
Teacher
Professional
- Messages
- 2,669
- Reaction score
- 818
- Points
- 113
This article is a description of an experiment to create a system for detecting fraudulent payments on bank cards.
In the first part of the article, I will tell you why the issue of fraudulent payments (fraud) is so acute for all participants in the electronic payment market - from online stores to banks - and what are the main difficulties, because of which the cost of developing such systems is sometimes too high for many ecommerce market participants.
The second part will describe the technical and non-technical requirements that apply to such systems, and how I'm going to reduce the cost of developing and owning an antifraud system by an order of magnitude (s).
In the third part will consider the software architecture of the service, its modular structure and key implementation details.
In the fourth part of the article, we will discuss in detail the most technically complex and most intelligent part of the system - the analytical system for recognizing fraudulent payments.
Get Started!
The rapid growth in the number of transactions with plastic cards made via the Internet poses more and more challenges to the developers of online payment acceptance systems associated with the growth of the scale of such systems and the complication of approaches to ensuring their reliability and security.
The number of fraudulent transactions and the variety of types of fraud are also growing rapidly. Russia, along with England, France, Germany, Spain, is in the top 5 European countries in terms of the annual volume of fraudulent transactions with bank cards. The total losses from card fraud in 2020 in Europe exceeded 1 billion euros. Russia accounts for 110 million euros, of which 2.4 million euros are fraudulent payments on the Internet.
The complete chain of participants in an online payment when buying a product / service via the Internet generally looks like this:
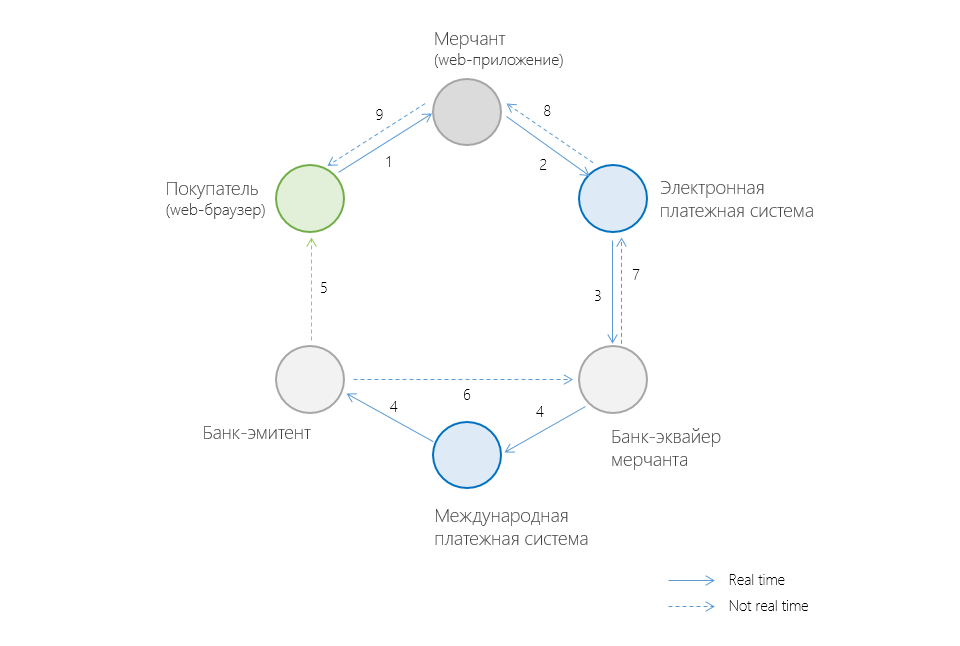
Online Payment Flow
Who is who?
Problem
The problem of fraudulent transactions (fraud affects all participants in the chain: from customers to the bank that issued the card to the client (the issuing bank). For all participants with the exception of cardholders, fraudulent transactions involve both significant financial costs and reputational risks. For the e-commerce industry as a whole, fraud also has tangible negative consequences - both lost profits and mistrust on the part of Internet users, which, in turn, hinders the wider spread of electronic payments.
Thus, the presence of a fraudulent payment recognition system (antifraud-system) for any serious participant in the online payment (again, except for the buyer) - a market necessity. At the same time, a good anti-fraud system often means long, expensive and complications.
Difficulties of the solution
Financial difficulties: development cost vs fraud penalties
And if for a bank the costs of antifraud systems are, on a business scale, a perfectly acceptable amount; for the payment system - an integral part of the business process; then merchants often do not have the financial ability and / or understanding of how to create and maintain such systems.
But the merchant cannot ignore the fraud: the money for fraudulent payments will simply not go to the merchant in the best case (even if the service has already been provided), in the worst case, the merchant will also be fined. The amount of the fine, in general, starts at $ 10 and grows in proportion to the volume of fraudulent transactions. In addition, with a large amount of fraud, MPS (Visa, MasterCard) may impose (I'm not afraid of this word) sanctions on the merchant.
An effective way to reduce costs on the side of the merchant can be the introduction of additional complexities checks for the client and delegating part / all of the responsibilities of checking for fraud to another participant. The most common method is 3-D Secure (delegation of the responsibility for verification to the issuing bank).
3-D Secure
But it should be borne in mind that the addition of such steps, which require additional actions from the user, often lead to a dramatic decrease in the number of successfully completed transactions (@Gremnix announced the figure for a decrease in the number of successful payments of 20-25% when 3-D Secure is enabled for Russia).
Legal difficulties
In the process of developing an anti-fraud system, you will inevitably have to deal with such a responsible area as the protection of customer and payment data, as well as with the formal part of this issue - certification for one of the PCI DSS levels.
About PCI PSS
When developing an anti-fraud system, it is also necessary to take into account some legal restrictions on the storage / exchange of payment and personal data of the client. In Russia, it is "On Personal Data". We will touch upon the provisions of this law in more detail later when considering the software architecture of the service.
Technical Difficulties
The anti-fraud system is a business-critical system, because its downtime will either lead to a halt in the business process, or, in case of incorrect operation of the system, to an increase in the risks of financial losses for the company.
Hence the increased requirements for operational reliability, data storage security, fault tolerance, and scalability of the system.
In the team developing the anti-fraud system, the following roles and areas of responsibility of these roles can be distinguished:
Merchant advantages
In the entire chain of online payment, the merchant is in one of the most difficult situations: the merchant, unlike the buyer, is responsible for fraud with its own funds, and at the same time, unlike the bank, it often does not have sufficient resources to effectively counter fraud.
But the merchant also has an advantage - unique information about the buyer of the product / service, which is often not available to other participants in the online payment (for example, the issuing bank or the IPS). So ECN-sites most likely have the real name of the payer; online stores offering delivery services are likely to know the real country, city of residence of the payer, etc.
The name, surname of the account holder, the lifetime of the account, the number of previously made successful payments through the merchant's website, information about the host from which the http request came, information about the browser - this is just a short list of the information that is often available to the merchant and which is capable of significantly improve the efficiency of searching for fraudulent transactions.
Conclusion To be continued
We have covered the main aspects of the problem of fraudulent payments. It is obvious that insufficient attention to fraudulent payments leads to significant financial costs . At the same time, the development of a full-fledged anti-fraud system requires financial costs both for infrastructure and payment for the work of a team of specialists with rather rare competencies .
In the following parts of the article, an experiment will be carried out, the goal of which will be to create a distributed, highly scalable, fault-tolerant system for detecting fraudulent payments.
The antifraud system will be available as a web service and it will be possible to connect to the service of third-party merchants. The financial goal will be to make the development of the service an order of magnitude (s) cheaper through the use of a number of approaches leading to a significant reduction in the initial financial costs of equipment and software, a reduction in the number of specialists and spent man-hours.
The details of the experiment, a description of the software architecture of the service and a detailed analysis of the most critical modules will be described in the following parts of the article.
Antifraud. Functional and non-functional requirements (part 2)
Another circumstance that complicates the development of such systems is that the antifraud-system is a business-critical system and its downtime will either lead to stopping the business process (receiving payment), or if the system does not work correctly, it will increase the risks of financial and reputational losses for company (online store, bank).
Therefore, the practices and approaches listed in the article are applicable not only on the side of the merchant, but on the side of other participants in Internet acquiring - aggregators, payment systems, banks. Moreover, the approaches listed in the article are often closed from the community of best practices in the respective organizations.
