Для обычного Васи Пупкина информационные технологии (ИТ) - это загадочная вселенная, наполненная неразборчивыми языками программирования и дорогостоящим оборудованием. Подслушивание ИТ-специалистов похоже на подслушивание разговора на иностранном языке. Но, несмотря на этот, казалось бы, непреодолимый языковой барьер, для лиц, принимающих решения в компаниях и организациях, может быть критически важно понять мир ИТ. Одна из важнейших ИТ-концепций - интеграция данных.
На первый взгляд, интеграция данных кажется простой идеей. Поскольку многие организации хранят информацию в нескольких базах данных, им нужен способ извлекать данные из разных источников и собирать их единым способом. Например, представим, что компания-производитель электроники готовится выпустить новое мобильное устройство. Отдел маркетинга может захотеть получить информацию о клиентах из базы данных отдела продаж и сравнить ее с информацией из отдела продуктов, чтобы создать целевой список продаж. Хорошая система интеграции данных позволила бы отделу маркетинга просматривать информацию из обоих источников единообразно, исключая любую информацию, не относящуюся к поиску.
На самом деле интеграция данных - сложная дисциплина. Универсального подхода к интеграции данных не существует, и многие методы, которые используют ИТ-специалисты, все еще развиваются. Некоторые подходы к интеграции данных могут работать лучше, чем другие для организации, в зависимости от потребностей этой организации. Мы внимательно рассмотрим некоторые общие стратегии, которые ИТ-специалисты используют для интеграции нескольких источников данных и входа в мир управления базами данных.
Каковы основы интеграции данных? Узнайте в следующем разделе.
СОДЕРЖАНИЕ
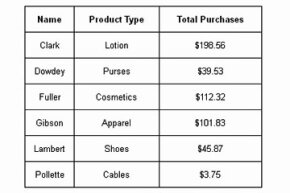
В этой простой таблице показаны покупки клиентов.
Интеграция данных в основном сосредоточена на базах данных . База данных - это организованный набор данных. Это похоже на файловую систему, которая представляет собой организационную структуру для файлов, поэтому их легко найти, получить к ним доступ и управлять ими.
Есть разные способы категоризации баз данных. Некоторые люди предпочитают классифицировать их по типу данных, хранящихся в базах данных. Например, вы можете классифицировать базу данных как базу данных мультимедиа, если вся хранимая в ней информация содержится в видео- или звуковых файлах.
Другой метод классификации смотрит на то, как базы данных организуют данные. Организационная структура базы данных называется схемой. Распространенным организационным методом является использование таблиц для отображения взаимосвязи между различными точками данных. Таблицы похожи на электронные таблицы. Столбцы определяют категории данных, а строки - записи. База данных, использующая этот подход, является реляционной базой данных.
Базы данных объектно-ориентированного программирования (ООП) используют другой подход к организации данных. Язык ООП - это отход от традиционных подходов к программированию, которые следуют шаблону вставки данных в набор инструкций и последующего вывода. Вместо этого язык ООП фокусируется на определении данных как объектов, а затем на определении того, как различные объекты связаны и взаимодействуют друг с другом.
Чтобы создать базу данных ООП, сначала вы должны определить все объекты, которые вы планируете хранить в базе данных. Затем вы должны определить способ связи каждого объекта со всеми остальными объектами в базе данных. После идентификации объекта вы помещаете его в класс или набор объектов. Чтобы определить класс, вы должны определить, какие данные должен иметь каждый объект в этом классе и какие логические последовательности, называемые методами, будут влиять на эти объекты. Объекты в системе могут связываться с вами или другими объектами с помощью интерфейсов, называемых сообщениями.
Это легче понять на примере. Допустим, вы создаете базу данных, содержащую информацию об американском спорте. Вы решили начать с определения бейсбольных команд. Создав определение бейсбольной команды, вы можете обобщить его как класс в базе данных. Atlanta Braves будет особым экземпляром этого класса, также известного как объект. Класс бейсбольных команд принадлежит суперклассу американских спортивных команд, который также включает другие классы, такие как футбол и футбольные команды.
Чтобы получить доступ к информации в базе данных (независимо от того, как она организовывает данные), вы используете запрос. Запрос - это просто запрос информации. Люди и приложения могут отправлять запросы к базам данных. База данных отвечает на запросы, отправляя данные, соответствующие параметрам исходного запроса. Запросы полагаются на специальные компьютерные языки, такие как язык структурированных запросов (SQL). Если вы когда-либо использовали поисковую систему в Интернете, вы отправляли запрос - ваши условия поиска.
