;
while (s[x] != '\0')
x=x+1;
return(x);
}Большинство программистов на C избегают этого подхода, потому что он кажется неэффективным. Вместо этого они часто используют подход, основанный на указателях:
Code:
int strlen(char *s)
{
int x=0;
while (*s != '\0')
{
x++;
s++;
}
return(x);
}Вы можете сократить этот код до следующего:
Code:
int strlen(char *s)
{
int x=0;
while (*s++)
x++;
return(x);
}Когда я компилирую эти три фрагмента кода на MicroVAX с помощью gcc без оптимизации и запускаю каждый 20000 раз на 120-символьной строке, первый фрагмент кода дает время 12,3 секунды, второй 12,3 секунды и третий 12,9 секунды. Что это значит? Для меня это означает, что вы должны писать код таким образом, который вам будет легче понять. Указатели обычно дают более быстрый код, но приведенный выше код strlen показывает, что это не всегда так.
Мы можем пройти через ту же эволюцию с помощью strcpy:
Code:
strcpy(char s1[],char s2[])
{
int x;
for (x=0; x<=strlen(s2); x++)
s1[x]=s2[x];
}Обратите внимание, что <= важен в цикле for, потому что код затем копирует '\ 0'. Обязательно скопируйте '\ 0'. Если вы не укажете его, в дальнейшем возникают серьезные ошибки, потому что строка не имеет конца и, следовательно, ее длина неизвестна. Также обратите внимание, что этот код очень неэффективен, потому что strlen вызывается каждый раз в цикле for. Чтобы решить эту проблему, вы можете использовать следующий код:
Code:
strcpy(char s1[],char s2[])
{
int x,len;
len=strlen(s2);
for (x=0; x<=len; x++)
s1[x]=s2[x];
}Версия указателя аналогична.
Code:
strcpy(char *s1,char *s2)
{
while (*s2 != '\0')
{
*s1 = *s2;
s1++;
s2++;
}
}Вы можете сжать этот код дальше:
Code:
strcpy(char *s1,char *s2)
{
while (*s2)
*s1++ = *s2++;
}Если хотите, можете даже сказать while (* s1 ++ = * s2 ++);. Первой версии strcpy требуется 415 секунд для копирования 120-символьной строки 10 000 раз, второй версии - 14,5 секунды, третьей версии - 9,8 секунды, а четвертой - 10,3 секунды. Как видите, указатели обеспечивают здесь значительный прирост производительности.
Прототип функции strcpy в библиотеке строк указывает, что она предназначена для возврата указателя на строку:
Code:
char *strcpy(char *s1,char *s2)Большинство строковых функций в результате возвращают указатель на строку, а strcpy возвращает значение s1 в качестве результата.
Использование указателей со строками иногда может привести к определенному увеличению скорости, и вы можете воспользоваться этим, если немного подумаете о них. Например, предположим, что вы хотите удалить начальные пробелы из строки. Возможно, вы захотите переместить символы поверх пробелов, чтобы удалить их. В C вы можете вообще избежать движения:
Code:
#include <stdio.h>
#include <string.h>
int main()
{
char s[100],*p;
gets(s);
p=s;
while (*p==' ')
p++;
printf("%s\n",p);
return 0;
}Вы научитесь многим другим трюкам со строками, когда будете читать другой код. Практика - ключ к успеху.
Специальное примечание о струнах
Специальное примечание о строковых константахПредположим, вы создали следующие два фрагмента кода и запустили их:
Code:
Fragment 1
{
char *s;
s="hello";
printf("%s\n",s);
}
Fragment 2
{
char s[100];
strcpy(s,"hello");
printf("%s\n",s);
}Эти два фрагмента производят одинаковый результат, но их внутреннее поведение совершенно разное. Во фрагменте 2 нельзя сказать s = "hello";. Чтобы понять различия, вы должны понимать, как таблица строковых констант работает в C.
Когда ваша программа компилируется, компилятор формирует файл объектного кода, который содержит ваш машинный код и таблицу всех строковых констант, объявленных в программе. Во фрагменте 1 утверждение s = "hello";заставляет s указывать на адрес строки hello в таблице строковых констант. Поскольку эта строка находится в таблице строковых констант и, следовательно, технически является частью исполняемого кода, вы не можете ее изменить. Вы можете только указать на него и использовать его только для чтения.
Во фрагменте 2 строка hello также существует в таблице констант, поэтому вы можете скопировать ее в массив символов с именем s. Поскольку s не является указателем, оператор s = "hello";не будет работать во фрагменте 2. Он даже не скомпилируется.
Специальное примечание об использовании строк с malloc
Предположим, вы пишете следующую программу:
Code:
int main()
{
char *s;
s=(char *) malloc (100);
s="hello";
free(s);
return 0;
}Правильный код следует ниже:
Code:
int main()
{
char *s;
s=(char *) malloc (100);
strcpy(s,"hello");
free(s);
return 0;
}Попробуйте это:
- Создайте программу, которая читает строку, содержащую имя, за которым следует пробел, за которым следует фамилия. Напишите функции для удаления начальных или конечных пробелов. Напишите другую функцию, возвращающую фамилию.
