When we communicate with our customers, being experts in this field, we actively use the appropriate terminology, in particular the word “recognition.” At the same time, the listening audience, brought up on Cuneiform and FineReader, often puts into this term the task of matching a cut-out section of an image to a certain number (character code), which these days is solved by a neural network approach and is far from the first stage in the problem of information recognition. First, you need to localize the card in the image, find information fields, and perform segmentation into characters. From a formal point of view, each listed subtask is an independent recognition task. And while there are proven approaches and tools for training neural networks, orientation and segmentation tasks require an individual approach each time. If you are interested in learning about the approaches we used to solve the problem of bank card recognition, then welcome to the cat!
Recognizing credit card data is both a highly relevant and very interesting task from an algorithmic point of view. A well-implemented plastic card recognition program can eliminate the need for a person to enter most of the data manually when making online payments and payments in mobile applications. From a recognition point of view, a bank card is a complex document of a standard size (85.6 × 53.98 mm), made on a standard form and containing a certain set of fields (both mandatory and optional): card number, cardholder name, date issue, expiration date, account number, CVV2 code or its equivalent. Some of the fields are on the front side, the other part is on the back. And despite the fact that to complete a payment transaction you only need to specify the card number, almost all payment systems (as authentication) additionally require you to indicate the name of the card holder, expiration date and CVV2 code. Let's focus further on the task of recognizing information fields on the front side of a card (objectively, it is many times more difficult).
So, to make an online payment, in most cases you need to recognize the card number, the holder’s name and the card’s expiration date in the image.
The first step is to find the coordinates of the corners of the card. Since we know the geometric characteristics of the card (all cards are made strictly in accordance with the ISO 781 standard), to determine the quadrilateral of the card we will use the algorithm for searching and enumerating straight lines.
Given a known quadrilateral, it is not difficult to calculate and apply a projective transformation to the image, bringing the map image to an orthogonal form with a fixed resolution. We will assume that such a corrected image comes as input to subsequent stages - orientation and recognition of specific information fields.
From an architectural point of view, the recognition of the three target fields consists of the same parts:
Although the recognition steps are the same, the complexity varies greatly. The easiest way to recognize the card number (it’s not for nothing that there are a sufficient number of SDKs for various mobile platforms, including those posted in the public domain) due to a whole set of reasons:
The situation is more complicated with the two remaining fields: expiration date and cardholder name. In this article, we will take a closer look at the procedure for recognizing the card’s expiration date (name recognition is performed in a similar way).
The first step is to localize the field on the card (unlike the number, the location of this field is not standardized). Using the “brute force method” over the entire map area is not very promising, since the corresponding text fragment is very short (most often 5 characters), syntactic redundancy is low, and the probability of a false detection on an arbitrary text fragment or even a colorful area of the background is unacceptably high. Therefore, we’ll use a trick: we’ll look not for the date itself, but for some information zone located under the card number and having a stable geometric structure.

Figure 1. Examples of the required three-line information zone
The zone in question is divided into three lines, one of which is often empty. It is important that the location of the date line within this zone is well defined. This paradoxical phrase means the following: in the case when there are two non-blank lines in a zone, their line spacing either coincides with the line spacing of three-line zones, or is approximately equal to the sum of double the spacing and line height.
Finding a zone and dividing it into 3 lines is complicated by the presence of a background on the map, which, as we have already said, is varied. To solve this problem, a combination of filters is applied to the card image, the purpose of which is to highlight the vertical boundaries of the letters and suppress the remaining details of the image. The sequence of filters is as follows:

Figure 2. Pre-filtering of a credit card image: a) original image, b) grayscale image c) vertical edges image, d) filtered vertical edges image
In our implementation, to save time, morphological operations are implemented using van Herk algorithm. It allows you to calculate morphological operations with a rectangular primitive in a time that does not depend on the size of the primitive, which allows you to use complex large-area morphological filters in document recognition tasks in real time.
After filtering, the pixel intensities of the processed image are projected onto the vertical axis:
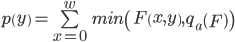
where
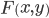 is the filtered image,
is the filtered image,
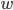 is the image width,
is the image width,
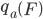 is the level quantile
is the level quantile
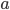 (this value is used for threshold cutting in order to suppress the influence of sharp noise boundaries, which usually arise due to the presence of static text such as “valid thru”, etc., applied in paint).
(this value is used for threshold cutting in order to suppress the influence of sharp noise boundaries, which usually arise due to the presence of static text such as “valid thru”, etc., applied in paint).
Based on the resulting projection,
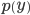 it is now possible to find the most probable position of the lines, assuming the absence of horizontal boundaries in the line spacing. To do this, we minimize the sum of the projection over all possible periods
it is now possible to find the most probable position of the lines, assuming the absence of horizontal boundaries in the line spacing. To do this, we minimize the sum of the projection over all possible periods
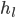 and initial phases
and initial phases
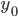 from a predetermined interval:
from a predetermined interval:
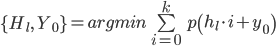
Since local minima
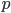 are usually quite pronounced at the outer boundaries of the text, the optimal value
are usually quite pronounced at the outer boundaries of the text, the optimal value
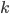 is four (implying that there are 3 lines on the card, and therefore 4 local minima). As a result, we will find the parameters
is four (implying that there are 3 lines on the card, and therefore 4 local minima). As a result, we will find the parameters
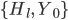 that define the centers of line spacing, as well as the outer boundaries of the text (see Figure 3).
that define the centers of line spacing, as well as the outer boundaries of the text (see Figure 3).
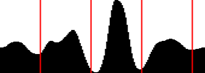
Figure 3. View of the projection and optimal cuts highlighting the areas of three lines on it.
Now the date search area can be significantly reduced, while simultaneously taking into account the original shape of the area and the position of the lines found in this image. For such an intersection, a set of possible positions of substrings is generated, with which we will work further.
Each of the candidate substrings is segmented into characters, given that all characters in such maps are monospaced. This allows you to use a dynamic programming algorithm to find intercharacter cuts without character recognition (all you need to know is the allowable interval for the character width). Here we present the main ideas of the algorithm.
After character segmentation, it’s time for recognition using an artificial neural network (ANN). Unfortunately, any detailed description of this process is beyond the scope of this article. Let's just note a couple of facts:
Thus, for each character image we will receive an array containing pseudo-probabilistic estimates of the location of the corresponding alphabet character in this image. It would seem that the correct answer is to construct a string from the best options (with the highest pseudo-probability value). However, the ANN sometimes makes mistakes. Some ANN errors can be corrected using post-processing due to existing restrictions on expected date values (for example, there is no 13th month). For this, the so-called “roulette” algorithm is used, which iteratively lists all possible options for “reading a line” in descending order of the total pseudo-probability. The first option that satisfies the existing restrictions is considered the answer.
Of course, in addition to the described “elementary” post-process, our system also uses additional context-sensitive methods, the description of which is not included in this article.
Recognizing credit card data is both a highly relevant and very interesting task from an algorithmic point of view. A well-implemented plastic card recognition program can eliminate the need for a person to enter most of the data manually when making online payments and payments in mobile applications. From a recognition point of view, a bank card is a complex document of a standard size (85.6 × 53.98 mm), made on a standard form and containing a certain set of fields (both mandatory and optional): card number, cardholder name, date issue, expiration date, account number, CVV2 code or its equivalent. Some of the fields are on the front side, the other part is on the back. And despite the fact that to complete a payment transaction you only need to specify the card number, almost all payment systems (as authentication) additionally require you to indicate the name of the card holder, expiration date and CVV2 code. Let's focus further on the task of recognizing information fields on the front side of a card (objectively, it is many times more difficult).
So, to make an online payment, in most cases you need to recognize the card number, the holder’s name and the card’s expiration date in the image.
The first step is to find the coordinates of the corners of the card. Since we know the geometric characteristics of the card (all cards are made strictly in accordance with the ISO 781 standard), to determine the quadrilateral of the card we will use the algorithm for searching and enumerating straight lines.
Given a known quadrilateral, it is not difficult to calculate and apply a projective transformation to the image, bringing the map image to an orthogonal form with a fixed resolution. We will assume that such a corrected image comes as input to subsequent stages - orientation and recognition of specific information fields.
From an architectural point of view, the recognition of the three target fields consists of the same parts:
- Pre-filtering of the image (in order to suppress the background of the card, which can be surprisingly varied).
- Search for a zone (line) of the target information field.
- Segmentation of the found string into “character boxes”.
- Recognition of found “character boxes” using an artificial neural network (ANN).
- Application of post-processing (using the Luhn algorithm to identify recognition errors, using dictionaries of first and last names, checking dates for validity, etc.).
Although the recognition steps are the same, the complexity varies greatly. The easiest way to recognize the card number (it’s not for nothing that there are a sufficient number of SDKs for various mobile platforms, including those posted in the public domain) due to a whole set of reasons:
- the card number contains only numbers;
- The number format is strictly defined for each type of payment card;
- the geometric position of the number does not vary much, regardless of the manufacturer;
- There is a Luhn algorithm that allows you to check the correctness of license plate recognition.
The situation is more complicated with the two remaining fields: expiration date and cardholder name. In this article, we will take a closer look at the procedure for recognizing the card’s expiration date (name recognition is performed in a similar way).
Expiration date recognition algorithm
Let's assume that the map image has already been corrected (as mentioned above). The result of the algorithm should be 4 decimal digits: two for the month and year of the expiration date. The algorithm is considered to have given the correct answer if the resulting 4 digits match those shown on the card. The character separating them is not taken into account and can be anything. Refusal to recognize is interpreted as an incorrect answer.The first step is to localize the field on the card (unlike the number, the location of this field is not standardized). Using the “brute force method” over the entire map area is not very promising, since the corresponding text fragment is very short (most often 5 characters), syntactic redundancy is low, and the probability of a false detection on an arbitrary text fragment or even a colorful area of the background is unacceptably high. Therefore, we’ll use a trick: we’ll look not for the date itself, but for some information zone located under the card number and having a stable geometric structure.
Figure 1. Examples of the required three-line information zone
The zone in question is divided into three lines, one of which is often empty. It is important that the location of the date line within this zone is well defined. This paradoxical phrase means the following: in the case when there are two non-blank lines in a zone, their line spacing either coincides with the line spacing of three-line zones, or is approximately equal to the sum of double the spacing and line height.
Finding a zone and dividing it into 3 lines is complicated by the presence of a background on the map, which, as we have already said, is varied. To solve this problem, a combination of filters is applied to the card image, the purpose of which is to highlight the vertical boundaries of the letters and suppress the remaining details of the image. The sequence of filters is as follows:
- Graying the image by averaging the values of the color channels using the formula
, see Figure 2b.
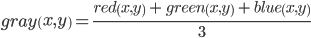
- Calculation of the image of vertical boundaries using the formula
, see Figure 2c.
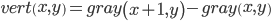
- Filtering small vertical boundaries using mathematical morphology (specifically by applying erosion with a rectangular size window
), see Figure 2d.
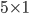
Figure 2. Pre-filtering of a credit card image: a) original image, b) grayscale image c) vertical edges image, d) filtered vertical edges image
In our implementation, to save time, morphological operations are implemented using van Herk algorithm. It allows you to calculate morphological operations with a rectangular primitive in a time that does not depend on the size of the primitive, which allows you to use complex large-area morphological filters in document recognition tasks in real time.
After filtering, the pixel intensities of the processed image are projected onto the vertical axis:
where
Based on the resulting projection,
Since local minima
Figure 3. View of the projection and optimal cuts highlighting the areas of three lines on it.
Now the date search area can be significantly reduced, while simultaneously taking into account the original shape of the area and the position of the lines found in this image. For such an intersection, a set of possible positions of substrings is generated, with which we will work further.
Each of the candidate substrings is segmented into characters, given that all characters in such maps are monospaced. This allows you to use a dynamic programming algorithm to find intercharacter cuts without character recognition (all you need to know is the allowable interval for the character width). Here we present the main ideas of the algorithm.
- Let y be a filtered image of the vertical boundaries of a string containing a date. Let's construct a projection of this image onto the horizontal axis. The resulting projection will contain local maxima in places of vertical boundaries (that is, in the zone of letters) and minima between letters. Let
be the expected period and let
be the maximum deviation of the period value.

- We will move from left to right along the constructed projection. Let's create an additional accumulator array, where each element will store the accumulated fine. At each step
we will consider a section of battery
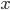 . Let us write down as the current value of the penalty the sum of the projection value at the point
. Let us write down as the current value of the penalty the sum of the projection value at the point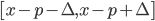 and the minimum value of the penalty from the segment under consideration. Additionally, we save the index of the previous step that delivers the specified minimum.
and the minimum value of the penalty from the segment under consideration. Additionally, we save the index of the previous step that delivers the specified minimum.
- Having gone through the entire projection in the described manner, we can analyze the penalty accumulator array and, thanks to saving the indices of the previous steps, restore all the cuts.
After character segmentation, it’s time for recognition using an artificial neural network (ANN). Unfortunately, any detailed description of this process is beyond the scope of this article. Let's just note a couple of facts:
- Convolutional neural networks trained using the cuda-convnet tool are used for recognition
- The alphabet of the trained network contains numbers, punctuation marks, a space and a non-character (“garbage”) sign.
Thus, for each character image we will receive an array containing pseudo-probabilistic estimates of the location of the corresponding alphabet character in this image. It would seem that the correct answer is to construct a string from the best options (with the highest pseudo-probability value). However, the ANN sometimes makes mistakes. Some ANN errors can be corrected using post-processing due to existing restrictions on expected date values (for example, there is no 13th month). For this, the so-called “roulette” algorithm is used, which iteratively lists all possible options for “reading a line” in descending order of the total pseudo-probability. The first option that satisfies the existing restrictions is considered the answer.
Of course, in addition to the described “elementary” post-process, our system also uses additional context-sensitive methods, the description of which is not included in this article.
Results of work
In order to evaluate the quality of our SDK, we collected a database of images of cards of various payment systems issued by different banks in the amount of 750 images (the number of unique cards is 60 pieces). Based on the collected material, the following results were obtained:- License plate recognition quality - 99%
- Date recognition quality - 99%
- Cardholder name recognition quality - 90%
- The total card recognition time on iPhone 4S is 0.6 seconds.
List of useful sources
- Van Herk M. A fast algorithm for local minimum and maximum filters on rectangular and octogonal kernels // Pattern Recognition Letters, 1992, V. 13, No. 7, pp. 517–521.