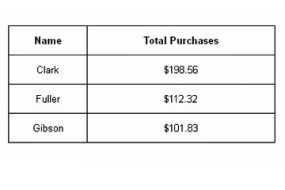
В этом представлении отображаются только данные, относящиеся к запросу «клиенты, которые приобрели товары на сумму более 100 долларов США».
База данных отвечает на запросы, создавая представление данных. Представление - это особый способ отображения данных. В системе интеграции данных возвращенное представление показывает только данные, непосредственно связанные с исходным запросом. В нашем примере таблицы, если вы отправили запрос для всех клиентов, которые купили товары на сумму более 100 долларов, вы получите следующий результат:
В этом представлении отображаются только данные, относящиеся к запросу «клиенты, которые приобрели товары на сумму более 100 долларов США». Обратите внимание, что он не показывает, какие продукты были куплены, и не отображает клиентов, которые приобрели менее 100 долларов США.
Каковы разные подходы к интеграции данных? Узнайте в следующем разделе.
Что такое данные?
Данные могут быть любой информацией. Это может быть содержимое ячейки в электронной таблице. Это может быть звуковой файл или видео. Это может быть строка слов в документе. Это может быть необработанная информация, созданная на выходе компьютерной программы. Или это может быть информация, используемая для описания файла. Интеграция данных ориентирована на информацию, а не на файлы.
Предположим, вы собираетесь отправиться в путешествие и хотите узнать, на что похоже движение, прежде чем решить, по какому маршруту выехать из города. Вот как различные подходы к интеграции данных будут обрабатывать ваш запрос.
Ручная интеграция подход оставил бы всю работу для вас. Во-первых, вам нужно знать, где искать свои данные. Вам нужно будет знать физическое местоположение как для отчета о загруженности дорог, так и для карты вашего города. Вам нужно будет получить отчет о трафике и данные карты непосредственно из соответствующих баз данных, а затем сравнить два набора данных друг с другом, чтобы выяснить, какой маршрут лучше всего за город.
Если бы вы использовали общий подход к пользовательскому интерфейсу, вам пришлось бы сделать немного меньше работы. Вы можете использовать такой интерфейс, как World Wide Web, чтобы сделать запрос. Результаты запроса появятся в виде представления в интерфейсе. Вам все равно придется сравнивать отчет о трафике с картой, чтобы определить лучший маршрут, но, по крайней мере, интерфейс позаботится о поиске и извлечении данных.
Некоторые подходы к интеграции полагаются на приложения, которые сделают всю работу за вас. Приложения, представляющие собой специализированные компьютерные программы, будут искать, извлекать и интегрировать информацию за вас. В процессе интеграции приложения должны манипулировать данными, чтобы информация из одного источника была совместима с информацией из другого источника. В нашем примере это будет означать, что вы отправите запрос в приложение, и оно представит представление, в котором карта вашего города сочетается с данными из отчетов о дорожном движении. Проблема с этим подходом заключается в том, что приложения становятся сложными и трудными для программирования по мере увеличения количества источников и форматов данных.
Затем есть общий метод хранения данных, также известный как хранилище данных. Используя этот метод, все данные из различных баз данных, которые вы собираетесь интегрировать, извлекаются, преобразуются и загружаются. Это означает, что хранилище данных сначала извлекает все данные из различных источников данных. Затем хранилище данных преобразует все данные в общий формат, чтобы один набор данных был совместим с другим. Затем он загружает эти новые данные в свою базу данных. Когда вы отправляете запрос, хранилище данных находит данные, извлекает их и представляет вам в интегрированном представлении. Используя наш пример, в хранилище данных можно найти самую свежую информацию, содержащуюся в отчетах о дорожном движении и на картах вашего города. Затем он объединит их вместе и отправит вам вид. У этой системы есть несколько преимуществ и недостатков, которые мы рассмотрим в следующем разделе.
Большинство разработчиков систем интеграции данных полагают, что конечной целью является создание как можно меньшего объема работы для конечного пользователя, поэтому они, как правило, сосредотачиваются на приложениях и методах хранения данных.
Что именно делают хранилища данных? Узнайте дальше.
Это был триумф
Страницы портала, такие как iGoogle или My Yahoo, являются примерами обычных пользовательских интерфейсов. Порталы извлекают информацию из нескольких источников, но не интегрируют данные в единое представление.
Обычно запросы к хранилищу данных обрабатываются очень быстро. Это потому, что хранилище данных уже проделало основную работу по извлечению, преобразованию и объединению данных. Сторона пользователя хранилища данных называется внешним интерфейсом, поэтому с точки зрения внешнего интерфейса хранилище данных является эффективным способом получения интегрированных данных.
С точки зрения серверной части это отдельная история. Менеджеры баз данных должны тщательно продумать систему хранилища данных, чтобы сделать ее эффективной и действенной. Преобразование данных, собранных из разных источников, в общий формат может быть особенно трудным. Система требует последовательного подхода к описанию и кодированию данных.
В хранилище должна быть база данных, достаточно большая для хранения данных, собранных из нескольких источников. Некоторые хранилища данных включают дополнительный этап, называемый витриной данных. Хранилище данных берет на себя обязанности по агрегированию данных, а витрина данных отвечает на запросы пользователей, извлекая и комбинируя соответствующие данные из хранилища.
Одна из проблем с хранилищами данных заключается в том, что информация в них не всегда актуальна. Это связано с тем, как работают хранилища данных - они периодически извлекают информацию из других баз данных. Если данные в этих базах данных изменяются между извлечениями, запросы к хранилищу данных не приведут к наиболее актуальным и точным представлениям. Если данные в системе меняются редко, это не имеет большого значения. Однако для других приложений это проблематично.
Возвращаясь к нашему предыдущему примеру с отчетом о трафике и картой, вы можете увидеть, в чем проблема. Хотя карта города может не требовать частого обновления, условия дорожного движения могут резко измениться за относительно короткий промежуток времени. Хранилище данных может не очень часто извлекать данные, а это означает, что чувствительная ко времени информация может быть ненадежной. Для таких приложений лучше использовать другой подход к интеграции данных.
Какая альтернатива хранилищу данных? Узнайте в следующем разделе.
Мета? Я почти не знал ее!
Описание данных называется метаданными. Метаданные полезны для именования и определения данных, а также для описания взаимосвязи одного набора данных с другими наборами. Системы интеграции данных используют метаданные для поиска информации, относящейся к запросам.
ИТ-специалисты определяют системы интеграции данных с помощью схем. Унифицированное представление, созданное на основе обработанного запроса, представляет собой глобальную схему . Структура различных источников данных и то, как они соотносятся друг с другом, и есть исходная схема. Способ взаимосвязи глобальной и исходной схем называется сопоставлением . Подумайте исходную схему как план для всех данных в системе, в то время как глобальная схема является основой для представления, представленного в ответ на запрос.
Существует два основных подхода к решению запросов в системе, интегрированной с данными: глобальный как представление и локальный как представление. Каждый подход фокусируется на определенной части общей системы и имеет свои преимущества и недостатки.
В подходе global as-view основное внимание уделяется глобальной схеме. Пока источники данных остаются согласованными, хорошо работает подход global as-view. Изменить настройку глобальной схемы легко. Это означает, что анализировать один и тот же общий набор данных разными способами несложно. Однако добавление или удаление источников данных в системе проблематично, поскольку это влияет на данные в системе в целом.
Метод локального просмотра использует противоположный подход. Основное внимание уделяется источникам данных. Пока глобальная схема остается постоянной, в систему легко добавлять или удалять источники данных. Схема ищет те же типы данных и отношений в новых источниках данных. При таком подходе сложно изменить параметры глобальной схемы. Если вы хотите анализировать источники данных по-новому, вам придется переопределить всю систему.
Вот и история интеграции данных. В следующий раз, когда вы посмотрите на карту погоды или вызовете отфильтрованный набор данных, вы будете знать о сложной серии процессов, происходящих в фоновом режиме, что делает все это возможным.
Club Fed
Системы федеративных баз данных (FDBMS) представляют собой совокупности сетевых автономных баз данных. Эти системы решают несколько сложных задач:
На первый взгляд, интеграция данных кажется простой идеей. Поскольку многие организации хранят информацию в нескольких базах данных, им нужен способ извлекать данные из разных источников и собирать их единым способом. Например, представим, что компания-производитель электроники готовится выпустить новое мобильное устройство. Отдел маркетинга может захотеть получить информацию о клиентах из базы данных отдела продаж и сравнить ее с информацией из отдела продуктов, чтобы создать целевой список продаж. Хорошая система интеграции данных позволила бы отделу маркетинга просматривать информацию из обоих источников единообразно, исключая любую информацию, не относящуюся к поиску.
На самом деле интеграция данных - сложная дисциплина. Универсального подхода к интеграции данных не существует, и многие методы, которые используют ИТ-специалисты, все еще развиваются. Некоторые подходы к интеграции данных могут работать лучше, чем другие для организации, в зависимости от потребностей этой организации. Мы внимательно рассмотрим некоторые общие стратегии, которые ИТ-специалисты используют для интеграции нескольких источников данных и входа в мир управления базами данных.
Каковы основы интеграции данных? Узнайте в следующем разделе.
СОДЕРЖАНИЕ
- Основы интеграции данных
- Подходы к интеграции данных
- Хранилища данных
- Сетевые базы данных
Основы интеграции данных
В этой простой таблице показаны покупки клиентов.
Интеграция данных в основном сосредоточена на базах данных . База данных - это организованный набор данных. Это похоже на файловую систему, которая представляет собой организационную структуру для файлов, поэтому их легко найти, получить к ним доступ и управлять ими.
Есть разные способы категоризации баз данных. Некоторые люди предпочитают классифицировать их по типу данных, хранящихся в базах данных. Например, вы можете классифицировать базу данных как базу данных мультимедиа, если вся хранимая в ней информация содержится в видео- или звуковых файлах.
Другой метод классификации смотрит на то, как базы данных организуют данные. Организационная структура базы данных называется схемой. Распространенным организационным методом является использование таблиц для отображения взаимосвязи между различными точками данных. Таблицы похожи на электронные таблицы. Столбцы определяют категории данных, а строки - записи. База данных, использующая этот подход, является реляционной базой данных.
Базы данных объектно-ориентированного программирования (ООП) используют другой подход к организации данных. Язык ООП - это отход от традиционных подходов к программированию, которые следуют шаблону вставки данных в набор инструкций и последующего вывода. Вместо этого язык ООП фокусируется на определении данных как объектов, а затем на определении того, как различные объекты связаны и взаимодействуют друг с другом.
Чтобы создать базу данных ООП, сначала вы должны определить все объекты, которые вы планируете хранить в базе данных. Затем вы должны определить способ связи каждого объекта со всеми остальными объектами в базе данных. После идентификации объекта вы помещаете его в класс или набор объектов. Чтобы определить класс, вы должны определить, какие данные должен иметь каждый объект в этом классе и какие логические последовательности, называемые методами, будут влиять на эти объекты. Объекты в системе могут связываться с вами или другими объектами с помощью интерфейсов, называемых сообщениями.
Это легче понять на примере. Допустим, вы создаете базу данных, содержащую информацию об американском спорте. Вы решили начать с определения бейсбольных команд. Создав определение бейсбольной команды, вы можете обобщить его как класс в базе данных. Atlanta Braves будет особым экземпляром этого класса, также известного как объект. Класс бейсбольных команд принадлежит суперклассу американских спортивных команд, который также включает другие классы, такие как футбол и футбольные команды.
Чтобы получить доступ к информации в базе данных (независимо от того, как она организовывает данные), вы используете запрос. Запрос - это просто запрос информации. Люди и приложения могут отправлять запросы к базам данных. База данных отвечает на запросы, отправляя данные, соответствующие параметрам исходного запроса. Запросы полагаются на специальные компьютерные языки, такие как язык структурированных запросов (SQL). Если вы когда-либо использовали поисковую систему в Интернете, вы отправляли запрос - ваши условия поиска.
В этом представлении отображаются только данные, относящиеся к запросу «клиенты, которые приобрели товары на сумму более 100 долларов США».
База данных отвечает на запросы, создавая представление данных. Представление - это особый способ отображения данных. В системе интеграции данных возвращенное представление показывает только данные, непосредственно связанные с исходным запросом. В нашем примере таблицы, если вы отправили запрос для всех клиентов, которые купили товары на сумму более 100 долларов, вы получите следующий результат:
В этом представлении отображаются только данные, относящиеся к запросу «клиенты, которые приобрели товары на сумму более 100 долларов США». Обратите внимание, что он не показывает, какие продукты были куплены, и не отображает клиентов, которые приобрели менее 100 долларов США.
Каковы разные подходы к интеграции данных? Узнайте в следующем разделе.
Что такое данные?
Данные могут быть любой информацией. Это может быть содержимое ячейки в электронной таблице. Это может быть звуковой файл или видео. Это может быть строка слов в документе. Это может быть необработанная информация, созданная на выходе компьютерной программы. Или это может быть информация, используемая для описания файла. Интеграция данных ориентирована на информацию, а не на файлы.
Подходы к интеграции данных
Основываясь на предыдущем разделе, вы можете подумать, что базы данных довольно сложные. Это справедливое предположение, и оно помогает объяснить, почему интеграция данных все еще развивается, несмотря на то, что ей более 30 лет. Цель интеграции данных - собрать данные из разных источников, объединить их и представить таким образом, чтобы они представлялись единым целым.Предположим, вы собираетесь отправиться в путешествие и хотите узнать, на что похоже движение, прежде чем решить, по какому маршруту выехать из города. Вот как различные подходы к интеграции данных будут обрабатывать ваш запрос.
Ручная интеграция подход оставил бы всю работу для вас. Во-первых, вам нужно знать, где искать свои данные. Вам нужно будет знать физическое местоположение как для отчета о загруженности дорог, так и для карты вашего города. Вам нужно будет получить отчет о трафике и данные карты непосредственно из соответствующих баз данных, а затем сравнить два набора данных друг с другом, чтобы выяснить, какой маршрут лучше всего за город.
Если бы вы использовали общий подход к пользовательскому интерфейсу, вам пришлось бы сделать немного меньше работы. Вы можете использовать такой интерфейс, как World Wide Web, чтобы сделать запрос. Результаты запроса появятся в виде представления в интерфейсе. Вам все равно придется сравнивать отчет о трафике с картой, чтобы определить лучший маршрут, но, по крайней мере, интерфейс позаботится о поиске и извлечении данных.
Некоторые подходы к интеграции полагаются на приложения, которые сделают всю работу за вас. Приложения, представляющие собой специализированные компьютерные программы, будут искать, извлекать и интегрировать информацию за вас. В процессе интеграции приложения должны манипулировать данными, чтобы информация из одного источника была совместима с информацией из другого источника. В нашем примере это будет означать, что вы отправите запрос в приложение, и оно представит представление, в котором карта вашего города сочетается с данными из отчетов о дорожном движении. Проблема с этим подходом заключается в том, что приложения становятся сложными и трудными для программирования по мере увеличения количества источников и форматов данных.
Затем есть общий метод хранения данных, также известный как хранилище данных. Используя этот метод, все данные из различных баз данных, которые вы собираетесь интегрировать, извлекаются, преобразуются и загружаются. Это означает, что хранилище данных сначала извлекает все данные из различных источников данных. Затем хранилище данных преобразует все данные в общий формат, чтобы один набор данных был совместим с другим. Затем он загружает эти новые данные в свою базу данных. Когда вы отправляете запрос, хранилище данных находит данные, извлекает их и представляет вам в интегрированном представлении. Используя наш пример, в хранилище данных можно найти самую свежую информацию, содержащуюся в отчетах о дорожном движении и на картах вашего города. Затем он объединит их вместе и отправит вам вид. У этой системы есть несколько преимуществ и недостатков, которые мы рассмотрим в следующем разделе.
Большинство разработчиков систем интеграции данных полагают, что конечной целью является создание как можно меньшего объема работы для конечного пользователя, поэтому они, как правило, сосредотачиваются на приложениях и методах хранения данных.
Что именно делают хранилища данных? Узнайте дальше.
Это был триумф
Страницы портала, такие как iGoogle или My Yahoo, являются примерами обычных пользовательских интерфейсов. Порталы извлекают информацию из нескольких источников, но не интегрируют данные в единое представление.
Хранилища данных
Как мы видели ранее, хранилище данных - это база данных, в которой хранится информация из других баз данных с использованием общего формата. Это настолько же конкретно, насколько вы можете получить при описании хранилищ данных. Нет единого определения, которое диктовало бы, что такое хранилища данных или как проектировщики должны их создавать. В результате существует несколько различных способов создания хранилищ данных, и одно хранилище данных может выглядеть и вести себя совершенно иначе, чем другое.Обычно запросы к хранилищу данных обрабатываются очень быстро. Это потому, что хранилище данных уже проделало основную работу по извлечению, преобразованию и объединению данных. Сторона пользователя хранилища данных называется внешним интерфейсом, поэтому с точки зрения внешнего интерфейса хранилище данных является эффективным способом получения интегрированных данных.
С точки зрения серверной части это отдельная история. Менеджеры баз данных должны тщательно продумать систему хранилища данных, чтобы сделать ее эффективной и действенной. Преобразование данных, собранных из разных источников, в общий формат может быть особенно трудным. Система требует последовательного подхода к описанию и кодированию данных.
В хранилище должна быть база данных, достаточно большая для хранения данных, собранных из нескольких источников. Некоторые хранилища данных включают дополнительный этап, называемый витриной данных. Хранилище данных берет на себя обязанности по агрегированию данных, а витрина данных отвечает на запросы пользователей, извлекая и комбинируя соответствующие данные из хранилища.
Одна из проблем с хранилищами данных заключается в том, что информация в них не всегда актуальна. Это связано с тем, как работают хранилища данных - они периодически извлекают информацию из других баз данных. Если данные в этих базах данных изменяются между извлечениями, запросы к хранилищу данных не приведут к наиболее актуальным и точным представлениям. Если данные в системе меняются редко, это не имеет большого значения. Однако для других приложений это проблематично.
Возвращаясь к нашему предыдущему примеру с отчетом о трафике и картой, вы можете увидеть, в чем проблема. Хотя карта города может не требовать частого обновления, условия дорожного движения могут резко измениться за относительно короткий промежуток времени. Хранилище данных может не очень часто извлекать данные, а это означает, что чувствительная ко времени информация может быть ненадежной. Для таких приложений лучше использовать другой подход к интеграции данных.
Какая альтернатива хранилищу данных? Узнайте в следующем разделе.
Мета? Я почти не знал ее!
Описание данных называется метаданными. Метаданные полезны для именования и определения данных, а также для описания взаимосвязи одного набора данных с другими наборами. Системы интеграции данных используют метаданные для поиска информации, относящейся к запросам.
Сетевые базы данных
Для систем интеграции данных, которые полагаются на часто изменяющуюся информацию, подход хранилища данных не идеален. Один из способов, которым ИТ-специалисты пытаются решить эту проблему, - это проектировать системы, которые извлекают данные непосредственно из отдельных источников данных. Поскольку нет централизованной базы данных, предназначенной для анализа, классификации и интеграции данных при подготовке к запросам пользователей, эти обязанности ложатся на другие части системы.ИТ-специалисты определяют системы интеграции данных с помощью схем. Унифицированное представление, созданное на основе обработанного запроса, представляет собой глобальную схему . Структура различных источников данных и то, как они соотносятся друг с другом, и есть исходная схема. Способ взаимосвязи глобальной и исходной схем называется сопоставлением . Подумайте исходную схему как план для всех данных в системе, в то время как глобальная схема является основой для представления, представленного в ответ на запрос.
Существует два основных подхода к решению запросов в системе, интегрированной с данными: глобальный как представление и локальный как представление. Каждый подход фокусируется на определенной части общей системы и имеет свои преимущества и недостатки.
В подходе global as-view основное внимание уделяется глобальной схеме. Пока источники данных остаются согласованными, хорошо работает подход global as-view. Изменить настройку глобальной схемы легко. Это означает, что анализировать один и тот же общий набор данных разными способами несложно. Однако добавление или удаление источников данных в системе проблематично, поскольку это влияет на данные в системе в целом.
Метод локального просмотра использует противоположный подход. Основное внимание уделяется источникам данных. Пока глобальная схема остается постоянной, в систему легко добавлять или удалять источники данных. Схема ищет те же типы данных и отношений в новых источниках данных. При таком подходе сложно изменить параметры глобальной схемы. Если вы хотите анализировать источники данных по-новому, вам придется переопределить всю систему.
Вот и история интеграции данных. В следующий раз, когда вы посмотрите на карту погоды или вызовете отфильтрованный набор данных, вы будете знать о сложной серии процессов, происходящих в фоновом режиме, что делает все это возможным.
Club Fed
Системы федеративных баз данных (FDBMS) представляют собой совокупности сетевых автономных баз данных. Эти системы решают несколько сложных задач:
- Прием запросов пользователей
- Разделение их на несколько подзапросов
- Использование специальных тегов, называемых оболочками, для определения подзапросов таким образом, чтобы каждая соответствующая база данных могла понять
- Отправка этих обернутых подзапросов в соответствующие базы данных
- Принятие данных, отправленных обратно из этих баз данных
- Интеграция всех данных в единое представление и
- Представление этого представления пользователю.