- Напишите функцию, преобразующую строку в верхний регистр.
- Напишите функцию, которая получает первое слово из строки и возвращает оставшуюся часть строки.
Ошибки C, которых следует избегать:
Потеря символа \ 0, что легко, если вы не будете осторожны, может привести к очень тонким ошибкам. Убедитесь, что вы копируете \ 0 при копировании строк. Если вы создаете новую строку, убедитесь, что вы поместили в нее \ 0. И если вы копируете одну строку в другую, убедитесь, что принимающая строка достаточно велика, чтобы вместить исходную строку, включая \ 0. Наконец, если вы указываете указателем на некоторые символы, убедитесь, что они заканчиваются на \ 0.
Приоритет оператора
C содержит много операторов, и из-за того, как работает приоритет операторов, взаимодействие между несколькими операторами может сбивать с толку.
х = 5 + 3 * 6;
X получает значение 23, а не 48, потому что в C умножение и деление имеют более высокий приоритет, чем сложение и вычитание.
char * a [10];
Является ли один указатель на массив из 10 символов, или это массив из 10 указателей на характер? Если вы не знаете соглашения о приоритете в C, нет никакого способа узнать. Точно так же в E.11 мы видели это из-за операторов приоритета, таких как * pi = 10;не работает. Вместо этого форма (* p) .i = 10;необходимо использовать для принудительного приоритета.
Следующая таблица из языка программирования C Кернигана и Ричи показывает иерархию приоритетов в C. Верхняя строка имеет наивысший приоритет.
Используя эту таблицу, вы можете увидеть, что char * a [10]; представляет собой массив из 10 указателей на символ. Вы также можете понять, почему скобки нужны, если (* p) .i нужно обрабатывать правильно. После некоторой практики вы запомните большую часть этой таблицы, но время от времени что-то не будет работать, потому что вас поймали на тонкой проблеме приоритета.Code:Ассоциативность операторов ( [ -. Слева направо ! - ++ - {- + * & (приведение к типу) sizeof Справа налево (в строке выше +, - и * - унарные формы) * / % Слева направо + - Слева направо << >> Слева направо <<=>> = Слева направо ==! = Слева направо & Слева направо ^ Слева направо | Слева направо && Слева направо || Слева направо ?: Слева направо = + = - = * = / =% = & = ^ = | = << = >> = Справа налево , Слева направо
Аргументы командной строки
C предоставляет довольно простой механизм для получения параметров командной строки, введенных пользователем. Он передает параметр argv в основную функцию программы. Структуры argv присутствуют в большом количестве более сложных вызовов библиотеки, поэтому понимание их полезно любому программисту на C.
Введите следующий код и скомпилируйте его:
Code:#include <stdio.h> int main(int argc, char *argv[]) { int x; printf("%d\n",argc); for (x=0; x<argc; x++) printf("%s\n",argv[x]); return 0; }
В этом коде основная программа принимает два параметра: argv и argc. Параметр argv - это массив указателей на строку, которая содержит параметры, введенные при вызове программы из командной строки UNIX. Целое число argc содержит количество параметров. Этот конкретный фрагмент кода вводит параметры командной строки. Чтобы попробовать это, скомпилируйте код в исполняемый файл с именем aaa и введите aaa xxx yyy zzz. Код будет печатать параметры командной строки xxx, yyy и zzz, по одному в каждой строке.
char *argv[] строка представляет собой массив указателей на строки. Другими словами, каждый элемент массива является указателем, и каждый указатель указывает на строку (технически, на первый символ строки). Таким образом, argv [0] указывает на строку, содержащую первый параметр в командной строке (имя программы), argv [1] указывает на следующий параметр и так далее. Переменная argc сообщает вам, сколько указателей в массиве действительны. Вы обнаружите, что предыдущий код не делает ничего, кроме печати каждой допустимой строки, на которую указывает argv.
Поскольку существует argv, вы можете позволить своей программе довольно легко реагировать на параметры командной строки, введенные пользователем. Например, ваша программа может определять слово help как первый параметр, следующий за именем программы, и выгружать файл справки в стандартный вывод. Имена файлов также могут передаваться и использоваться в ваших операторах fopen.
Двоичные файлы
Двоичные файлы очень похожи на массивы структур, за исключением того, что структуры находятся в файле на диске, а не в массиве в памяти. Поскольку структуры в двоичном файле находятся на диске, вы можете создавать их очень большие коллекции (ограниченные только вашим доступным дисковым пространством). Они также постоянны и всегда доступны. Единственный недостаток - медленность, связанная с временем доступа к диску.