This part will describe the requirements for the antifraud system, whose impact on the software architecture is significant.
Non-functional requirements
Quality attributes
About the choice of quality attributes.
Quality attributes:
Legal restrictions
Legal restrictions are one of the important factors that determine the software architecture of an anti-fraud system.
So, according to the PCI DSS standard, you cannot store the full card number (PAN) or security code (CVV). It is allowed to store the first six and last four digits of the card. Also, nothing prohibits the generation of an internal unique identifier for customer cards. The name of the holder and the expiration date of the card are allowed to be transmitted only through secure channels.
About storing the PAN number
In addition to the requirements of the PCI DSS standard, it is necessary to comply with the provisions of the Law on Personal Data.
Discussion of the entire variety of technical and bureaucratic procedures (with the ensuing legal subtleties) required simply for storing, processing the last name, first name of the client will most likely take 10 sheets of instructions and 1.5 months of work to implement these instructions (just a joke, but partly). So the best way is do not create unnecessary work for yourself comply with the provisions - do not fall under its effect.
In the designed anti-fraud system, all program modules will work with depersonalized data.
Summing up, the restrictions that are of a legal nature, add the following requirements to the system:
Functional requirements
API requirement
First, let's consider the requirements for the system from the point of view of the outside world, i.e. software clients (merchants). Software clients interact with the anti-fraud system in accordance with the following API requirements:
Functional:
Non-functional:
Business Requirements
From the point of view of the internal logic of the anti-fraud system, we will single out only one essential business requirement: to predict whether the transaction will be successful based on the payment data.
In the process of implementing this requirement, we will try to prove that the payment will not work. Let's consider the main reasons for refusal to conduct a transaction: the payment data is formed incorrectly or the transaction is fraudulent. Below we will analyze the methods of checking each of the listed reasons.
Checking the correctness of the payment data entered
Do not expect the merchant to properly verify your payment details. Regardless of whether it was a user input error or malicious actions, identifying errors in payment details early will help save both CPU cycles and prevent noise in the trained model (more on this later).
It is necessary to check whether the cardholder's name contains at least 2 letters (dashes and numbers in the name are acceptable), whether the card is valid (the card has an expiration date), whether the card number passes the Luna algorithm check.
Luna's algorithm
Checking if the transaction is fraudulent
There are a large number of heuristics to identify a sign that a payment is fraudulent. Some companies boast a figure under 200 heuristics. Although I immediately suspect that some of these heuristics are either not supported by anything, or are the result of some other heuristic, or it is a crutch at all that allows better fitting the result to the training set and does not give any effect on real data. A large number of heuristics gives only: an overstrained model, incorrect recognition of whether a transaction is fraudulent, and a decrease in application performance.
Therefore, I will list only the main and, in general, the most effective heuristics:
Often the main approach is to naively assign a fixed value to one of the filters and then process these conditions in type constructs (this is pseudocode, not 1C):
I don't even want to start listing the disadvantages of this approach and the final cost of such a code, which will consist of losses from false positives for rejecting "decent" payments and skipping fraud with a slight change in strategy by scammers.
Therefore, the only correct solution would be to develop a system in which heuristic filters are capable of self-learning both on the accumulated history of payments and on new payments. Here, we will have several machine learning algorithms for our choice: logistic regression, support vector machines, neural networks.
Global Filters
Global filters I call lists, in the presence of a payer in which, it is pointless to carry out all other checks - the validity of payment data, check for fraud. These lists include blacklists of bank cards, IP, countries, merchants.
Global filters can be both static and dynamic, and can be associated with both business rules (the merchant does not accept payments from the Arctic), and with the detection of anomalous activity (IP address).
Conclusion of the 2nd part
In the first two parts, we looked at the main aspects of a predominantly non-technical nature that need to be considered when designing and developing a system for recognizing fraudulent payments.
We are going to create a fault-tolerant, highly scalable, reliable antifraud service that will be exposed “outside” to software clients via the REST API (https), and “inside” will contain logic based on machine learning methods. To add even more intrigue, I will say that the service will run on one of the public cloud platforms.
In the next part, we finally let's get down to business Let's consider the software architecture of an antifraud service, its modular structure and the key details of the implementation of such a service.
Antifraud. Service architecture (part 3)
In the last part, we focused on the functional and non-functional requirements for an anti-fraud service. In this part of the article, we will consider the software architecture of the service, its modular structure and the key details of the implementation of such a service.
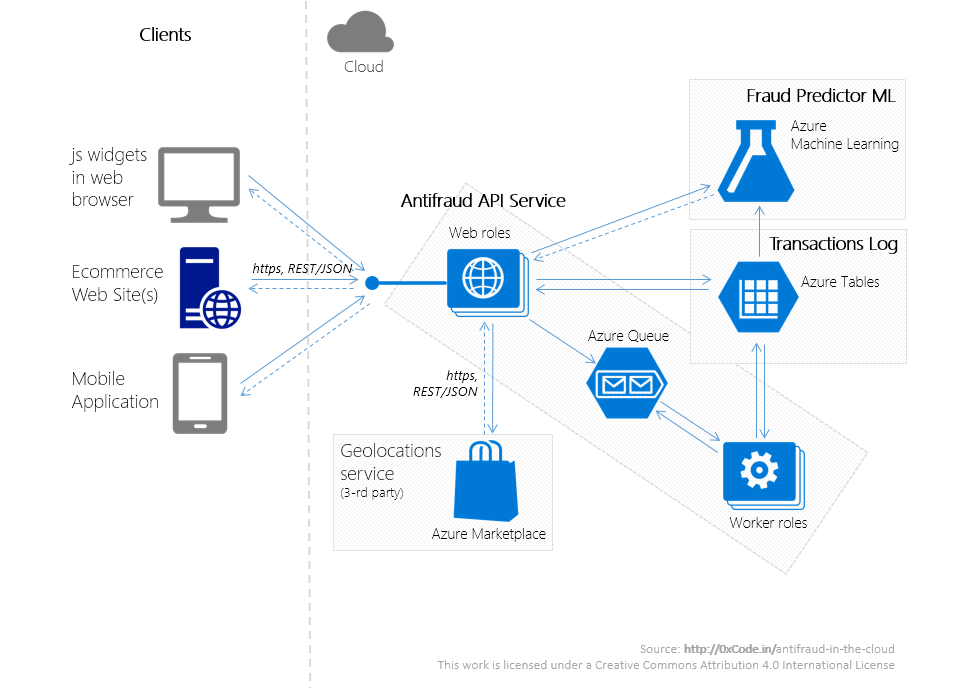
Antifraud in azure
Infrastructure
The service consists of several applications running on Microsoft Azure. Placement using a cloud platform instead of on-premise placement will not only allow developing a service at low time costs that meets all the requirements listed in the second part in the section "Non-functional requirements -> Quality attributes", but will also significantly reduce the initial financial costs of hardware and software. security.
Antifraud service consists of the following systems:
A schematic diagram of the interaction of these systems is illustrated above.
Architectural patterns used
The infrastructure, along with the subject area and legislation, potentially carries a large number of constraints that must be taken into account at the architectural level. And if we have already discussed domain and legal restrictions in the previous parts of the article, then we will discuss the advantages and limitations associated with choosing a cloud platform Microsoft Azure below.
Azure services used by the anti-fraud system - Cloud service for web / worker roles, Azure Table, Azure Queue, Azure ML, etc. - in addition to almost zero initial financial costs for infrastructure, they provide the following benefits out of the box:
As bonuses, I consider:
But it was possible to take advantage of all these advantages only thanks to the "sharpening" of the architecture of the antifraud service for the cloud, as follows:
In addition, the anti-fraud service is a near real-time system, therefore, when implementing an anti-fraud service:
It is also necessary to keep in mind that all cloud services have limitations:
Interaction between service components
For a merchant, a service is a REST service that can be interacted with via the https protocol - Antifraud API Service. Antifraud API Service runs in a cluster consisting of several stateless web roles (a web role in Azure is an application layer that acts as a web application).
The following sequence diagram describes the possible interactions of the merchant with all subsystems of the anti-fraud service.

Antifraud sequence diagram
The request from the merchant goes to the Controller (in terms of MVC) (Step 1). Then the resulting Model (in terms of MVC) goes through:
In step 2, the domain object is transformed into a DTO object, which:
To improve the quality of the prediction algorithm, clients have access to the API for specifying the results of the transaction. So, if the actual result of the payment was different from the value returned by our anti-fraud service, the merchant can report this by sending a request to clarify the results of transactions (step 9). Such requests:
Transaction storage
Both information about transactions and additional information on them (mainly statistics) are stored in the transaction log - long-term storage based on the Azure Table (a service that is a fault-tolerant NoSQL storage (key-value)).
The log transaction consists of 2 tables:
We will touch upon the issue of training the fraudulent payment detection model in more detail in the next concluding part.
Conclusion of the 3rd part
In this part, we discussed the architecture of the antifraud service, highlighted the functional parts in it - Antifraud API Service, Fraud Predictor ML, Transactions Log, identified their areas of responsibility, as well as ways of interaction with each other.
With the right architecture approach, deploying an anti-fraud service in the Microsoft Azure cloud will significantly reduce the initial financial costs of the infrastructure, as well as reduce the time spent on issues related to system scalability, reliable data storage and high availability of services.
In the next final part, we will continue to create an anti-fraud service that is an order of magnitude cheaper in terms of development and ownership costs than its counterparts -we will develop the Fraud Predictor ML service, which is based on the Azure Machine Learning service and is the analytical core of the anti-fraud service.
Helpful Sources
Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications , MSDN.
Antifraud (part 4): an analytical system for detecting fraudulent payments
In the final fourth part of the article, we will discuss in detail the most technically complex part of the antifraud service - an analytical system for recognizing fraudulent payments by bank cards .
Identification of various types of fraud is a typical briefcase to tasks supervised learning (supervised learning), so the analytical part of the antifraud service, in accordance with industry best practices, will be built with the use of machine learning algorithms.
For our task, we will use Azure Machine Learning, a cloud service for performing predictive analytics tasks. To understand the article, you will need a basic knowledge of machine learning and Introducing the Azure Machine Learning service.
What has already been done? (for those who have not read the previous 3 parts, but are interested)
Purpose
In this part I will describe a project, in the first step of which we will train four models using logistic regression, perceptron, support vector machine, and decision tree. From the trained models, we will choose the one that gives more accuracy on the test sample and publish it as a REST / JSON service. Next, for the received service, we will write a software client and carry out load testing on the REST service.
Model creation
Let's create a new experiment in Azure ML Studio. In the final form, it will look as shown in the illustration below. Let's map each element of the experiment to a sequence step that the average data scientist goes through while training the model.
[IM alt="Azure ML experiment"]https://habrastorage.org/getpro/hab...80/92bae8080fd3b45f9c305204adf9ea92.png[/IMG]
Azure ML experiment
Let's consider each of the stages of creating a model for recognizing fraudulent payments, taking into account the technical details described in the last 3rd part of the article.
Hypothesis
The basic concepts and assumptions useful for creating the model were discussed in the first 2 parts of this article. I will not repeat myself, I just note that creating a good hypothesis is an iterative process of trial and error, the foundation for which is knowledge both in the subject area under study and in the field of Data Science.
Retrieving data
The data set for the fraudulent payment recognition model will be the transaction log, which consists of 2 tables in the NoSQL storage (Azure Table): the fact tables for transactions TransactionsInfo and tables with the previously calculated statistical metrics TransactionsStatistics.
At the stage of receiving data, let's load these 2 tables through the Reader control.
Data preparation and exploration
Let's make an Inner Join of the loaded tables by the TransactionId field. Using the Metadata Editor control, we indicate the data types (string, integer, timestamp), mark the column with answers (label) and columns with predictors (features), as well as the type of scale for these data: nominal, absolute.
Do not underestimate the importance of preparation for creating an adequate model: I will give a simple example with a payment currency, which is stored in the form of ISO codes (integer value). ISO codes - have a nominal (classification) scale. But it is hardly worth hoping that the system will automatically determine that a non-integer value with an absolute scale is stored in the "Currency" column (that is, such operations as + or> are possible). Because this is a very non-obvious rule, the knowledge of which the system does not possess.
The dataset may contain missing values. In our case, it is not always possible to determine the country or the IP-address of the payer; such fields may contain empty values. After checking the existing dataset, replace the empty country values with "undefined" using the Clean Missing Data control... Using the same control, we will delete the lines where the cardholder, payment amount or currency field does not contain values, as lines containing deliberately incorrect data, that is, introducing noise into the model.
At the next stage, we will get rid of the fields that are not used in the model: address (we are only interested in whether the payer's country coincided with the country where the request came from), the hash of the cardholder's name (since it has no effect on the payment result), RowId and PartitionId (service data that came to us from the Azure Table). Finally, using the Normalize Data control, we perform ZScore-normalization of data containing large numeric values, such as the payment amount (TransactionAmount column).
Data sharing
Let's divide the resulting dataset into training and test sets. Let's choose the optimal ratio of data in the training sample and in the test one. For our purposes, using the Split control , we will "send" 70% of all available data to the training set, additionally enabling random mixing of the data (the Randomized split flag) when dividing into subsets of the data. Mixing data during division will allow avoiding "skews" in the training set associated with large leaks of plastic card numbers (and, as a consequence, anomalous activity of fraud robots during this period).
Building and evaluating the model
Let's initialize several classification algorithms and compare which one gives the best result (accuracy) on the test sample. It is important to note that it is not at all a fact that the same performance will be achieved on real data as on test data. Therefore, it is very important to understand that the model did not take into account why one of the algorithms gives a significantly worse or better result, correct the errors and start the learning algorithm again. This process ends when the researcher receives a model that is acceptable in terms of accuracy.
Azure ML allows us to connect an unlimited number of machine learning algorithms in one experiment. This makes it possible at the research stage to compare the performance of several algorithms in order to identify the one that best suits our task. In our experiment, we use several two-class classification algorithms: Two-Class Logistic Regression, Two-Class Boosted Decision Tree, Two-Class Support Vector Machine, Two- the Neural the Network Class (ANN).
Another opportunity to get the best model performance is to tune the machine learning algorithm using a large number of parameters available to tune the algorithm. So for the Two-Class Boosted Decision Tree algorithm, the number of trees to be built was specified, as well as the minimum / maximum number of leaves on each tree; for the Two-Class Neural Network algorithm, the number of hidden nodes, training iterations, and initial weights.
In the final step, let's look at the output of the Evaluate Model control (the Visualize command from the context menu of the element) for each of the algorithms.

Antifraud evaluate model
The Evaluate Model control contains a confusion matrix, calculated indicators of the accuracy of the algorithmAccuracy, Precision, Recall, F1 Score , AUC, ROC and Precision / Recall charts. To put it simply, we will choose an algorithm whose Accuracy, Precision, AUC values are closer to 1, the ROC graph is more concave towards the Y axis for both the training and test samples.
In addition, it is impassable to look at the change in AUC depending on the Threshold value being set. In the case of fraud, this is important, since the cost of unrecognized fraudulent payments (False Positive) is much higher than the cost of payments mistaken for fraud (False Negative).
In such cases it is necessary to select a Threshold value other than the default 0.5.
When choosing the most appropriate algorithm for obtaining the optimal model for recognizing fraud, in addition to the Threshold level, we will also take into account the fact that the decision-making logic for some algorithms (for example, a decision tree) can be reproduced, but for some it is not (perceptron). The presence of such a possibility can be critical if it is important to know why the system made a specific decision on a certain precedent.
The best accuracy was shown by the algorithm of a two-class neural network - Two-Class Neural Network (accuracy indicators are shown in the illustration above), followed by an algorithm based on decision trees - Two-Class Boosted Decision Tree.
Publishing a Model as a Web Service
After the model has been obtained that works with the required accuracy, we publish our experiment as a web service. Publishing operation takes place by clicking the Publish Web Service button in Azure ML Studio. The process of creating a web service from an experiment is trivial and I will skip its description.
As a result, Azure ML will deploy a scalable, fault-tolerant (SLA 99.95%) web service. After the service is published, the API help documentation page will become available, which, in addition to a general description of the service, a description of the formats of expected input and output messages, also contains examples of calling a service in C #, Python and R.
The principle of calling a service by a software client can be depicted as follows.

Azure ML services
Connect to Azure ML web service
Let's take the C # example from the API help and change it slightly to invoke the Azure ML web service.
Listing 1. Calling the Azure ML web service
We get the following request / response:
Listing 2.1. Azure ML Web Service Request
Listing 2.2. Azure ML web service response
Stress Testing
For load testing purposes, we will use the IaaS capabilities of Azure - we will raise a virtual machine (Instance A8: 8x CPU, 56Gb RAM, 40Gbit / s InfiniBand, Windows Server 2012 R2, $ 2.45 / hr) in the same region (US Central South) where our Azure ML web service. Let's run a task for ~ 20K requests on the VM and see the results.
Listing 3. Service client code and tasks
InvokeParallel () call:
Best response time: 421.683 ms
Worst time: 1355.516 ms
Average time: 652.935 ms
Successful requests: 20061
Failures: 956
InvokeAsync () call:
Best response time: 478.102 ms
Worst time: 1344.348 ms
Average time: 605.911 ms
Number of successful requests: 21017
Number of rejections: 0
Limitations (potential)
At first glance, the bottleneck of the system being developed will be Azure ML. Therefore, it is extremely important to understand the limitations of Azure ML in general and Azure ML Web Services in particular. But on this issue, there is very little, both official documentation and the results obtained from the community.
So the question remains with the throttled policy of the endpoints of the Azure ML web service: it is not clear the maximum value of parallel requests to the Azure ML web service (the figure of 20 concurrent requests per endpoint has been empirically verified), as well as the maximum size of the received message (relevant for batch mode service operation).
Less relevant, but there is a question with the maximum size of the input data (Criteo Labs placed a dataset on 1 TB of data), the maximum number of predictors and use cases that can be sent to the input to the machine learning algorithm in Azure ML.
It is critically important to reduce the response time of the FraudPredictorML web service, as well as the time to retrain the model to minimum values, but so far there is no official recommendation on how this is possible (or even possible).
Recommendations to clients
The anti-fraud service does not restrict clients in any way both in the preliminary verification of payments and in the subsequent interpretation of the prediction results. Preliminary business process-specific checks, as well as the final decision on acceptance / rejection of a payment, are tasks that clearly fall outside the area of responsibility of the anti-fraud service.
Regardless of the client's role - an online store, a payment system or a bank - there are the following recommendations for clients:
Recommendations for commentators
Within the framework of this series of articles, we dealt with the problematics of the issue, the legal and technical side of the problem. This is a technical article, it does not pursue the goal of creating a business plan, comparing it with competitors' solutions, calculating the present value of the project. With all these questionsat RBK - not to me, not to this hub, and, there is a suspicion, not even to this site.
Conclusion
In this series, consisting of 4 articles, we conducted an experiment on the design and development of a highly scalable, fault-tolerant, reliable antifraud service operating in near real-time mode, with a REST / JSON API open to external software clients.
The use of machine learning algorithms (decision tree, neural networks) made it possible to create an analytical system capable of self-learning both on the accumulated history and on new payments. Thanks to the use of PaaS / IaaS services, it was possible to reduce the initial financial costs for infrastructure and software to almost zero. The developer has competencies in the subject area, data science, architecture of distributed systems helped to dramatically reduce the number of development team members.
As a result, in less than 60 man-hours and with minimal initial infrastructure costs (<$ 150, which were covered by MSDN subscription), the core of the anti-fraud system was created.
The resulting service, of course, still requires a thorough check (and subsequent correction) of the main modules, more fine-tuning of the work of the classifier (s), the development of a series of auxiliary subsystems, interest and (to be sure) investments. But despite the aforementioned shortcomings, the service is an order of magnitude (and more) more efficient than similar developments in the industry, both in terms of development costs and in terms of the cost of ownership.
In the first part of the article, I will tell you why the issue of fraudulent payments (fraud) is so acute for all participants in the electronic payment market - from online stores to banks - and what are the main difficulties, because of which the cost of developing such systems is sometimes too high for many ecommerce market participants.
The second part will describe the technical and non-technical requirements that apply to such systems, and how I'm going to reduce the cost of developing and owning an antifraud system by an order of magnitude (s).
In the third part will consider the software architecture of the service, its modular structure and key implementation details.
In the fourth part of the article, we will discuss in detail the most technically complex and most intelligent part of the system - the analytical system for recognizing fraudulent payments.
Get Started!
The rapid growth in the number of transactions with plastic cards made via the Internet poses more and more challenges to the developers of online payment acceptance systems associated with the growth of the scale of such systems and the complication of approaches to ensuring their reliability and security.
The number of fraudulent transactions and the variety of types of fraud are also growing rapidly. Russia, along with England, France, Germany, Spain, is in the top 5 European countries in terms of the annual volume of fraudulent transactions with bank cards. The total losses from card fraud in 2020 in Europe exceeded 1 billion euros. Russia accounts for 110 million euros, of which 2.4 million euros are fraudulent payments on the Internet.
The complete chain of participants in an online payment when buying a product / service via the Internet generally looks like this:
Online Payment Flow
Who is who?
Problem
The problem of fraudulent transactions (fraud affects all participants in the chain: from customers to the bank that issued the card to the client (the issuing bank). For all participants with the exception of cardholders, fraudulent transactions involve both significant financial costs and reputational risks. For the e-commerce industry as a whole, fraud also has tangible negative consequences - both lost profits and mistrust on the part of Internet users, which, in turn, hinders the wider spread of electronic payments.
Thus, the presence of a fraudulent payment recognition system (antifraud-system) for any serious participant in the online payment (again, except for the buyer) - a market necessity. At the same time, a good anti-fraud system often means long, expensive and complications.
Difficulties of the solution
Financial difficulties: development cost vs fraud penalties
And if for a bank the costs of antifraud systems are, on a business scale, a perfectly acceptable amount; for the payment system - an integral part of the business process; then merchants often do not have the financial ability and / or understanding of how to create and maintain such systems.
But the merchant cannot ignore the fraud: the money for fraudulent payments will simply not go to the merchant in the best case (even if the service has already been provided), in the worst case, the merchant will also be fined. The amount of the fine, in general, starts at $ 10 and grows in proportion to the volume of fraudulent transactions. In addition, with a large amount of fraud, MPS (Visa, MasterCard) may impose (I'm not afraid of this word) sanctions on the merchant.
An effective way to reduce costs on the side of the merchant can be the introduction of additional complexities checks for the client and delegating part / all of the responsibilities of checking for fraud to another participant. The most common method is 3-D Secure (delegation of the responsibility for verification to the issuing bank).
3-D Secure
But it should be borne in mind that the addition of such steps, which require additional actions from the user, often lead to a dramatic decrease in the number of successfully completed transactions (@Gremnix announced the figure for a decrease in the number of successful payments of 20-25% when 3-D Secure is enabled for Russia).
Legal difficulties
In the process of developing an anti-fraud system, you will inevitably have to deal with such a responsible area as the protection of customer and payment data, as well as with the formal part of this issue - certification for one of the PCI DSS levels.
About PCI PSS
When developing an anti-fraud system, it is also necessary to take into account some legal restrictions on the storage / exchange of payment and personal data of the client. In Russia, it is "On Personal Data". We will touch upon the provisions of this law in more detail later when considering the software architecture of the service.
Technical Difficulties
The anti-fraud system is a business-critical system, because its downtime will either lead to a halt in the business process, or, in case of incorrect operation of the system, to an increase in the risks of financial losses for the company.
Hence the increased requirements for operational reliability, data storage security, fault tolerance, and scalability of the system.
In the team developing the anti-fraud system, the following roles and areas of responsibility of these roles can be distinguished:
- an expert in the subject area: payment systems, banking systems, payment via the Internet, legal nuances of the operation of such systems;
- architect: designing a highly available, reliable (better distributed and scalable) application;
- developer: high-level programming language, asynchronous and multi-threaded programming, good mathematical background;
- data scientist: researcher, loves data and math
- project manager (where can I do without them): coordination of development.
Merchant advantages
In the entire chain of online payment, the merchant is in one of the most difficult situations: the merchant, unlike the buyer, is responsible for fraud with its own funds, and at the same time, unlike the bank, it often does not have sufficient resources to effectively counter fraud.
But the merchant also has an advantage - unique information about the buyer of the product / service, which is often not available to other participants in the online payment (for example, the issuing bank or the IPS). So ECN-sites most likely have the real name of the payer; online stores offering delivery services are likely to know the real country, city of residence of the payer, etc.
The name, surname of the account holder, the lifetime of the account, the number of previously made successful payments through the merchant's website, information about the host from which the http request came, information about the browser - this is just a short list of the information that is often available to the merchant and which is capable of significantly improve the efficiency of searching for fraudulent transactions.
We have covered the main aspects of the problem of fraudulent payments. It is obvious that insufficient attention to fraudulent payments leads to significant financial costs . At the same time, the development of a full-fledged anti-fraud system requires financial costs both for infrastructure and payment for the work of a team of specialists with rather rare competencies .
In the following parts of the article, an experiment will be carried out, the goal of which will be to create a distributed, highly scalable, fault-tolerant system for detecting fraudulent payments.
The antifraud system will be available as a web service and it will be possible to connect to the service of third-party merchants. The financial goal will be to make the development of the service an order of magnitude (s) cheaper through the use of a number of approaches leading to a significant reduction in the initial financial costs of equipment and software, a reduction in the number of specialists and spent man-hours.
The details of the experiment, a description of the software architecture of the service and a detailed analysis of the most critical modules will be described in the following parts of the article.
Antifraud. Functional and non-functional requirements (part 2)
- Payment systems,
- Systems analysis and design
Another circumstance that complicates the development of such systems is that the antifraud-system is a business-critical system and its downtime will either lead to stopping the business process (receiving payment), or if the system does not work correctly, it will increase the risks of financial and reputational losses for company (online store, bank).
Therefore, the practices and approaches listed in the article are applicable not only on the side of the merchant, but on the side of other participants in Internet acquiring - aggregators, payment systems, banks. Moreover, the approaches listed in the article are often closed from the community of best practices in the respective organizations.
This part will describe the requirements for the antifraud system, whose impact on the software architecture is significant.
Non-functional requirements
Quality attributes
About the choice of quality attributes.
Quality attributes:
- distribution;
- fault tolerance;
- high scalability;
- reliability.
Legal restrictions
Legal restrictions are one of the important factors that determine the software architecture of an anti-fraud system.
So, according to the PCI DSS standard, you cannot store the full card number (PAN) or security code (CVV). It is allowed to store the first six and last four digits of the card. Also, nothing prohibits the generation of an internal unique identifier for customer cards. The name of the holder and the expiration date of the card are allowed to be transmitted only through secure channels.
About storing the PAN number
In addition to the requirements of the PCI DSS standard, it is necessary to comply with the provisions of the Law on Personal Data.
Discussion of the entire variety of technical and bureaucratic procedures (with the ensuing legal subtleties) required simply for storing, processing the last name, first name of the client will most likely take 10 sheets of instructions and 1.5 months of work to implement these instructions (just a joke, but partly). So the best way is do not create unnecessary work for yourself comply with the provisions - do not fall under its effect.
In the designed anti-fraud system, all program modules will work with depersonalized data.
Summing up, the restrictions that are of a legal nature, add the following requirements to the system:
- do not store PAN and CVV cards in any form;
- store other payment data only in a protected form;
- transfer information between the merchant (software client) and the anti-fraud system only through secure communication channels ;
- work only with depersonalized data.
Functional requirements
API requirement
First, let's consider the requirements for the system from the point of view of the outside world, i.e. software clients (merchants). Software clients interact with the anti-fraud system in accordance with the following API requirements:
Functional:
- Provide the client with an API for sending payment data;
- Return the result of the prediction to the client if the payment is fraudulent;
- Provide the client with an API for adjusting the results of the payment.
Non-functional:
- Provide a publicly available client communication protocol;
- Conduct interaction with the client only through secure communication channels .
Business Requirements
From the point of view of the internal logic of the anti-fraud system, we will single out only one essential business requirement: to predict whether the transaction will be successful based on the payment data.
In the process of implementing this requirement, we will try to prove that the payment will not work. Let's consider the main reasons for refusal to conduct a transaction: the payment data is formed incorrectly or the transaction is fraudulent. Below we will analyze the methods of checking each of the listed reasons.
Checking the correctness of the payment data entered
Do not expect the merchant to properly verify your payment details. Regardless of whether it was a user input error or malicious actions, identifying errors in payment details early will help save both CPU cycles and prevent noise in the trained model (more on this later).
It is necessary to check whether the cardholder's name contains at least 2 letters (dashes and numbers in the name are acceptable), whether the card is valid (the card has an expiration date), whether the card number passes the Luna algorithm check.
Luna's algorithm
Checking if the transaction is fraudulent
There are a large number of heuristics to identify a sign that a payment is fraudulent. Some companies boast a figure under 200 heuristics. Although I immediately suspect that some of these heuristics are either not supported by anything, or are the result of some other heuristic, or it is a crutch at all that allows better fitting the result to the training set and does not give any effect on real data. A large number of heuristics gives only: an overstrained model, incorrect recognition of whether a transaction is fraudulent, and a decrease in application performance.
Therefore, I will list only the main and, in general, the most effective heuristics:
- one card - many IPs, and the opposite case: one IP - many cards;
- one card - many purchases / failed attempts;
- one client - many cards (especially those issued by various banks);
- one client - many indexes, emails;
- the client's name does not match the name of the account owner on the merchant's website (if any);
- the client's country does not match the country of the owner of the account on the merchant's website (if any);
- payment takes place overnight (according to the client's local time).
Often the main approach is to naively assign a fixed value to one of the filters and then process these conditions in type constructs (this is pseudocode, not 1C):
Code:
if (number of_cards_from_one_ip> 4) {
payment_status = declined;
return;
}
else {
if (number of purchases_from_card_for_1_hour> 5) {
payment_status = declined;
return;
}
else {
// continuation magic ...
}
}
// making a payment ...I don't even want to start listing the disadvantages of this approach and the final cost of such a code, which will consist of losses from false positives for rejecting "decent" payments and skipping fraud with a slight change in strategy by scammers.
Therefore, the only correct solution would be to develop a system in which heuristic filters are capable of self-learning both on the accumulated history of payments and on new payments. Here, we will have several machine learning algorithms for our choice: logistic regression, support vector machines, neural networks.
Global Filters
Global filters I call lists, in the presence of a payer in which, it is pointless to carry out all other checks - the validity of payment data, check for fraud. These lists include blacklists of bank cards, IP, countries, merchants.
Global filters can be both static and dynamic, and can be associated with both business rules (the merchant does not accept payments from the Arctic), and with the detection of anomalous activity (IP address).
Conclusion of the 2nd part
In the first two parts, we looked at the main aspects of a predominantly non-technical nature that need to be considered when designing and developing a system for recognizing fraudulent payments.
We are going to create a fault-tolerant, highly scalable, reliable antifraud service that will be exposed “outside” to software clients via the REST API (https), and “inside” will contain logic based on machine learning methods. To add even more intrigue, I will say that the service will run on one of the public cloud platforms.
In the next part, we finally let's get down to business Let's consider the software architecture of an antifraud service, its modular structure and the key details of the implementation of such a service.
Antifraud. Service architecture (part 3)
- Payment systems,
- Analysis and design of systems,
- Microsoft Azure
In the last part, we focused on the functional and non-functional requirements for an anti-fraud service. In this part of the article, we will consider the software architecture of the service, its modular structure and the key details of the implementation of such a service.
Antifraud in azure
Infrastructure
The service consists of several applications running on Microsoft Azure. Placement using a cloud platform instead of on-premise placement will not only allow developing a service at low time costs that meets all the requirements listed in the second part in the section "Non-functional requirements -> Quality attributes", but will also significantly reduce the initial financial costs of hardware and software. security.
Antifraud service consists of the following systems:
- Antifraud API Service is a REST service that provides an API for interacting with the Fraud Predictor ML service.
- Fraud Predictor ML is a fraudulent payment detection service based on machine learning algorithms.
- Transactions Log - NoSQL store of information about transactions.
A schematic diagram of the interaction of these systems is illustrated above.
Architectural patterns used
The infrastructure, along with the subject area and legislation, potentially carries a large number of constraints that must be taken into account at the architectural level. And if we have already discussed domain and legal restrictions in the previous parts of the article, then we will discuss the advantages and limitations associated with choosing a cloud platform Microsoft Azure below.
Azure services used by the anti-fraud system - Cloud service for web / worker roles, Azure Table, Azure Queue, Azure ML, etc. - in addition to almost zero initial financial costs for infrastructure, they provide the following benefits out of the box:
- high availability: SLA not lower than 99.95%;
- storage reliability: data storage systems with high redundancy;
- storage security: ISO 27001/27002 certificates and others, including PCI DSS 3.0;
- fault tolerance: all worker nodes can be (recommended) run in multiple instances;
- scalability: it is possible to automatically scale the number of working nodes depending on the load, partitioning NoSQL storage tables based on Partition Key;
As bonuses, I consider:
- convenient application monitoring;
- deep integration with Visual Studio.
But it was possible to take advantage of all these advantages only thanks to the "sharpening" of the architecture of the antifraud service for the cloud, as follows:
- web / worker nodes are stateless ;
- horizontal partitioning for storing structured or semi-structured data (Shading Pattern [1]);
- network interactions occur only asynchronously and only with the use of retry policies (Retry Pattern [1]);
- for load balancing and guaranteed processing of tasks, message queues are used (the Queue-Based Load Leveling Pattern [1]).
In addition, the anti-fraud service is a near real-time system, therefore, when implementing an anti-fraud service:
- we use data parallel algorithms (the simplest and one of the most efficient MapReduce);
- we apply the Push'n'Forget approach for such places as storing a single record in the transaction log (one missing record out of 10K successful ones will not have a strong effect on the accuracy of the machine learning algorithm);
- we avoid blocking thetransaction log (any shared resources), which is achieved by adding the timestamp field to the information about the transaction;
- "Kill" (or at least do something with them) long queries.
It is also necessary to keep in mind that all cloud services have limitations:
- as a technical nature: the most frequent of them are the maximum number of requests per second, the maximum message size;
- and of a technological nature: the most serious of them is the supported protocols for interacting with PaaS services.
Interaction between service components
For a merchant, a service is a REST service that can be interacted with via the https protocol - Antifraud API Service. Antifraud API Service runs in a cluster consisting of several stateless web roles (a web role in Azure is an application layer that acts as a web application).
The following sequence diagram describes the possible interactions of the merchant with all subsystems of the anti-fraud service.
Antifraud sequence diagram
- Step 1. Sending a request with payment information.
- Step 2. Transformation of the Model (in terms of MVC).
- Step 3. Sending a request to the payment result prediction service.
- Step 4. Returning the result - whether the payment will be successful.
- Step 5. Saving data.
- Step 6. Returning the result to the client.
- Step 7, 8. Recalculation and updating of the training sample, retraining of the model.
- Step 9-12 (optional). The client initiates sending a request with information about the payment result (in the case when the prediction result differs from the actual payment result transmitted in the request).
The request from the merchant goes to the Controller (in terms of MVC) (Step 1). Then the resulting Model (in terms of MVC) goes through:
- transformation from a controller model to a domain object;
- a request to external geolocation services (Azure Marketplace), in order to find out the country by the payer's index and the country by the IP of the host from which the request for withdrawing funds from the card came;
- verification stage through global filters;
- the stage of checking the validity of payment data;
- preliminary analysis of the received transaction - we calculate heuristics for timeframes 5 seconds, 1 minute, 24 hours;
- hiding the buyer's personal data and payment data - the name of the cardholder, the name of the account owner on the merchant's website, the payer's address, phone number, email are hashed.
- we delete unnecessary data - for example, data on the expiration date of the card after step 4 will not be needed.
In step 2, the domain object is transformed into a DTO object, which:
- passed to the Fraud Predictor ML service (step 3);
- after receiving a response from Fraud Predictor ML (step 4), information about the transaction and its result is saved in the transaction log (step 5) (about it a little below);
- we return to the client a response about the predicted payment result (fraudulent or not).
To improve the quality of the prediction algorithm, clients have access to the API for specifying the results of the transaction. So, if the actual result of the payment was different from the value returned by our anti-fraud service, the merchant can report this by sending a request to clarify the results of transactions (step 9). Such requests:
- are in the format <transaction_id, transaction_result, last_update_time>;
- are processed by the Merchant API Service and, after validation, are placed in the Azure Queue (fault-tolerant queue service).
Transaction storage
Both information about transactions and additional information on them (mainly statistics) are stored in the transaction log - long-term storage based on the Azure Table (a service that is a fault-tolerant NoSQL storage (key-value)).
The log transaction consists of 2 tables:
- table with the facts about the transaction TransactionsInfo: transaction id (Row Key), id merchant, hash name card holder (if available), the amount and currency of payment, etc .;
- a table with the calculated statistical metrics TransactionsStatistics: how many times they paid from this card (several timeframes), from how many IP addresses, how the time interval was between payments, how long ago the buyer registered with the merchant, how many times made successful payments, etc.
We will touch upon the issue of training the fraudulent payment detection model in more detail in the next concluding part.
Conclusion of the 3rd part
In this part, we discussed the architecture of the antifraud service, highlighted the functional parts in it - Antifraud API Service, Fraud Predictor ML, Transactions Log, identified their areas of responsibility, as well as ways of interaction with each other.
With the right architecture approach, deploying an anti-fraud service in the Microsoft Azure cloud will significantly reduce the initial financial costs of the infrastructure, as well as reduce the time spent on issues related to system scalability, reliable data storage and high availability of services.
In the next final part, we will continue to create an anti-fraud service that is an order of magnitude cheaper in terms of development and ownership costs than its counterparts -we will develop the Fraud Predictor ML service, which is based on the Azure Machine Learning service and is the analytical core of the anti-fraud service.
Helpful Sources
Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications , MSDN.
Antifraud (part 4): an analytical system for detecting fraudulent payments
- Payment systems
- Data Mining
- Microsoft Azure
- Machine learning
In the final fourth part of the article, we will discuss in detail the most technically complex part of the antifraud service - an analytical system for recognizing fraudulent payments by bank cards .
Identification of various types of fraud is a typical briefcase to tasks supervised learning (supervised learning), so the analytical part of the antifraud service, in accordance with industry best practices, will be built with the use of machine learning algorithms.
For our task, we will use Azure Machine Learning, a cloud service for performing predictive analytics tasks. To understand the article, you will need a basic knowledge of machine learning and Introducing the Azure Machine Learning service.
What has already been done? (for those who have not read the previous 3 parts, but are interested)
Purpose
In this part I will describe a project, in the first step of which we will train four models using logistic regression, perceptron, support vector machine, and decision tree. From the trained models, we will choose the one that gives more accuracy on the test sample and publish it as a REST / JSON service. Next, for the received service, we will write a software client and carry out load testing on the REST service.
Model creation
Let's create a new experiment in Azure ML Studio. In the final form, it will look as shown in the illustration below. Let's map each element of the experiment to a sequence step that the average data scientist goes through while training the model.
[IM alt="Azure ML experiment"]https://habrastorage.org/getpro/hab...80/92bae8080fd3b45f9c305204adf9ea92.png[/IMG]
Azure ML experiment
Let's consider each of the stages of creating a model for recognizing fraudulent payments, taking into account the technical details described in the last 3rd part of the article.
Hypothesis
The basic concepts and assumptions useful for creating the model were discussed in the first 2 parts of this article. I will not repeat myself, I just note that creating a good hypothesis is an iterative process of trial and error, the foundation for which is knowledge both in the subject area under study and in the field of Data Science.
Retrieving data
The data set for the fraudulent payment recognition model will be the transaction log, which consists of 2 tables in the NoSQL storage (Azure Table): the fact tables for transactions TransactionsInfo and tables with the previously calculated statistical metrics TransactionsStatistics.
At the stage of receiving data, let's load these 2 tables through the Reader control.
Data preparation and exploration
Let's make an Inner Join of the loaded tables by the TransactionId field. Using the Metadata Editor control, we indicate the data types (string, integer, timestamp), mark the column with answers (label) and columns with predictors (features), as well as the type of scale for these data: nominal, absolute.
Do not underestimate the importance of preparation for creating an adequate model: I will give a simple example with a payment currency, which is stored in the form of ISO codes (integer value). ISO codes - have a nominal (classification) scale. But it is hardly worth hoping that the system will automatically determine that a non-integer value with an absolute scale is stored in the "Currency" column (that is, such operations as + or> are possible). Because this is a very non-obvious rule, the knowledge of which the system does not possess.
The dataset may contain missing values. In our case, it is not always possible to determine the country or the IP-address of the payer; such fields may contain empty values. After checking the existing dataset, replace the empty country values with "undefined" using the Clean Missing Data control... Using the same control, we will delete the lines where the cardholder, payment amount or currency field does not contain values, as lines containing deliberately incorrect data, that is, introducing noise into the model.
At the next stage, we will get rid of the fields that are not used in the model: address (we are only interested in whether the payer's country coincided with the country where the request came from), the hash of the cardholder's name (since it has no effect on the payment result), RowId and PartitionId (service data that came to us from the Azure Table). Finally, using the Normalize Data control, we perform ZScore-normalization of data containing large numeric values, such as the payment amount (TransactionAmount column).
Data sharing
Let's divide the resulting dataset into training and test sets. Let's choose the optimal ratio of data in the training sample and in the test one. For our purposes, using the Split control , we will "send" 70% of all available data to the training set, additionally enabling random mixing of the data (the Randomized split flag) when dividing into subsets of the data. Mixing data during division will allow avoiding "skews" in the training set associated with large leaks of plastic card numbers (and, as a consequence, anomalous activity of fraud robots during this period).
Building and evaluating the model
Let's initialize several classification algorithms and compare which one gives the best result (accuracy) on the test sample. It is important to note that it is not at all a fact that the same performance will be achieved on real data as on test data. Therefore, it is very important to understand that the model did not take into account why one of the algorithms gives a significantly worse or better result, correct the errors and start the learning algorithm again. This process ends when the researcher receives a model that is acceptable in terms of accuracy.
Azure ML allows us to connect an unlimited number of machine learning algorithms in one experiment. This makes it possible at the research stage to compare the performance of several algorithms in order to identify the one that best suits our task. In our experiment, we use several two-class classification algorithms: Two-Class Logistic Regression, Two-Class Boosted Decision Tree, Two-Class Support Vector Machine, Two- the Neural the Network Class (ANN).
Another opportunity to get the best model performance is to tune the machine learning algorithm using a large number of parameters available to tune the algorithm. So for the Two-Class Boosted Decision Tree algorithm, the number of trees to be built was specified, as well as the minimum / maximum number of leaves on each tree; for the Two-Class Neural Network algorithm, the number of hidden nodes, training iterations, and initial weights.
In the final step, let's look at the output of the Evaluate Model control (the Visualize command from the context menu of the element) for each of the algorithms.
Antifraud evaluate model
The Evaluate Model control contains a confusion matrix, calculated indicators of the accuracy of the algorithmAccuracy, Precision, Recall, F1 Score , AUC, ROC and Precision / Recall charts. To put it simply, we will choose an algorithm whose Accuracy, Precision, AUC values are closer to 1, the ROC graph is more concave towards the Y axis for both the training and test samples.
In addition, it is impassable to look at the change in AUC depending on the Threshold value being set. In the case of fraud, this is important, since the cost of unrecognized fraudulent payments (False Positive) is much higher than the cost of payments mistaken for fraud (False Negative).
In such cases it is necessary to select a Threshold value other than the default 0.5.
When choosing the most appropriate algorithm for obtaining the optimal model for recognizing fraud, in addition to the Threshold level, we will also take into account the fact that the decision-making logic for some algorithms (for example, a decision tree) can be reproduced, but for some it is not (perceptron). The presence of such a possibility can be critical if it is important to know why the system made a specific decision on a certain precedent.
The best accuracy was shown by the algorithm of a two-class neural network - Two-Class Neural Network (accuracy indicators are shown in the illustration above), followed by an algorithm based on decision trees - Two-Class Boosted Decision Tree.
Publishing a Model as a Web Service
After the model has been obtained that works with the required accuracy, we publish our experiment as a web service. Publishing operation takes place by clicking the Publish Web Service button in Azure ML Studio. The process of creating a web service from an experiment is trivial and I will skip its description.
As a result, Azure ML will deploy a scalable, fault-tolerant (SLA 99.95%) web service. After the service is published, the API help documentation page will become available, which, in addition to a general description of the service, a description of the formats of expected input and output messages, also contains examples of calling a service in C #, Python and R.
The principle of calling a service by a software client can be depicted as follows.
Azure ML services
Connect to Azure ML web service
Let's take the C # example from the API help and change it slightly to invoke the Azure ML web service.
Listing 1. Calling the Azure ML web service
Code:
private async Task<RequestStatistics> InvokePredictorService(TransactionInfo transactionInfo, TransactionStatistics transactionStatistics)
{
Contract.Requires<ArgumentNullException>(transactionInfo != null);
Contract.Requires<ArgumentNullException>(transactionStatistics != null);
var statistics = new RequestStatistics();
var watch = new Stopwatch();
using (var client = new HttpClient())
{
var scoreRequest = new
{
Inputs = new Dictionary<string, StringTable>() {
{
"transactionInfo",
new StringTable()
{
ColumnNames = new []
{
#region Column name list
},
Values = new [,]
{
{
#region Column value list
}
}
}
},
},
GlobalParameters = new Dictionary<string, string>()
};
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", ConfigurationManager.AppSettings["FraudPredictorML:ServiceApiKey"]);
client.BaseAddress = new Uri("https://ussouthcentral.services.azureml.net/workspaces/<workspace_id>/services/<service_id>/execute?api-version=2.0&details=true");
watch.Start();
HttpResponseMessage response = await client.PostAsJsonAsync("", scoreRequest);
if (response.IsSuccessStatusCode)
await response.Content.ReadAsStringAsync();
statistics.TimeToResponse = watch.Elapsed;
statistics.ResponseStatusCode = response.StatusCode;
watch.Stop();
}
return statistics;
}We get the following request / response:
Listing 2.1. Azure ML Web Service Request
Code:
POST https://ussouthcentral.services.azureml.net/workspaces/<workspace_id>/services/<service_id>/execute?api-version=2.0&details=true HTTP/1.1
Authorization: Bearer <api key>
Content-Type: application/json; charset=utf-8
Host: ussouthcentral.services.azureml.net
/* other headers */
{
"Inputs": {
"transactionInfo": {
"ColumnNames": [
"PartitionKey",
"RowKey",
"Timestamp",
"CardId",
"CrmAccountId",
"MCC",
"MerchantId",
"TransactionAmount",
"TransactionCreatedTime",
"TransactionCurrency",
"TransactionId",
"TransactionResult",
"CardExpirationDate",
"CardholderName",
"CrmAccountFullName",
"TransactionRequestHost",
"PartitionKey (2)",
"RowKey (2)",
"Timestamp (2)",
"CardsCountFromThisCrmAccount1D",
"CardsCountFromThisCrmAccount1H",
"CardsCountFromThisCrmAccount1M",
"CardsCountFromThisCrmAccount1S",
"CardsCountFromThisHost1D",
"CrmAccountsCountFromThisCard1D",
"FailedPaymentsCountByThisCard1D",
"SecondsPassedFromPreviousPaymentByThisCard1D",
"PaymentsCountByThisCard1D",
"HostsCountFromThisCard1D",
"HasHumanEmail",
"HasHumanPhone",
"IsCardholderNameIsTheSameAsCrmAccountName",
"IsRequestCountryIsTheSameAsCrmAccountCountry",
"TransactionDayOfWeek",
"TransactionLocalTimeOfDay"
/* values other predictors */
],
"Values": [
[
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"349567471",
"10145",
"32",
"990",
"136.69",
"2015-03-15T20:54:28.6508575Z",
"840",
"f31f64f367644b1cb173a48a34817fbc",
null,
"2015-04-15T23:44:28.6508575+03:00",
"640ab2bae07bedc4c163f679a746f7ab7fb5d1fa",
"640ab2bae07bedc4c163f679a746f7ab7fb5d1fa",
"20.30.30.40",
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"2",
"1",
"0",
"0",
"0",
"0",
"1",
"2",
"0",
"0",
"true",
null,
"true",
"true",
"Monday",
"Morning"
/* other predictor values */
]
]
}
},
"GlobalParameters": { }
}Listing 2.2. Azure ML web service response
Code:
HTTP/1.1 200 OK
Content-Length: 1619
Content-Type: application/json; charset=utf-8
Server: Microsoft-HTTPAPI/2.0
x-ms-request-id: f8cb48b8-6bb5-4813-a8e9-5baffaf49e15
Date: Sun, 15 Mar 2021 20:44:31 GMT
{
"Results": {
"transactionPrediction": {
"type": "table",
"value": {
"ColumnNames": [
"PartitionKey",
"RowKey",
"Timestamp",
"CardId",
"CrmAccountId",
"MCC",
"MerchantId",
"TransactionAmount",
"TransactionCreatedTime",
"TransactionCurrency",
"TransactionId",
/* values other predictors */
"Scored Labels",
"Scored Probabilities"
],
"Values": [
[
"990",
"f31f64f367644b1cb173a48a34817fbc",
"2015-03-15T20:54:28.6508575Z",
"349567471",
"10145",
"32",
"990",
"136.69",
"2015-03-15T20:54:28.6508575Z",
"840",
"f31f64f367644b1cb173a48a34817fbc",
/* other predictor values */
"Success",
"0.779961256980896"
]
]
}
}
}
}Stress Testing
For load testing purposes, we will use the IaaS capabilities of Azure - we will raise a virtual machine (Instance A8: 8x CPU, 56Gb RAM, 40Gbit / s InfiniBand, Windows Server 2012 R2, $ 2.45 / hr) in the same region (US Central South) where our Azure ML web service. Let's run a task for ~ 20K requests on the VM and see the results.
Listing 3. Service client code and tasks
Code:
/// <summary>
/// Entry point
/// </summary>
public void Main()
{
var client = new FraudPredictorMLClient();
RequestsStatistics invokeParallelStatistics = client.InvokeParallel(1024, 22);
LogResult(invokeParallelStatistics);
RequestsStatistics invokeAsyncStatistics = client.InvokeAsync(1024).Result;
LogResult(invokeAsyncStatistics);
}
private static void LogResult(RequestsStatistics statistics)
{
Contract.Requires<ArgumentNullException>(statistics != null);
Func<double, string> format = d => d.ToString("F3");
Log.Info("Results:");
Log.Info("Min: {0} ms", format(statistics.Min));
Log.Info("Average: {0} ms", format(statistics.Average));
Log.Info("Max: {0} ms", format(statistics.Max));
Log.Info("Count of failed requests: {0}", statistics.FailedRequestsCount);
}
/// <summary>
/// Client for FraudPredictorML web-service
/// </summary>
public class FraudPredictorMLClient
{
/// <summary>
/// Async invocation of method
/// </summary>
/// <param name="merchantId">Merchant id</param>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
public async Task<RequestsStatistics> InvokeAsync(int merchantId)
{
Contract.Requires<ArgumentOutOfRangeException>(merchantId > 0);
IEnumerable<TransactionInfo> tis = null; IEnumerable<TransactionStatistics> tss = null;
// upload input data
Parallel.Invoke(
() => tis = new TransactionsInfoRepository().Get(merchantId),
() => tss = new TransactionsStatisticsRepository().Get(merchantId)
);
var inputs = tis
.Join(tss, ti => ti.TransactionId, ts => ts.TransactionId, (ti, ts) => new { TransactionInfo = ti, TransactionStatistics = ts })
.ToList();
// send requests
var statistics = new List<RequestStatistics>(inputs.Count);
foreach (var input in inputs)
{
RequestStatistics stats = await InvokePredictorService(input.TransactionInfo, input.TransactionStatistics).ConfigureAwait(false);
statistics.Add(stats);
}
// return result
return new RequestsStatistics(statistics);
}
/// <summary>
/// Parallel invocation of method (for load testing purposes)
/// </summary>
/// <param name="merchantId">Merchant id</param>
/// <param name="degreeOfParallelism">Count of parallel requests</param>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
/// <exception cref="ArgumentOutOfRangeException"><paramref name="merchantId"/></exception>
public RequestsStatistics InvokeParallel(int merchantId, int degreeOfParallelism)
{
Contract.Requires<ArgumentOutOfRangeException>(merchantId > 0);
Contract.Requires<ArgumentOutOfRangeException>(degreeOfParallelism > 0);
IEnumerable<TransactionInfo> tis = null; IEnumerable<TransactionStatistics> tss = null;
// upload input data
Parallel.Invoke(
() => tis = new TransactionsInfoRepository().Get(merchantId),
() => tss = new TransactionsStatisticsRepository().Get(merchantId)
);
var inputs = tis
.Join(tss, ti => ti.TransactionId, ts => ts.TransactionId, (ti, ts) => new { TransactionInfo = ti, TransactionStatistics = ts })
.ToList();
// send requests
var statistics = new List<RequestStatistics>(inputs.Count);
for (int i = 0; i < inputs.Count; i = i + degreeOfParallelism)
{
var tasks = new List<Task<RequestStatistics>>();
for (int j = i; j < i + degreeOfParallelism; j++)
{
if (inputs.Count <= j) break;
var input = inputs[j];
tasks.Add(InvokePredictorService(input.TransactionInfo, input.TransactionStatistics));
}
Task.WaitAll(tasks.ToArray());
statistics.AddRange(tasks.Select(t => t.Result));
}
// return result
return new RequestsStatistics(statistics);
}
/* other members */
}InvokeParallel () call:
Best response time: 421.683 ms
Worst time: 1355.516 ms
Average time: 652.935 ms
Successful requests: 20061
Failures: 956
InvokeAsync () call:
Best response time: 478.102 ms
Worst time: 1344.348 ms
Average time: 605.911 ms
Number of successful requests: 21017
Number of rejections: 0
Limitations (potential)
At first glance, the bottleneck of the system being developed will be Azure ML. Therefore, it is extremely important to understand the limitations of Azure ML in general and Azure ML Web Services in particular. But on this issue, there is very little, both official documentation and the results obtained from the community.
So the question remains with the throttled policy of the endpoints of the Azure ML web service: it is not clear the maximum value of parallel requests to the Azure ML web service (the figure of 20 concurrent requests per endpoint has been empirically verified), as well as the maximum size of the received message (relevant for batch mode service operation).
Less relevant, but there is a question with the maximum size of the input data (Criteo Labs placed a dataset on 1 TB of data), the maximum number of predictors and use cases that can be sent to the input to the machine learning algorithm in Azure ML.
It is critically important to reduce the response time of the FraudPredictorML web service, as well as the time to retrain the model to minimum values, but so far there is no official recommendation on how this is possible (or even possible).
Recommendations to clients
The anti-fraud service does not restrict clients in any way both in the preliminary verification of payments and in the subsequent interpretation of the prediction results. Preliminary business process-specific checks, as well as the final decision on acceptance / rejection of a payment, are tasks that clearly fall outside the area of responsibility of the anti-fraud service.
Regardless of the client's role - an online store, a payment system or a bank - there are the following recommendations for clients:
- perform a preliminary check of payments, both using technologies accepted in the industry (fingerprint, etc.), and using your own knowledge about the client (order history, etc.);
- interpret the result using the following practice: the probability of fraud is lower than 0.35 - to accept payment without 3D-Secure, the probability is from 0.35 to 0.85 - accept payment with 3DS enabled, the probability of fraud - more refuse;
- choose the levels suggested in the previous paragraph based on your own analytics and review them regularly (minimize lost profits and penalties for fraud).
Recommendations for commentators
Within the framework of this series of articles, we dealt with the problematics of the issue, the legal and technical side of the problem. This is a technical article, it does not pursue the goal of creating a business plan, comparing it with competitors' solutions, calculating the present value of the project. With all these questionsat RBK - not to me, not to this hub, and, there is a suspicion, not even to this site.
Conclusion
In this series, consisting of 4 articles, we conducted an experiment on the design and development of a highly scalable, fault-tolerant, reliable antifraud service operating in near real-time mode, with a REST / JSON API open to external software clients.
The use of machine learning algorithms (decision tree, neural networks) made it possible to create an analytical system capable of self-learning both on the accumulated history and on new payments. Thanks to the use of PaaS / IaaS services, it was possible to reduce the initial financial costs for infrastructure and software to almost zero. The developer has competencies in the subject area, data science, architecture of distributed systems helped to dramatically reduce the number of development team members.
As a result, in less than 60 man-hours and with minimal initial infrastructure costs (<$ 150, which were covered by MSDN subscription), the core of the anti-fraud system was created.
The resulting service, of course, still requires a thorough check (and subsequent correction) of the main modules, more fine-tuning of the work of the classifier (s), the development of a series of auxiliary subsystems, interest and (to be sure) investments. But despite the aforementioned shortcomings, the service is an order of magnitude (and more) more efficient than similar developments in the industry, both in terms of development costs and in terms of the cost of ownership.