У двоичных файлов есть две особенности, которые отличают их от текстовых файлов:- Вы можете мгновенно перейти к любой структуре в файле, которая обеспечивает произвольный доступ, как в массиве.
- Вы можете изменить содержимое структуры в любом месте файла в любое время.
Двоичные файлы также обычно имеют более быстрое время чтения и записи, чем текстовые файлы, потому что двоичный образ записи сохраняется непосредственно из памяти на диск (или наоборот). В текстовом файле все должно быть преобразовано в текст, а это требует времени.
C очень четко поддерживает концепцию файла структур. Как только вы открываете файл, вы можете читать структуру, писать структуру или искать любую структуру в файле. Эта концепция файла поддерживает концепцию указателя файла. Когда файл открыт, указатель указывает на запись 0 (первая запись в файле). Любая операция чтения читает текущую указанную структуру и перемещает указатель на одну структуру вниз. Любая операция записи выполняет запись в указанную в данный момент структуру и перемещает указатель на одну структуру вниз. Поиск перемещает указатель на запрошенную запись.
Имейте в виду, что C рассматривает все в файле на диске как блоки байтов, считываемые с диска в память или считываемые из памяти на диск. C использует указатель файла, но может указывать на любое место байта в файле. Следовательно, вам нужно следить за вещами.
Следующая программа иллюстрирует эти концепции:
Code:#include <stdio.h> / * случайное описание записи - может быть что угодно * / struct rec { int x,y,z; }; / * записывает, а затем читает 10 произвольных записей из файла "junk". * / from the file "junk". */ int main() { int i,j; FILE *f; struct rec r; / * создаем файл из 10 записей * / f=fopen("junk","w"); if (!f) return 1; for (i=1;i<=10; i++) { r.x=i; fwrite(&r,sizeof(struct rec),1,f); } fclose(f); / * читаем 10 записей * / f=fopen("junk","r"); if (!f) return 1; for (i=1;i<=10; i++) { fread(&r,sizeof(struct rec),1,f); printf("%d\n",r.x); } fclose(f); printf("\n"); / * используем fseek для чтения 10 записей в обратном порядке * / f=fopen("junk","r"); if (!f) return 1; for (i=9; i>=0; i--) { fseek(f,sizeof(struct rec)*i,SEEK_SET); fread(&r,sizeof(struct rec),1,f); printf("%d\n",r.x); } fclose(f); printf("\n"); / * использовать fseek для чтения всех остальных записей * / f=fopen("junk","r"); if (!f) return 1; fseek(f,0,SEEK_SET); for (i=0;i<5; i++) { fread(&r,sizeof(struct rec),1,f); printf("%d\n",r.x); fseek(f,sizeof(struct rec),SEEK_CUR); } fclose(f); printf("\n"); / * использовать fseek для чтения 4-й записи, измените его и запишите обратно * / f=fopen("junk","r+"); if (!f) return 1; fseek(f,sizeof(struct rec)*3,SEEK_SET); fread(&r,sizeof(struct rec),1,f); r.x=100; fseek(f,sizeof(struct rec)*3,SEEK_SET); fwrite(&r,sizeof(struct rec),1,f); fclose(f); printf("\n"); / * прочтите 10 записей, чтобы застраховаться 4-я запись была изменена * / f=fopen("junk","r"); if (!f) return 1; for (i=1;i<=10; i++) { fread(&r,sizeof(struct rec),1,f); printf("%d\n",r.x); } fclose(f); return 0; }
В этой программе использовалось описание структуры rec, но вы можете использовать любое описание структуры, какое захотите. Вы можете видеть, что команды fopen и fclose работают точно так же, как и для текстовых файлов.
Новые функции здесь - fread, fwrite и fseek. Функция fread принимает четыре параметра:- Адрес памяти
- Количество байтов для чтения на блок
- Количество блоков для чтения
- Файловая переменная
Таким образом, строка fread (& r, sizeof (struct rec), 1, f);говорит читать 12 байтов (размер rec ) из файла f (из текущего местоположения указателя файла) в адрес памяти & r. Требуется один блок из 12 байтов. Было бы так же легко прочитать 100 блоков с диска в массив в памяти, изменив 1 на 100.
Функция fwrite работает так же, но перемещает блок байтов из памяти в файл. Функция fseek перемещает указатель файла на байт в файле. Как правило, вы перемещаете указатель с шагом sizeof (struct rec), чтобы он оставался на границах записи. При поиске вы можете использовать три варианта:- SEEK_SET
- SEEK_CUR
- SEEK_END
В приведенном выше коде появляется несколько разных вариантов. В частности, обратите внимание на раздел, в котором файл открывается в режиме r +. Это открывает файл для чтения и записи, что позволяет изменять записи. Код ищет запись, читает ее и изменяет поле; затем он ищет назад, потому что чтение сместило указатель, и записывает изменение обратно.
Last edited: